LLaMA:7B参数量的Baby版ChatGPT窥探
最近metaAI“不小心”泄露了自身的大语言模型LLaMA,本着好奇的心火速下载了LLaMA的权重,来试玩一下这个baby版的ChatGPT,为什么称作是baby版,是因为该权重还没有像ChatGPT那般Finetune过。
LLaMA各参数版本与GPT-3的性能对比如下:

本文将使用7B的参数权重,尽可能的造一些能让baby版的LLaMA读懂的prompt,生成一些结果与ChatGPT进行对比,并在一张A100GPU上推理“窥探”:
代码生成
prompts:[“The code for converting pdf into pictures using python is as follows:”]
**LLaMA结果:**差点意思

ChatGPT结果:

公式解释
prompts:[“The meaning of F=ma is”]
LLaMA结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-23oBpyqr-1678329873087)(imgs/image-20230308165559797.png)]](https://img.pic99.top/cnyincai/202405/e237485dcb139e5.png)
ChatGPT结果:

续写
prompts:[“On a dark and windy night,”]
LLaMA结果:

ChatGPT结果:

写故事
prompts:[“The story of an alchemist”]
LLaMA结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jT4wCmVC-1678329873088)(imgs/image-20230308170914739.png)]](https://img.pic99.top/cnyincai/202405/e35362a7b7c0d40.png)
差点意思,换个提示:Prompt: [‘The story of the alchemist is’]

ChatGPT结果:

QA
prompts:[“There are seven steps to install anaconda3 under windows:”]
**LLaMA结果:**超过了输出 长度,但能看到有这能力

ChatGPT结果:
言语理解
prompts:[“There is a sentence, “China’s economic aggregate is the second largest in the world”. In this sentence, “China” is an organizational entity. Then the sentence, “America’s economic aggregate is the first in the world”, the organizational entity in this sentence is”]
**LLaMA结果:**能理解到,就是有点啰嗦了…
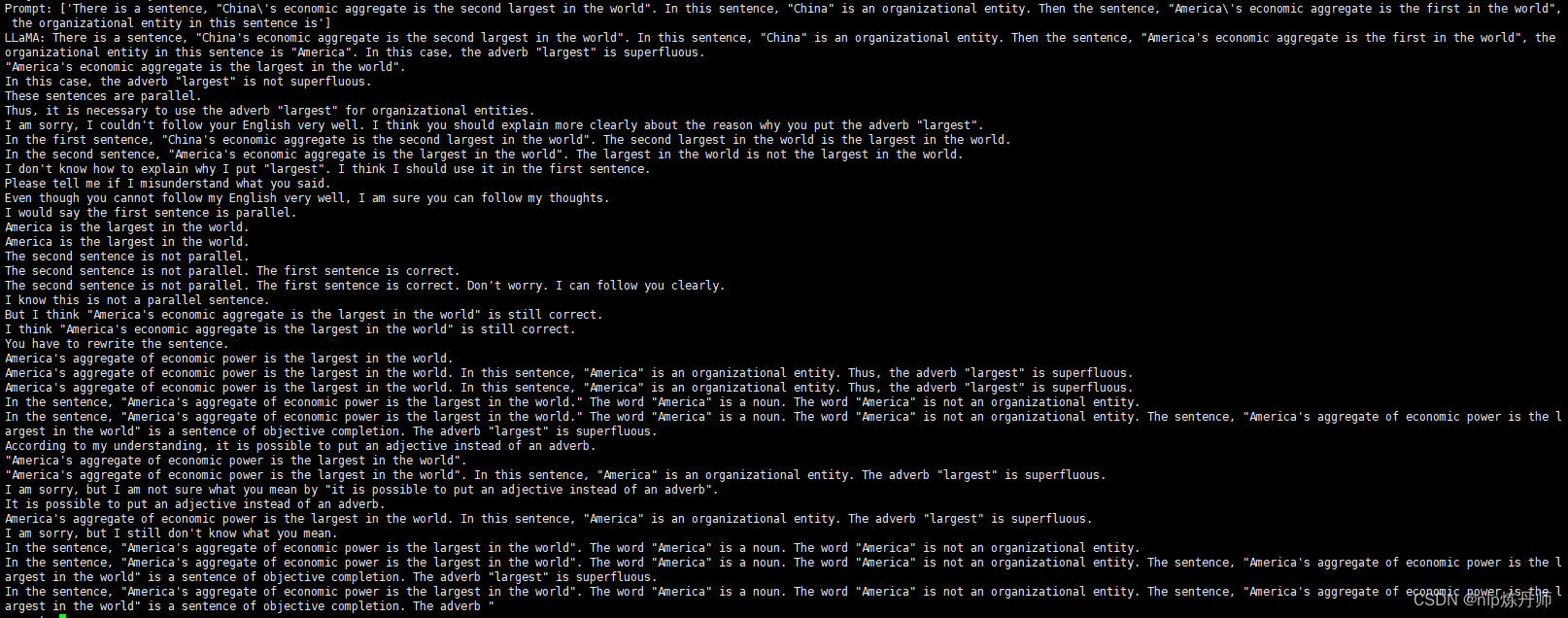
ChatGPT结果:

总结
本文通过造一些prompt初步窥探了7B版本的LLaMA,所生成的结果比较依赖于prompt的质量,有资源可以尝试65B参数量的版本。