网络基础(二)
目录
应用层
再谈 "协议"
协议是一种 "约定". socket api的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?
为什么要转换呢?
如果我们将struct message里面的信息分别作为独立的内容将这个4个信息分别传过去可以吗?
什么是序列化和反序列化?
为什么需要进行序列化和反序列化?
我们之前的tcp,udp通信,有没有进行任何的序列化和反序列化呢?
如何进行序列化和反序列化呢?
网络版计算器
Sock.hpp
CalServer.cc
CalClient.cc
测试结果
存在的问题
json
如何进行序列化和反序列化?
json的使用
序列化
反序列化
我们对计算器进行优化(内置序列化和反序列化)
Protocol.hpp
Makefile
CalServer.cc
CalClient.cc
测试:
对网络计算器的总结
HTTP协议
认识URL
url字段解析
urlencode和urldecode
转义的规则如下
HTTP协议格式
HTTP请求
请求行
请求报头
空行
请求正文
如何理解普通用户的上网行为?
http的响应
状态行
响应报头
空行
响应正文
请求与响应的整体格式
http request和http response 被如何看待?
如何解包和封包呢?
如何分用?
HTTP操作
http中面向字节流读的函数recv
最简单的HTTP服务器
测试
为什么客户端发了多条请求呢?
HTTP请求
这个http的请求和响应为什么都带了版本呢?
对于HTTP请求的报头字段的解释
服务器构建响应
send
Sock.hpp
HTTP.cc
测试
HTTP的请求与响应总结
观察百度的网页
再谈http请求的细节
HTTP请求
理解Content-Length
读取要求
你怎么保证你每次读到的是一个完整的http呢?
假设有正文的话,你如何知道空行之后有多少个字符呢?
如何读到一个完整的http协议?
HTTP响应
HTTP的请求方法
短链接
早期的http1.0为什么用短链接呢?
HTTP的方法
/ (根目录)
实验
响应报头部分
响应正文
完整代码
测试:
验证GET和POST方法
GET方法
html的表单
制作表单
POST方法
GET和POST的区别
通过抓包观察GET与POST
抓包的原理
fiddler查看POST 方法
fiddler查看GET
GET和PSOT
概念问题
区别
如何选择
所谓的文本分析
HTTP常见的状态码
具有指导意义的状态码
404的错误属于客户端问题,还是服务器问题?
服务器的问题有哪些呢?
3开头的状态码
重定向是什么?
什么叫做永久重定向,什么叫做临时重定向?
模拟重定向
测试302,临时重定向
永久重定向遗留的问题
再谈HTTP常见Header
长连接与短连接
短连接
长连接
Connection
背景引入
问题引入
Cookie
对我们来讲,http是不记录上下文的是无状态的,那网站是如何认识我的呢?
会话与会话管理
session
为什么私密信息会被盗取呢?
session处理策略
再谈http无状态
为什么网站需要认证用户,也就是为什么登录这个网站的时候它需要永久的认识用户呢?
HTTPS
背景认识一
背景认识二(数据的加密方式)
1.对称加密
2.非对称加密
背景认识三
假设现在有一篇论文,那么如何防止文本中的内容被篡改?以及识别到是否被篡改?
我是一个通信端,我现在要发送这段文本,我怎么保证这段文本没有被篡改?
校验
https是如何通信的呢
如何选择加密算法
方案一
方案二
对称加密
非对称加密
两对非对称秘钥的问题
实际中的加密方法
什么叫做安全
中间人
那么在服务端把公钥给客户端的时候,可不可能出现问题呢?
证书
证书是什么
CA机构
创建证书
有了证书后,请求该怎么做呢?
编辑数字签名中间人改不了吗?
如果中间人也是一个合法的服务方呢?
客户端是如何知道CA机构的公钥信息呢?
传输层
再谈端口号
端口号范围划分
认识知名端口号(Well-Know Port Number)
两个问题
pidof
netstat
UDP协议
UDP协议端格式
对于16位UDP长度的理解
UDP如何做到封装和解包的?
UDP如何做到向上交付(分用问题)?
我们写代码的时候为什么需要绑定端口号?
端口号为什么是16位?
Linux内核是C语言写的,请问如何看待udp报头?
UDP的特点
面向数据报
UDP的缓冲区
UDP全双工
什么叫做一个协议通信时全双工呢?
UDP使用注意事项
基于UDP的应用层协议
TCP协议
TCP协议段格式
TCP如何做到封装和解包的?
TCP如何做到向上交付的(分用问题)?
确认应答(ACK)机制
TCP常规可靠性-确认应答的工作方式
确认应答
如何保证按序到达呢?
如何确认信息和发送信息的对应关系呢?
为什么一个报文里面,既有序号,又有确认序号?
16位窗口大小
TCP为什么要弄两个缓冲区?
16位窗口大小
server有接受缓冲区,客户端给server发消息,server是会进行应答的,其中server如何让客户端慢一点呢?
我如何把我自己的接受缓冲区中剩余空间的大小通告给你呢?
如何通过端口号找到目标进程?
系统中存在很多文件,为什么你读取文件的时候,这个文件读取到系统之后是读给你的?
6个标记位
为什么要建立连接呢?
如何建立连接呢?
作为一个server,在任何时刻可能有成百上千个client都向server发消息。server首先面临的是,面对大量的TCP报文,如何区分各个报文的类别?
ACK标记
SYN标记
server端可能会收到一个连接建立的请求,请求虽然叫请求但是它也是数据,所以也要进行交换,server端如何区分发来的报文是请求呢?
建立连接,三次握手的过程
3次握手的目的就是建立连接,我们理解下什么叫是连接?
为什么是3次握手呢?
RST标记位
PSH标记位
如何理解这个让上层尽快将数据取走,是怎么个取法?
URG
16位紧急指针是什么呢?
这个带外数据有什么用呢?
FIN标记位
四次挥手
如何理解序号
超时重传机制
超时时间间隔应该是多长?
当你把报文发出去了,发送方没有收到确认ACK,接收方是一定没有收到对应的报文数据吗?
我们怎么保证对方收到的数据不是重复的呢?
那么, 如果超时的时间如何确定?
连接管理机制
为什么是三次握手?
为什么4,5,6次握手不行呢?
为什么1,2次握手不行呢?
3次握手就可以预防了洪水问题了吗?
半连接
为什么是四次挥手?
四次挥手的状态变化
理解TIME_WAIT状态
验证主动断开连接的一方要进入TIME_WAIT
为什么会要有TIME_WAIT,TIME_WAIT通常是多长?
为什是TIME_WAIT时间一般等于2倍MSL呢?
为什么会断开服务器后立即重启会bind error?
如何解决bind error?
服务器无法立即重启,会有什么危害?
CLOSE_WAIT状态
验证CLOSE_WAIT状态
CLOSE_WAIT给我们带来的启示?
滑动窗口
如果我们运行一个主机向另一个主机发送大量数据时,那么一次给对方多少呢?
滑动窗口在哪里,是什么?
滑动窗口有没有可能缩小呢?
滑动窗口有没有可能扩大呢(向右移动)?
滑动窗口可能向左滑动吗?
如果出现了丢包, 如何进行重传?
滑动窗口发送1001~5001这么多报文,最后ACK确认,先确认的是1001~2001,后面的2001~3001也会陆陆续续确认,但是如果中间的ACK丢了呢?
如果此时我给对方发消息还是1001~5001,1001~2001数据对方收到了但是2001~3001数据丢了,因为对方收到了5001,可是2001~3001的数据没了,此时对方给我的ACK是什么呢?
再次理解滑动缓冲区
再次总结下丢包的两种情况
超时重传 vs 快重传
实际上TCP里这两种重传机制都是存在的,为什么超时重传还存在呢?
流量控制
什么时候发送方就知道了接收方的接收能力?
如果我的接收缓冲区的窗口大小为0怎么办?
此时发送方就不发数据了,就停下来了,因为我们有流量控制。那么发送方什么时候再向接收方发消息呢?
一旦发送方给接收方发了消息,接收方要不要应答呢?
总结
拥塞控制
背景引入
拥塞窗口
之前不是说滑动窗口是我向网络里塞数据,一次可以塞多少数据,而暂时可以不用应答的这样的一个范围吗?滑动窗口不是说好的是由对方的窗口大小也就是接收能力决定的吗?
网络拥塞了,TCP该怎么办?
为什么慢启动前期使用指数增长呢?
什么叫慢启动呢?
那网络的拥塞窗口变来变去的是不是会造成网络的数据量一会升,一会降?
延迟应答
那么所有的包都可以延迟应答么?
假设今天适用于延迟应答,延迟应答有哪些策略呢?
捎带应答
重新认识3次握手
面向字节流
什么叫做字节流?
什么叫做流呢?
回忆http
为什么打开文件叫做文件流?
粘包问题
TCP异常情况
比如进程终止了,曾经建立好的连接会怎么样呢?
如果我在电脑上建立好大量的连接,突然我的机器直接重启了会怎么样呢?
如果机器掉电或者网络断开了会怎么样呢?
TCP小结
基于TCP应用层协议
TCP/UDP对比
看直播延迟是怎么做到的呢?
为什么要这么干呢?
网络通信都不允许丢包吗?
用UDP实现可靠传输
TCP 相关实验
理解 listen 的第二个参数
Sock.hpp
Http.cc
为什么要进行+1呢?
半连接队列是如何移到全连接队列的?
那我作为一个服务器,有人不攻击我的全连接队列,而是攻击我的半连接队列怎么办?
为什么要维护队列?为什么这个队列不能太长?为什么这个队列不能没有?
为什么要维护门口的桌椅板凳让客人可以等待?
应用层
我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层.再谈 "协议"
协议是一种 "约定". socket api的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?

这就是曾经我们在写C/C++定义出来的对象,我们要把它发出。我们要把数据发送到网络当中,肯定不是直接就把这样的结构化数据放到网络里传过去让对方收到。因为这些消息里,大家的大小,长度,都是变长的,都是不一样的,所以我们在实际发给对方的时候,是不方便统一发送的,那我们实际上就需要把这里的各种结构化信息,我们要把它转化成一个长的“字符串”(实际上应该转化成一个长的字节流或者数据包发出去)
为什么要转换呢?
我们的message是一个结构体,之前我们存在一个概念是结构体的内存对齐,那么如果我是一个message,那么将来你接收的时候,也一定是struct message。但是发送方和接收方的message的大小不一定一样,其中双方里面字段开辟的长度也都不一定一样。所以直接把信息传过去这种做法是不正确的。我们需要将其转化成一个长字符串。
如果我们将struct message里面的信息分别作为独立的内容将这个4个信息分别传过去可以吗?
从技术实现上,如果你想分别传过去,这个时候每一个信息就是一个独立的信息,整体就不是结构化数据了,因为这样成本太高了,假如有成百上千的人给我们这样单独的一条一条发信息,那么我们最后还得组合区分,哪几条是组合在一起的。所以我们一般不会这么做,我们需要将它转换成对应的长字符串,也就是把它打包。
什么是序列化和反序列化?
所以我们要把这种结构化的数据,转化成某种长字符串的信息,传递给对方,对方在根据这里的长字符串,以此定义一个message对象,然后将数据由一个字符串转化成一个结构化的数据。其中我们把从结构化数据转换成长字符串的过程我们就叫做序列化的过程。当我们把长字符串转化上来的时候 ,新的结构体里面就会有各种信息,这些信息我们再由我们的分析算法,把字符串里面的内容在一个个的分析出来,然后填入到结构体当中,在形成一个新的结构化的数据,这个过程我们称之为反序列化的过程。
 说白了就是我们要将结构化的数据转换成字符串,然后再将字符串反序列化变成结构化的数据,这是我们在网络通信里必须得做的。
说白了就是我们要将结构化的数据转换成字符串,然后再将字符串反序列化变成结构化的数据,这是我们在网络通信里必须得做的。
为什么需要进行序列化和反序列化?
答:1.这种结构化的数据是不便于网络传输的。结构化的数据在网络上不好传输,但我把整个对象转成一个字符串,字符串里面包含了你的每一个字段的信息,到了对方以后,我再把字段的信息一个个提出来形成一个对象,整个就是序列化和返反序列化的过程。字符串便于网络传输。归根结底就是为了应用层网络通信的方便。
2.序列和反序列化不是目的,在我们两个人的上层,还有其他应用,比如,图形界面显示要拿你的昵称,头像,消息,时间,因为是结构化的数据,所以我们可以用类名+方法就把他的属性拿到了。如果我们在对端,只拿这个字符串去用,上层就需要把这个字符串解析的工作全部由我们自己再次完成,这太麻烦了,所以我们先反序列化得到结构化的数据,就方便我们一次一次的向上层去拿。总结:为了方便上层进行使用内部成员,将应用和网络进行了解耦!应用压根不关心网络发送,作为应用我只关心,结构体数据里的成员,结构化的数据怎么在网络里传输,如何序列化和反序列化,应用层压根不关心。这就完成了解耦。
我们之前的tcp,udp通信,有没有进行任何的序列化和反序列化呢?
压根就没有,原因就是我们没有应用场景,我们不知道我们要干什么,我们就不知道应用场景是什么,就没办法定制序列和反序列化的一些结构化数据,也就不需要字符串的序列和反序列化的过程,所以之前我们并没有。
这里结构化的数据本质就是协议的表现,就好比QQ软件就知道昵称对应的信息是什么样子的,头像是连接还是文件,时间是以什么格式展示的...这就叫做协议
如何进行序列化和反序列化呢?
像xml,json,protobuff就是专门用来负责做序列化和反序列化这样的过程的。
网络版计算器
目的: 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端.
约定方案一:
- 客户端发送一个形如"1+1"的字符串;
- 这个字符串中有两个操作数, 都是整形;
- 两个数字之间会有一个字符是运算符, 运算符只能是 + ;
- 数字和运算符之间没有空格;
- ...
这就是约定,当客户端发送一个数据的时候,服务端立马就意识到,它一定有操作数和操作符,而且操作符左右两侧一定是数据没有空格,所以服务端收到1+1这样的字符串,就需要根据操作符把1和1解开。
我们这样去做的伪代码
这个过程是比较麻烦的,这个序列化和反序列化动作都是由我们自己做的

约定方案二:
- 定义结构体来表示我们需要交互的信息; (结构化的数据)
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
- 这个过程叫做 "序列化" 和 "反序列化"
这种方式,发的时候发了一个结构体,收的时候也收了一个结构体,因为他俩成员一样,一旦收到内容后,就直接可以在上层拿到内容了。但是这种方式存在问题,因为这种方式是语言的特性做了序列化和反序列化,但是不太推荐。

我们接下来,就实现一个网络版本的计算器,我们利用约定方案二进行实现
Protocol.hpp
因为存在10/0或者10%0这样的错误操作,所以我们需要一个code代表运算完毕的状态。换言之,我将来想要拿到退出结果的时候,我们要做的第一件事情是先检查code,只有code是0的时候,result才有意义,否则result是没有意义的。
以上就定制好了我们的协议(双方通信时采用的数据格式),我们发的一定是request这种数据格式,收的一定是response这种格式,上面的这两种数据就叫做结构化数据,我们发的时候可以把request定义的对象直接发过去,但是这样发存在问题,客户端和服务器对于结构体的大小可能不一样,而且不同平台的大小也不一样,eg:这里的结构体里面用的是整形,有一天你将客户端发出去了,服务器升级了,一个int占64个比特位,这样的话客户端发过来的数据结构体大小就匹配不上了,就出问题了。所以我们需要序列化和反序列化的。
做一个套接字接口的封装
Sock.hpp
#pragma once#include
#include
#include
#include
#include
#include
#include
#includeusing namespace std;
class Sock
{
public:static int Socket(){int sock = socket(AF_INET, SOCK_STREAM, 0);if (sock < 0){cerr << "socket error" << endl;exit(2); //直接终止进程}return sock;}static void Bind(int sock,uint16_t port){struct sockaddr_in local;local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0){cerr<<"bind error!"<= 0){return fd;}return -1;}static void Connect(int sock, std::string ip, uint16_t port){struct sockaddr_in server;memset(&server, 0, sizeof(server));server.sin_family = AF_INET;server.sin_port = htons(port);server.sin_addr.s_addr = inet_addr(ip.c_str());if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0){cout << "Connect Success!" << endl;}else{cout << "Connect Failed!" << endl;exit(5);}}
}; CalServer.cc
#include"Protocol.hpp"
#include"Sock.hpp"
#include
static void Usage(string proc)
{cout << "Usage: " << proc << "port" << endl;exit(1);
}void* HandlerRequest(void* args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());//version1 原生方法,没有明显的序列化和反序列化的过程//业务逻辑,做一个短服务 request -> 分析处理 -> 构建response ->sent(response) ->close(sock)//1.读取请求request_t req;ssize_t s = read(sock, &req, sizeof(req));if (s == sizeof(req)){//读取到了完整的请求,待定//req.x,req.y,req.op// 2.分析请求 && 3.计算结果response_t resp = {0, 0}; //响应,默认设置0,0// 4.构建响应,并进行返回switch (req.op){case '+':resp.result = req.x + req.y;break;case '-':resp.result = req.x - req.y;break;case '*':resp.result = req.x * req.y;break;case '/':if (req.y == 0){resp.code = -1; //代表除0}else{resp.result = req.x / req.y;}break;case '%':if (req.y == 0){resp.code = -2; //代表模0}else{resp.result = req.x % req.y;}break;default:resp.code = -3; //代表请求方法异常break;}cout << "request: " << req.x << req.op << req.y << endl; write(sock, &resp, sizeof(resp));cout << "服务结束" << endl;}//5.关闭连接close(sock);
}// ./CalServer port
int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){cout << "get a new client..." << endl;int *pram = new int(sock);pthread_t tid;pthread_create(&tid, nullptr, HandlerRequest, pram);}}return 0;
} CalClient.cc
#include "Protocol.hpp"
#include "Sock.hpp"void Usage(string proc)
{cout << "Usage: " << proc << " server_ip server_port " << endl;
}//./CalClient server_ip server_port
int main(int argc, char *argv[])
{if (argc != 3){Usage(argv[0]);exit(1);}int sock = Sock::Socket();Sock::Connect(sock, argv[1], atoi(argv[2]));//业务逻辑request_t req;memset(&req, 0, sizeof(req));cout << "Please Enter Date One# ";cin >> req.x;cout << "Please Enter Date Two# ";cin >> req.y;cout << "Please Enter operator# ";cin >> req.op;ssize_t s = write(sock, &req, sizeof(req));response_t resp;s = read(sock, &resp, sizeof(resp));if (s == sizeof(resp)){cout << "code[0:success]: " << resp.code << endl;cout << "result: " << resp.result << endl;}return 0;
}测试结果

ps:如果你想改成长服务,你就需要在服务端,把刚刚做的那一批请求包裹在死循环中就可以了。
服务器怎么知道是x op y 呢?服务器怎么知道,op的+,-,*,/,%是什么含义呢?服务器怎么知道,code为0,1,2,3的意思呢?我怎么知道,客户端和服务器又怎么知道?
这就叫做约定,所以我们刚刚用结构化的数据,又结合我们自己的约定,然后我们就定义了一个简单的协议,这就叫做约定。
存在的问题
我们今天的协议逻辑上是没有问题的,不过如果客户和服务器使用这样的原生结构体的方式,发送二进制数据的内容(一个结构化的数据发过去到对方),事实证明这样是行的。但是能起效果,仅仅会满足90% 的情况。当我们正常通信的时候,客户端和服务器如果软件版本是迭代的,那么如果现在你有一个老的客户端,你用这样的方式,比如以前结构体的内存对齐方式,结构体的大小,使用的是标准A,后来经过5年,10年的发展,计算机不断进步,内存对齐的方式变得和之前不一样了,客户端已经发给客户了,那么作为客户来讲,客户就喜欢老东西,就喜欢老的客户端,但你的服务器早就升级成了很高很高的版本,那么当客户端发来消息的时候,那么如果哪怕有一个字节发生变化,那你的协议就跑不起来了。所以这样的方案并不好,而且并不适合后序大型的业务处理。在应用层,这种结构化的数据直接发,虽然在我们目前看来可行,但我们不建议,因为我们少了序列化和反序列化的步骤。
json
如何进行序列化和反序列化?
jsoncpp是C++当中使用频率很高的一个进行序列化和反序列化的一个组件。
云服务器通过该条指令进行安装
sudo yum install -y jsoncpp-devel这条命令就是安装我们的开发包。

安装完毕。


这就是我们安装的json,安装一个库说白了就是安装一堆对应头文件,和它对应的一堆库,我们就可以直接使用这个库了。
json的使用
序列化
#include
#include
#includetypedef struct request
{int x;int y;char op;
}request_t;int main()
{request_t req = {10, 20, '*'};//进行序列化Json::Value root; //可以承装任何对象,json是一种kv式的序列化方案root["datax"] = req.x;root["datay"] = req.y;root["operator"] = req.op;//FastWriter, StyledWriterJson::StyledWriter writer;std::string json_string = writer.write(root);std::cout << json_string << std::endl;return 0;
} 执行结果:编译的时候要指明链接的动态库

此时我们就形成了一个序列化的结果,有人说这不还是结构化的数据吗,事实上已经完成不一样了,我们自己写的结构体是一个二进制的数据,也就是内存是什么样子,网络里就是什么样子,但我们的运行结果是一个字符串的数据。
我们将StyledWriter改为FastWriter,我们再次运行。

 这个时候得到的就像一个字符串了(实际上人家就是一个字符串),其中每一个字段,datax就是10,datay是20,operator是42(*的ASCII是42),这就是一种kv的方案。这就是序列化的过程,我们通过网络发送的不是我们自己定义的结构体,发送的是我们的运行结果。
这个时候得到的就像一个字符串了(实际上人家就是一个字符串),其中每一个字段,datax就是10,datay是20,operator是42(*的ASCII是42),这就是一种kv的方案。这就是序列化的过程,我们通过网络发送的不是我们自己定义的结构体,发送的是我们的运行结果。
反序列化
序列化是把结构化的数据转换成一个字符串,反序列化的目的就是把一个字符串转换成一个结构化的数据。
运行结果:


ps:关于R
新的C++标准可以在代码里嵌入一段原始字符串,该原始字符串不作任何转义,所见即所得,这个特性对于编写代码时要输入多行字符串,或者含引号的字符串提供了巨大方便。
先介绍特性如下:
原始字符串的开始符号 :R"( , 原始字符串的结束符号:)"。R" 与 ( 之间可以插入其它任意字符串。
eg2:
int main()
{//反序列化std::string json_string = R"({ "datax":10, "datay":20,"operator":42 })";// 这个R就是代表原生字符串,把里面的内容统一当做最原始的内容来看。 Json::Reader reader;Json::Value root;reader.parse(json_string, root);request_t req;req.x = root["datax"].asInt();req.y = root["datay"].asInt();req.op = (char)root["operator"].asInt();std::cout << req.x << " " << req.op << " " << req.y << std::endl;
}执行结果:

我们对计算器进行优化(内置序列化和反序列化)
Protocol.hpp
//这个头文件就是客户端和服务器通信时的协议内容,也就是我们自己需要定制协议了。
#pragma once#include
#include
#includeusing namespace std;//定制协议的过程,目前就是定制结构化数据的过程
//请求格式
//我们自己定义的协议,client&&server都必须遵守!这就叫做自定义协议。
typedef struct request
{int x;int y;char op; //"+,-,*,/,%"
}request_t;//响应格式
typedef struct response
{int code; //server运算完毕的计算状态:code(0:success) code(-1:div 0)...int result; //计算结果,能否区分是正常的计算结果,还是异常的退出结果
}response_t;//序列化 request_t -> string
std::string SerializeRequest(const request_t &req)
{Json::Value root; //可以承装任何对象,json是一种kv式的序列化方案root["datax"] = req.x;root["datay"] = req.y;root["operator"] = req.op;// FastWriter, StyledWriterJson::FastWriter writer;std::string json_string = writer.write(root);return json_string;
}//反序列化 string -> request_t
void DeserializeRequest(const std::string &json_string,request_t &out)
{Json::Reader reader;Json::Value root;reader.parse(json_string, root); out.x = root["datax"].asInt();out.y = root["datay"].asInt();out.op = (char)root["operator"].asInt();}std::string SerializeResponse(const response_t &resp)
{Json::Value root;root["code"] = resp.code;root["result"] = resp.result;Json::FastWriter writer;std::string res = writer.write(root);return res;
}void DeserializeRequest(const std::string &json_string, response_t &out)
{Json::Reader reader;Json::Value root;reader.parse(json_string, root);out.code = root["code"].asInt();out.result = root["result"].asInt();
} Makefile
.PHONY:allall: CalClient CalServerCalClient:CalClient.cc g++ -o $@ $^ -std=c++11 -ljsoncppCalServer:CalServer.cc g++ -o $@ $^ -std=c++11 -lpthread -ljsoncpp.PHONY:clean
clean:rm -rf CalClient CalServerCalServer.cc
#include "Protocol.hpp"
#include "Sock.hpp"
#include
static void Usage(string proc)
{cout << "Usage: " << proc << "port" << endl;exit(1);
}void *HandlerRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());// version1 原生方法,没有明显的序列化和反序列化的过程//业务逻辑,做一个短服务 request -> 分析处理 -> 构建response ->sent(response) ->close(sock)// 1.读取请求char buffer[1024];request_t req;ssize_t s = read(sock, buffer, sizeof(buffer) - 1); //读到buffer里面if (s > 0){buffer[s] = 0;cout << "get a new request: " << buffer << std::endl; //看到反序列化之前的结果std::string str = buffer;DeserializeRequest(str, req); //反序列化请求//读取到了完整的请求,待定// req.x,req.y,req.op// 2.分析请求 && 3.计算结果response_t resp = {0, 0}; //响应,默认设置0,0// 4.构建响应,并进行返回switch (req.op){case '+':resp.result = req.x + req.y;break;case '-':resp.result = req.x - req.y;break;case '*':resp.result = req.x * req.y;break;case '/':if (req.y == 0){resp.code = -1; //代表除0}else{resp.result = req.x / req.y;}break;case '%':if (req.y == 0){resp.code = -2; //代表模0}else{resp.result = req.x % req.y;}break;default:resp.code = -3; //代表请求方法异常break;}cout << "request: " << req.x << req.op << req.y << endl;// write(sock, &resp, sizeof(resp)); //这次就不能直接写入了,你得先序列化std::string send_string =SerializeResponse(resp); //序列化之后的字符串write(sock, send_string.c_str(), send_string.size());cout << "服务结束" << send_string << endl;}// 5.关闭连接close(sock);
}// ./CalServer port
int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for (;;) //创建线程完成,服务器就周而复始的运行,每来一个请求,它就创建线程,分离现场,然后进行业务处理{int sock = Sock::Accept(listen_sock);if (sock > 0){cout << "get a new client..." << endl;int *pram = new int(sock);pthread_t tid;pthread_create(&tid, nullptr, HandlerRequest, pram);}}return 0;
} CalClient.cc
#include "Protocol.hpp"
#include "Sock.hpp"void Usage(string proc)
{cout << "Usage: " << proc << " server_ip server_port " << endl;
}//./CalClient server_ip server_port
int main(int argc, char *argv[])
{if (argc != 3){Usage(argv[0]);exit(1);}int sock = Sock::Socket();Sock::Connect(sock, argv[1], atoi(argv[2]));//业务逻辑request_t req;memset(&req, 0, sizeof(req));cout << "Please Enter Date One# ";cin >> req.x;cout << "Please Enter Date Two# ";cin >> req.y;cout << "Please Enter operator# ";cin >> req.op;std::string json_string = SerializeRequest(req);ssize_t s = write(sock, json_string.c_str(), json_string.size());char buffer[1024];s = read(sock,buffer,sizeof(buffer)-1);if(s > 0){response_t resp;buffer[s] = 0;std::string str = buffer;DeserializeRequest(str,resp);cout << "code[0:success]: " << resp.code << endl;cout << "result: " << resp.result << endl;}// response_t resp;// s = read(sock, &resp, sizeof(resp));// if (s == sizeof(resp))// {// cout << "code[0:success]: " << resp.code << endl;// cout << "result: " << resp.result << endl;// }return 0;
}在客户端,我们输入了一下数据,然后把构建的请求序列化成字符串,然后就发字符串,发送字符串后,对端收到了,然后就响应,响应后我们就读,读的时候读到的一定是响应字符串,然后我们再对响应字符串进行反序列化,反序列化到response,然后就拿到了response的结果。对于server来讲,就是先进行读取,读取到的内容一定是序列化后的请求,然后我们先对请求进行反序列化,然后得到对应的结果并进行分析,分析完后得到响应,响应得到之后,再对响应进行序列化,然后把它写回去。所以我们就在代码中植入了序列化和反序列化的过程。
测试:

这就是序列化和反序列化,我们的最终目的是让网络程序在通信的时候,我们不想让他们直接传递结构化的数据,而是让他们进行互相发送字符串(方便我们后序做调整)。
对网络计算器的总结
我们刚刚写的cs模式的在线版本计算器本质就是一个应用层网络服务,我们的客户端用的是我们对应的linux的客服端,服务器是我们自己写的服务器。
我们所做的工作 :
1.基本通信代码是自己写的(一堆socket);
2.序列和反序列化是我们用组件完成的;
3.业务逻辑是我们自己定的;
4.请求,结果格式,code含义等约定是我们自己做的!
这就叫做我们完成了一个自定义的应用层网络服务。
结合上述,我们在看看OSI的七层协议

OSI和TCP/IP的差别无非就是上三层,TCP/IP上三层就叫做应用层。会话层就对应了我们做的工作1,让我们能进行正常的网络通信。表示层对应了工作2。应用层对应我们的工作3,4。OSI考虑的就是这个点,可是实际做下来后我们发现,这三层很多都是我们写的,甚至是用别人的组件写的。OSI制定的这三层是不可能完成独立开的,也不能写到内核当中,所以我们就把它三个在TCP/IP里放到应用层。说白了就是上层应用层我不写了你自己实现吧。所以就有了基本套接字,序列化和反序列化的基本组件,然后还有特定应用场景的各种协议的出现。
HTTP协议
虽然我们说, 应用层协议是我们程序猿自己定的. 但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议) 就是其中之一.
http协议,本质上,在定位上和我们刚刚写的网络计算器,没有区别,都是应用层协议。
http的网络通信,序列化和反序列化,协议细节,都是http协议内部需要自己实现的。
认识URL
平时我们俗称的 "网址" 其实就是说的 URL.网址是定位网络资源的一种方式。 我们请求的图片,html,css,js,视频,音频,标签,文档,等这些我们都称之为资源。服务器后台使用linux做的。目前我们可以用ip+port唯一的确定一个进程。但是我们无法唯一的确认一个资源!公网IP地址是唯一确定一台主机的,而我们所谓的网络“资源”,都一定是存在与网络中的一台linux机器上!linux或者传统的操作系统,保存资源的方式,都是以文件的方式保存的。 eg:你今天刷的抖音,在抖音的服务器上一定是一个个的短视频,今天刷的视频,音频看的文档查看的网页全部是在linux当中以文件的方式存的。但linux系统,标识一个唯一资源的方式,我们通过路径进行! 所以,IP+linux路径就可以唯一的确定一个网络资源!!! ip通常是以域名的方式呈现的。路径可以通过目录名+分隔符确认。
URL全称Uniform Resource Location,译为统一资源定位符。它就是通过网址确认哪一个资源在哪一个服务器上。 eg:
url字段解析
https:就是请求该资源的方法,说白了就是使用的协议 。
所以一个基本的URL构成就是通过协议,域名+资源路径可能还会带参,这样的方式去构成的URL。URL存在的意义叫做确认全网中唯一的一个资源。
urlencode和urldecode
像 /, ?, : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现. 比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.eg: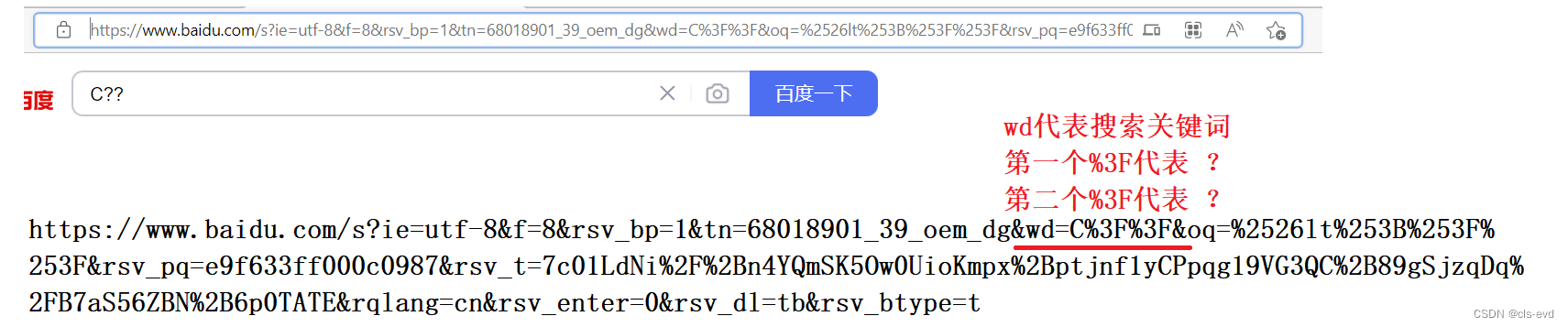

说明我们在URL处理的时候,有些特殊符号是需要被特殊处理的,其中我们把像+,?这些在URL中不能直接出现的符号,由原始的字面值的样子,转化成这种16进制方案,我们称之为urlencode.叫做对字符进行转码。
将C??转化成C%3F%3F,这种样子,我们称之为encode(编码)。
将C%3F%3F转化成C??我们叫做decode(解码)。编码和解码是由浏览器自动帮我们编码,服务器收到之后可能要自己解码,但是我们一般不自己做。
这样处理的根本原因就是它其实不想让这些特殊字符在URL中出现,而影响URL本身的合理性。
转义的规则如下
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY 格式 eg:
HTTP协议格式
简化对请求和响应的认识
无论是请求还是响应,基本上http都是按照行(\n)为单位进行构建请求或者响应的! 无论是请求还是响应,几乎都是由3或者4部分组成。
HTTP请求
http request的格式

http的请求的所有内容都是字符串(传视频,音频可能有二进制,但在它的报头里面我们不考虑)
请求行
请求行一般分为三部分:
请求方法;
URL(请求的资源定位服务);
http version(http协议的版本);
常见的方法比如get方法,URL一般是去掉域名之后的内容(也就是你要访问的网络的一个路径资源),http version也是一个字符串。
eg:http / 1.1。这三部分都已字符串的形式构成一个请求行,这个请求行中间以空格作为分隔符,分成三个区域,最后以\n结束。
请求报头
第二大块我们称之为请求抱头,这里画这么大仅仅是因为这里有多个请求抱头,实际上每个请求抱头依旧是以行为单位进行陈列的,构建成多行内容。每一行都是以key:value的方式呈现的。它的请求抱头是由一个一个的kv形式的属性构成。每一个属性的结束符都是\n。站在http服务器读取的时候,这部分全部是一行内容。
空行
第三部分是空行
请求正文
第四部分是请求正文(如果有的话)常见的请求正文主要是用户提交的数据。
如何理解普通用户的上网行为?
我们这个答案是简洁版本。仅仅分为两步
1.从目标服务器拿到你要的资源。
2.向目标服务器上传你的数据。
我们现在所有上网行为仅仅分为这两步。 eg:你平时刷抖音,抖音的视频可不是在你的手机上的,而是在服务器上,通过网络传的,所以那些资源是在服务器上的。你平时用的淘宝,京东,只要你是你看到的东西,基本是从服务器拿下来的。 比如我们进行登录,注册,支付,下单,再比如上传一个抖音,发朋友圈,这全部都叫做上传一个数据。 我们所有的上网行为无外乎这两种。这个行为对应到计算机当中就是IO的过程。而且人的所有上网行为本质都是进程间通信,进行间通信的过程(你给我发,我给你发,对我来讲就是IO)。 所有用户提交的数据,比如说是你要进行登录,注册...这样的信息,包括你上传的视频,音频都是在正文部分。
综上就是http的请求内容。
http的响应
http的响应的构成和请求在宏观上的构成是一毛一样的,它也是由三部分构成。

状态行
状态行也由三部分构成:
http version的版本;
状态码;
状态码描述;
http version比较常见的也是http/1.1 。状态码,最常见的一个就是404,404就是资源找不到,我怎么知道404是什么含义呢?所以404的状态码描述就叫做not found,表示你的资源找不到。
响应报头
同请求报头
空行
整行就是一个空行
响应正文
响应正文:比如你今天要进行数据请求的时候,你要进行登录,最后登录成功的时候,我要给你响应的时候,返回的肯定是登录成功之后我的网站的首页。所以这个响应里面经常是html,css,js,音乐,视频,图片等这些就叫做响应正文。
请求与响应的整体格式

思考:无论请求还是响应最终所有的内容都是以行呈现的,http也是一个完整的协议。上面的两部分是服务器或者浏览器关心的,下面正文部分是人关心的。

我们需要讨论的问题
1.http如何解包,如何分用,如何封装?
2.http请求或者响应,是被如何读取的?
3.http请求是如何被发送的?
2,3结合就是一个问题,http request和http response 被如何看待?
http request和http response 被如何看待?
我们可以将请求和响应整体看做一个非常大的字符串!!!
 所以对于http来讲,但是http是由很多行构成的,看起来我们需要一行一行进行发送,但是实际上我们看他的时候就是一个长字符串,它只是文本格式是一行一行的。一旦它被看做一个大的字符串,那么它的读取和发送都是按照字符串进行读取和发送的。换句话说,越靠近头部的地方一定是越先被发送的,越靠近尾部的地方,越后被发送或者接受。
所以对于http来讲,但是http是由很多行构成的,看起来我们需要一行一行进行发送,但是实际上我们看他的时候就是一个长字符串,它只是文本格式是一行一行的。一旦它被看做一个大的字符串,那么它的读取和发送都是按照字符串进行读取和发送的。换句话说,越靠近头部的地方一定是越先被发送的,越靠近尾部的地方,越后被发送或者接受。
如何解包和封包呢?
在众多行中出现了一个空行,空行是一个特殊字符(空行什么都不写换一行,结束时\n再换一行),用空行可以做到将长字符串一切为二,这个大字符串以空格为分割符将它分为前半部分和后半部分。所以当我们解包一个http的时候,我们按行进行读,只要我们读到的一行内容是空行,我们就认为我把报头读完了,剩下的全部都是有效载荷。所以我们就能做到解包。封装的时候要构建http请求,请求行和报头全加上,最后再带上一个空行,然后在跟上正文,这就叫做封装。这就是http的请求,响应也同样如此。所以我们的http用来区分报头和有效载荷在编码层面上是通过一个特殊字符来区分报头和有效载荷的。
如何分用?
分用就是把你的有效载荷交给谁,这个问题不是http解决的,是具体的应用代码解决,http需要有接口来帮助上层获取参数。
http的请求和响应,在我看来是以行为单位罗列了一大批内容,在网络看来它就是一个大字符串,然后这个字符串左半部分和右半部分是通过空行分割的,所以我们能做到封装了,封装的时候就是报头+空行+正文,解析的时候一直读,只要读到空行,前半部分全都它的报头,后半部分就是正文。
HTTP操作
1.看看http请求
2.发送一个响应
http底层采用的依旧是tcp协议
http中面向字节流读的函数recv
这个函数是专门来进行网络读取所定制的一个函数。这个函数和read的使用几乎没有任何的差别,recv唯一多了一个flags,这个参数可以让我们以阻塞非阻塞包括读取后序的解密指针这样的一些东西,不过我们全程不设置或者默认为0.

最简单的HTTP服务器
实现一个最简单的HTTP服务器, 目前我们的服务端啥也不干;#include"Sock.hpp"
#include
void Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}void *HandlerHttpRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer << std::endl; //查看http的请求格式}close(sock);return nullptr;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}}
} 测试
我们运行是这个样子的
然后我们借助浏览器,在搜索栏输入服务器的ip+:+port
此时因为没响应,没给他发任何数据,但是此时我已近向服务器发送了多条http请求了



为什么客户端发了多条请求呢?
主要是因为http server得不到响应,所以它把自己请求在重复的发送。只要点击这个域名,就能把你的请求发送到我的云服务器上了。
HTTP请求
这就是一个较为完整的http请求
如果我们把换行符去掉,我们就能看到两个请求之间只空一行



这个http的请求和响应为什么都带了版本呢?
因为客户端是个软件,服务器也是个软件,两个都有版本。
eg:所有的软件都会升级,包括OS也会升级,现在有些人升级了微信,有些人没升级,作为服务器,是不会给新微信和就微信分别提供一个server提供服务的。而是根据你的微信的版本,如果你是老版本给你提供一些功能,如果你是新版本在给你提供一些功能。软件的版本决定它所能看到的功能,对于服务器来讲就可以统一使用一套服务来处理所有的新老客户端了。
对于HTTP请求的报头字段的解释
- Host:代表这个请求你想访问谁,后面跟着的就是我的公网ip和port。
- Connection:代表的是连接类型,我们都是基于短链接的
- Cache-Control:代表双方通信时的一些缓存信息
- Upgrade-Insecure-Requests:代表协议升级情况
- User-Agent:代表我们的浏览器访问时客户端的信息,比如平时我们下载软件的时候
User-Agent详解
它有很多的OS,默认给我们选中的就是windows,这就是因为你的http请求里就包括了User-Agent,里面就写了你的客户端信息。
博主用手机进行访问
我们可以看出 User-Agent显示的就是博主手机的信息。
所以我们用不同的设备去访问网站的时候,浏览器会自动根据你的本地平台帮你去识别你的主机,客户端是什么,然后服务端收到这些请求之后它可以识别这些信息,尤其是下载平台,它会根据你的设备给你推测出你的设备所适合下载的软件。


- Accept-Encoding:代表接受的编码类型
- Accept-Language: 代表接受的语言类型
服务器构建响应
现在我们的程序已经见到这个请求了,接下来我们想在服务端构建一个响应。
我们现在的响应就是无论请求什么,我都返回hello这样的字符串内容。返回时候就是向客户端写入,写入我们可以采用write。但是这里我们推荐send,这个是在linux中特有的,针对于tcp设计的接口。
send
除了多了一个参数,其他的和write一毛一样。

这样就可以直接进行发送响应吗,答案是不可以,因为我们是在模拟http的行为,你要写的可是一个http的响应,一个响应由三部分构成,我们不能只把响应正文给它,状态行,报头,空行我们都要带上。
当我们读这个http的响应或者请求时,是从上往下读的,也就是一行一行的去获取的,其中Content-Type属于响应报头的属性之一,所以我是如何知道你的有效载荷是什么类型呢?Content代表内容,Type代表类型。Content-Type就代表的是我的请求或者响应如果携带了正文,那么正文的类型是什么,就叫做Content-Type。


Sock.hpp
#pragma once#include
#include
#include
#include
#include
#include
#include
#includeusing namespace std;
class Sock
{
public:static int Socket(){int sock = socket(AF_INET, SOCK_STREAM, 0);if (sock < 0){cerr << "socket error" << endl;exit(2); //直接终止进程}return sock;}static void Bind(int sock,uint16_t port){struct sockaddr_in local;local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0){cerr<<"bind error!"<= 0){return fd;}return -1;}static void Connect(int sock, std::string ip, uint16_t port){struct sockaddr_in server;memset(&server, 0, sizeof(server));server.sin_family = AF_INET;server.sin_port = htons(port);server.sin_addr.s_addr = inet_addr(ip.c_str());if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0){cout << "Connect Success!" << endl;}else{cout << "Connect Failed!" << endl;exit(5);}}
}; HTTP.cc
#include"Sock.hpp"
#include
void Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}void *HandlerHttpRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));// 这种读法是不正确的,只不过现在没有被暴露出来罢了ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer; //查看http的请求格式std::string http_response = "http/1.0 200 OK\n";//版本,状态码,状态码描述,\n做结尾 这就是状态行//在我看来就是一个长字符串,所以不用一行一行发,只要构建好,一块发出去就可http_response += "Content-Type: text/plain\n"; //text/plain:正文是普通的文本 这就是响应报头http_response += "\n"; //这就是空行,用来区分报头和有效载荷http_response += "Shi Jiayi is a beautiful and hard-working girl"; //这就是正文send(sock, http_response.c_str(), http_response.size(), 0);}close(sock);return nullptr;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}}
} 测试

我们就在浏览器上看到了刚刚写的hello pxl.这就叫做http的响应。这就叫做http的简单响应和简单请求。
HTTP的请求与响应总结
http的请求就是请求行,请求报头,空行,请求正文;
响应就是状态行,响应报头,空行,响应正文 。
对我们来讲就是3~4部分,中间用空行作为区分,我们就能很快的区分清楚他们之间的一个格式要求。实际上在编码层面上,你发过来的请求都是被我读到buffer里面,从前向后读。虽然你的请求和响应是行状的格式,但是在我看来就是一个大字符串,所以我就可以在读取的时候对我们的协议内容做读取分析。所以http协议,如果自己写的话,本质是,我们要根据协议内容进行文本分析!(因为协议别人已经给我们定好了)得到对应的响应,然后将响应构成字符串,在响应回别人。
观察百度的网页
我们登录一下百度的服务器.没有telent命令我们可以手动安装一下
sudo yum install telnet telnet-server

手动的用Telnet构建一个请求
1.telnet www.baidu.com 80
2.Telnet窗口中按下“Ctrl+]”;
3.先按下回车,输入
GET / HTTP/1.0

此时就得到了百度对应的响应
 百度的http版本是1.0,状态码是200,状态描述是OK(这是百度的老的服务器)紧接着就是百度一堆的响应报头,包括了Content-Type,时间,Server等。紧接着就是传说之中的网页
百度的http版本是1.0,状态码是200,状态描述是OK(这是百度的老的服务器)紧接着就是百度一堆的响应报头,包括了Content-Type,时间,Server等。紧接着就是传说之中的网页

这些就是给我们压缩之后的一些html网页,它里面内置了很多html,js的内容。
我们在浏览器(Edge)打开百度官网 ,然后进入开发人员工具


这个元素里面就是百度的网页内容对应我们linux的那一大段内容(linux是为了效率,减少成本,把\n,空行全部去掉了,所以看起来乱) 。
总结一下:我们实际上在http请求时,它响应的正文部分一般都是我们的网页内容。包括图片视频这些。所以才有了http响应标识的这部分。
再谈http请求的细节
http请求没有使用json或者没有直接使用json,那么它的整个报头或者正文用空行作为分隔符,然后整体以行为单位,这种也算一个序列化,这种和发送结构体不一样,http本身所有的文本行都是按行陈列的,那么其中写入的时候一行一行去写,读取再一行一行去读,本质上就是一种序列化和反序列化的过程,只不过没有显示化的把他显示出来。http里有很多的方法,包括很多的属性。
HTTP请求

- 首行: [方法] + [url] + [版本] 像如图这种的URL,有时候服务器要做一个代理服务器要拿去你要访问资源的全的URL,大多数的URL还是像之前一样去掉域名的那种。
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束。
- Body: 就是http请求或者响应的正文;空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度。
理解Content-Length
实际上我们代码在读取http请求的时候,这种recv的读法是不对的,只不过现在没有被暴露出来

http的请求是通过多行的方式呈现的,每一行用\n作为分隔符。我们今天考虑的是server端进行读取,当我们读取的时候,一次是定义了一个大的缓冲区。当你在recv的时候,这个请求一定在底层,http的底层就是tcp,当你在进行recv时,无论是从网络里读,还是从tcp里读,一定是tcp协议给你的数据,那么其中你在recv的时候,你定义的是1024*10个字节。
实际上:
1.当http发来请求的时候实际上并不是像你所想一样,一个一个发送的,有可能http客户端会以某种方式向我们发送多个请求。
2.你今天的缓冲区定义的是1024*10这个大小,如果它是多个请求的话,每个请求是1024的大小,你一次就把所有请求一起读完了。如果缓冲区大小是1025这个大小,那么除了把整个报文读完,还把下一个报文多读了一个字节。
读取要求
第一:我们要保证每次读取都是读取完整的一个http请求。
第二:保证每次读取都不要将下一个http请求的一部分读到(我在读取的时候客户端有可能发送来多个http请求,我可能在读取的时候,一个http请求读完了,因为我缓冲区设置的问题,而导致它把下一个报文多读了,这个时候下面的报文是残缺的报文,上面的报文也不正确因为多了一块数据,这次就需要你自己去对他做分析,处理,这样是比较麻烦的,而且容易出问题)。
你怎么保证你每次读到的是一个完整的http呢?
当我们读取一个完整的http请求的时候,我们按行读取,如何判定我们将报头部分(包括请求行和请求报头)读完了呢?
读到空行,我们就可以确定报头全部读完了。
报头读完了就看后面还有没有正文,如果有正文,如何保证把正文全部读取完成呢?而且不要把下一个http的部分数据读到呢?
你要决定报头后面有没有正文,本质上是决定一个请求或者是一个响应,它对应的有没有涵盖它的请求或者响应的数据。报头后面有没有正文这个和请求方法有关。
假设有正文的话,你如何知道空行之后有多少个字符呢?
我不知道,但是当我读到正文的时候,我很清楚我已近把报头读完了,报头读完了,我们就能正确提取报头中的各种属性,其中包括一个字段,Content-Length。如果后面还有正文的话,那么报头部分有一个属性:这个属性就是Content-Length,它表明正文部分有多少个字节!!!
虽然没有学tcp,但是我们知道,所有的数据都是通过fd读取的!所以我无脑读,一直读到空行,我就能保证把http协议报头部分全部读上来,其中就包括了Content-Length,Content-Length就表明了如果有正文的话,正文部分的字节数。所以当我们正常读取的时候,一旦读到空行,然后我们再来看它的Content-Length,根据Content-Length确定读取多少个len自己的正文。Content-Length的存在就允许我们一字不差的吧它的正文部分全部读取到。
换句话说,报头读取的时候以空行为分隔符,把报头先得到,然后根据报头中的Content-Length在读取正文,这个正文我们就称之为http协议的有效载荷,Content-Length表明,http协议如果携带有效载荷,它的 有效载荷是多长。Content-Length也叫自描述字段。
如何读到一个完整的http协议?
1.有了空行,我们可以保证把报头全部读完
2.报头全部读完,我们就能分析方法和分析Content-Length,从而得出要不要读正文以及正文多长
3.正文是多少字节,我们按照Content-Length把正文全部读上来,
至此,我们就能读到一个完整的http请求或者响应。
- Content-Length:帮助我们读取到完整的http请求或者响应。同时根据空行能做到将报头和有效载荷进行分离(分离的过程就是解包的过程)。当你没有正文的时候,报头属性里面是不存在Content-Length属性的。这就是规定。
HTTP响应

- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
同样的如果没有写Content-Length,浏览器也会正常显示,就比如我们自己实现的服务器发送的响应,这个就和浏览器的编写,应用层的支持是否严格有很大的关系,其实应用层实际上做了很多的约定,但是应用层要与人进行打交道,所以你曾经定好的再好的规则,只要是人参与进来了,它的支持度并不好,相当于我做了规定,但是有人就是不遵守,而且这个人还不少,那么不遵守只能让浏览器厂商针对这种情况做一些优化,但是一旦设计到内核,大家基本上都会遵守的。
HTTP的请求方法
http请求是包括请求的方法,URL和http的版本。http的版本最早的是1.0版本,使用最广泛的是1.1版,现在最新的还有2.0版。http 1.0和1.1最主要的区别是是否支持长连接。
短链接
短链接:一个请求,一个响应,close socket。客户端发起一个请求,服务器给一个响应,服务器响应完毕后把链接一关。我们刚刚缩写的就是短链接。http协议最早使用的就是短链接。一个请求,一般就是请求一个资源,比如一个请求就是请求一张网页,一个图片,一个视频,一个音频。请求完资源后链接关闭。
早期的http1.0为什么用短链接呢?
1.当时的网络资源并不丰富,主要以文本,最多是图片为主。
2.当时的服务器压力并不大,请求的资源都比较短小。网速比较好,服务器上的资源就比较大,网速特别差,服务器上的资源就比较小。eg:1,2G的时代我们能看文字,3G的时代我们能看图片,4G的时代我们可以看视频。资源变的越来越丰富,本质就是每一个资源的体积变的越来越大了。
最主要是因为短链接简单。
HTTP的方法
无论是请求还是响应都会携带http的版本。分别代表客户端和服务器采用的http版本。
http方法中,GET和POST方法是最重要的两个方法,没有之一。
GET大部分都是获取资源;
POST是传输资源;但其实他俩都可以进行获取和传输。

- PUT方法:你在浏览器上访问某些资源的时候,你一点击就自动给你下载了,实际上那个下载就对应的是PUT方法。
- HEAD方法:其实就是客户端告诉服务器,我不要正文,只要报头。
eg:
HEAD方法就只拿到了http的报头,没有正文。
用GET方法就拿到了报头和正文。


实际上HTTP看起来服务很多,但是对于一个web服务器来说,很多方法都是默认关掉的,
eg:OPTIONS,HTTP 1.1虽然支持,但有可能用协议的人把这个方法给禁掉了。

像PUT,DELETE,OPTIONS,TRACE,CONNECT这些方法http协议是支持的,但实际上不一定被使用协议的人所打开。别人就把这些方法禁止掉了,不让你用,一般的http协议,最多给你提供的方法就是GET,POST,HEAD。其他的不给你暴露出来。主要是为了防止出现一下恶意用户,比如你把PUT暴露出来了,有些恶意分子,不断像你的服务器上传数据,最后把你的磁盘打满,还有一些直接通过DELETE方法删除你的数据。这肯定是不行的,所以我们只给你暴露出有限的方法。
/ (根目录)
首先我们在做请求的时候,永远会带一个 / ,这个 / 叫做要请求的资源。
当我请求时,请求的就是这里的 / ,服务器是怎么看待这个 / 的,linux中这个 / 代表了根目录。但是在http请求中 / 并不是根目录,而叫做web根目录。

eg:我们再次运行我们的服务器:
如果请求默认是8080(8080后面啥也不带),我们看到对应的请求就是一个 /
如果你后面带了对应访问服务器上的某个路径(/a/b/c/d),其中就会把路径显示到这里。


所以这个 / 就叫做我们要访问的资源所在的路径, 我们一般要请求的一定是一个具体的资源
比如:你要请求的是一个网页,图片。你给我一个 / ,意思就是说我要请求的是web根目录下的所有内容,我把这个网站的所有内容全部发给你。但是这样肯定是不行的,我们要具体指明网页或图片的路径。
但是如果请求是 / ,意味着我们要请求该网站的首页!!!,首页一般叫做index.html ,或者是index.htm 。换句话说你是 / 这么请求的,别人的服务器可能最终默认的会把它的首页信息给你返回。
eg:我访问百度,两种访问的方式都能拿到百度的首页
实际上当你请求时,如果你的请求时 / ,我们的服务器它不会把web根目录下所有的内容给你返回,而是想办法给你把根目录下的首页返回,一般所有的网站,都要有默认的首页信息,对应的就是index.html这样的内容。

总结:当我们请求某个资源的时候,我可以通过带一个完整路径的方式,也可以直接请求 / ,默认就是首页。
实验
依然是基于我们上面的服务器代码
首先在当前路径下建立一个wwwroot目录,这个wwwroot我们就称之为http的web根目录
在该目录下我们新建一个index.html 就是http它的一个首页信息。
这个http请求就是当用户在请求时通过http协议来把我们所对应的当前目录下的web根目录下的网页信息给你返回。



响应报头部分
首先,我们指明访问文件的路径。此时别人给我请求时,我就可以把这个网页信息返回。

但是返回的时候,不仅仅返回正文网页信息,而是还要包括http的请求
Content-Type 代表正文部分的数据类型,今天我们响应回去的不是字符串,而是把web服务器的根目录的index.html响应回去。

ps:Content-Type 对照表
HTTP Content-type 对照表 (oschina.net)

接下来我们还可以带一个Content-Length,代表这个文件的大小。
stat
我们今天用stat获取文件大小。
stat可以通过指定的文件路径,获取文件的指定属性 。-1就是失败,0是成功。这个stat的结构体是一个输出型参数,我们要把所有的属性获取出去。
st_szie就代表了文件的大小。


响应正文
接下来就是正文,上面的步骤就叫做构建一个响应.
这次的正文就是要拿的这个网页内容。

完整代码
Http.cc
#include"Sock.hpp"
#include
#include
#include
#include
#include#define WWWROOT "./wwwroot/"
#define HOME_PAGE "index.html"// 其中wwwroot就叫做web根目录,wwwroot目录下放置的内容,都叫做资源!
// wwwroot目录下的index.html就叫做网站的首页
void Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}void *HandlerHttpRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));// 这种读法是不正确的,只不过现在没有被暴露出来罢了ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer; //查看http的请求格式// std::string http_response = "http/1.0 200 OK\n";//版本,状态码,状态码描述,\n做结尾 这就是状态行// //在我看来就是一个长字符串,所以不用一行一行发,只要构建好,一块发出去就可// http_response += "Content-Type: text/plain\n"; //text/plain:正文是普通的文本 这就是响应报头// http_response += "\n"; //这就是空行,用来区分报头和有效载荷// http_response += "Shi Jiayi is a beautiful and hard-working girl"; //这就是正文// send(sock, http_response.c_str(), http_response.size(), 0);std::string html_file = WWWROOT; //访问的文件在这个路径下html_file += HOME_PAGE;struct stat st;stat(html_file.c_str(), &st);//返回的时候,不仅仅返回正文网页信息,而是还要包括http的请求std::string http_response = "http/1.0 200 OK\n";// Content-Type 代表正文部分的数据类型,今天我们响应回去的不是字符串,而是把web服务器的根目录的// index.html响应回去。http_response += "Content-Type:text/html;charset=utf8\n";http_response += "Content-Length: ";http_response += std::to_string(st.st_size);http_response += "\n";http_response += "\n"; //空行//接下来才是正文std::ifstream in(html_file);if(!in.is_open()){std::cerr << "open html error!" << std::endl;}else{std::string content; //正文内容std::string line; while(std::getline(in,line)) //按行读取 {content += line; //正文就全部在content里面了。}http_response += content;in.close();send(sock, http_response.c_str(), http_response.size(), 0); //响应回去}}close(sock);return nullptr;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}}
} 测试:
ps:对于port,0-1023是系统内置的端口号,我们用不了,1024之后的随便用


比如我们将网页内容调整一下(服务器不用关闭,直接修改)
此时我们就看到了修改后对应的网页内容


其中wwwroot就叫做web根目录,wwwroot目录下放置的内容,都叫做资源!换句话说我将来可以在这个wwwroot下定义一个图片目录,网页目录,视屏目录...最后你要访问什么资源就是从这个wwwroot开始,来去访问你想访问的资源的。
eg:我们在访问网站的时候,上面是有对应的路径资,/ 这个一定是它的服务器上的web根目录,后面的就是具体路径
web根目录可以拷贝到linux下的任何目录下。wwwroot目录下的index.html就叫做网站的首页
当一个用户发起请求的时候,如果它的请求是根目录,服务器内部会对你的方法做判断,你访问的是 / ,就直接把你的路径改成web服务器下的首页信息。

验证GET和POST方法
上面我们做的事情就是就是把http的响应由字符串转换成了文件,实际上将来要访问很多资源,就是在web根目录下有很多的资源,让你去访问。
我们平时有注册或者登录的经历(输入账号和密码),就需要有一个输入框,你所看到的输入框实际上就是网页。
推荐学习前端网站:w3school 在线教程 https://www.w3school.com.cn/
https://www.w3school.com.cn/
GET方法
html的表单

制作表单
我们将我们的index.html首页进行修改
结果:

我们在增加一个登录选项


我们发现输入信息点击登录以后?后面没有任何内容,这是因为表单中这两个输入框,我们没有给他起名字,所以就无法获取参数
ps:URL 通过?来带参数,连接域名和参数,经常会用到

再次修改


我们这里用的是GET方法,当我们传入参数,密码,一点击登录提交,它就会直接访问 /a/b/handler_from?name=pxl&password=123456。
服务器的http请求
我们用的是GET方法,我们没有正文,提交的这两个参数是拼接在URL后面的以?作为分隔符,两个参数用&进行隔离 。

GET方法,如果提交参数,是通过URL进行提交的。
换句话说,实际上在服务器中,当我们输入表单提交,用的是GET方法的时候,提交参数的时候,浏览器自动把你的表单里的信息姓名和密码拼接在URL的后面,然后让你的http请求拿到这样的数据,这样的话,前端的数据就被后端的C++代码拿到了,我们实际上拿到的这个请求,参数是在我们读到的这个请求当中的,所以数据就被C++程序拿到了,C++程序拿到后就可以做字符串分割,提取出用户名和密码,再继续用C++在服务器后端做一些连接数据库,访问数据库,和你输入上来的用户名,密码作对比,从而让你实现登录过程。
POST方法
我们直接将method改成POST
这次我们发现上面什么也没有。


我们查看下服务器的请求
POST请求的资源还是在URL中,但是它的参数在正文当中,所以POST方法是通过提交正文提交参数的。

GET和POST的区别
这就是GET和POST的区别。GET和POST都可以提交参数,只不过,GET是将参数拼接到URL后的,POST是通过正文提交参数的。
通过抓包观察GET与POST
接下来我们使用Fiddler Classic工具,这是一个抓包工具,它是可以抓http的
我们直接打开该工具,刷新下我们自己的网页,就可以看到当前就抓到了第一个报文81.70.240.196:8080这个端口
双击后我们就能看到发起的请求及得到的响应
我们输入密码后进行登录
就能看到我们提交的请求,因为我们用的fiddler,所以它的URL那样显示。



抓包的原理
本来我的client直接请求服务器,服务器直接给client响应,现在变成了我的client先把请求交给fiddler,然后fiddler在帮我们去请求,server给的响应再给fiddler,fiddler再给我们的client对应的浏览器,所以所有的http请求都会流经fiddler,所以fiddler就可以抓包。因为fiddler要帮助客户端去请求server,所以它的URL显示的是该样式,http://81.70.240.196:8080/a/b/handler_from 前面就是我的公网ip,因为它要给我请求。
fiddler查看POST 方法

fiddler查看GET
同样我们输入用户名,密码后进行登录
这个就是GET方法,fiddler把参数都抓到了,正文部分没有。


总结:首先请求的时候,请求的是什么资源都是会出现在URL当中,只不过POST和GET传参,如果你进行提取参数的时候,通常参数的位置是不一样的,GET就在URL后,POST在正文部分。
GET和PSOT
概念问题
GET方法叫做,获取,是最常用的方法。默认一般获取所有的网页,都是GET方法,但是如果GET要提交参数(它也是可以进行提交的),是通过URL来进行参数拼接从而提供给server端。
POST方法叫做,推送,是提交参数比较常用的方法,但是如果提交参数,一般是通过正文部分提交的,但是你不要忘记,Content-Length:XXX 表示参数的长度
区别
参数的提交位置不同
1.参数提交的位置不同,POST方法比较私密(但是私密!=安全,很多人说POST传参更安全,这种说法是错误的,因为我们通过了fiddler抓包工具把他的数据给抓到了)因为它不会回显到浏览器的URL输入框!GET方法不私密,它是会将重要信息回显到URL的输入框中,增加了被盗取的风险。并不代表POST方法就没有被盗取的风险,所有在网络里传送的数据,没有经过加密,全部都是不安全的,随时都会被人直接扒出来。安全对我们来讲就是要进行加密!!!
2.GET是通过URL传参的,而URL是有大小限制的!和具体的浏览器有关!比如有的浏览器只允许你输入1024个长度的URL,那么你在请求时超过他就没办法显示了。POST方法,是由正文部分传参的,一般大小没有限制。
如何选择
1.GET:如果提交的参数不敏感,数量非常少,可以采用GET,
2.POST:提交的参数敏感,数量多,可以采用POST
所以选择时以GET为主,GET顶不住了,选用POST。
ps:HEAD方法就是当一个请求读上来后就是在buffer里面,当我知道它是HEAD以后,我把响应响应回去,正文部分不给他就可以了。
当我们在浏览器中输入数据,这叫做前端数据,当你一登录,以GET或者POST方法提交参数,那么这个参数不管是在URL当中,还是在正文里面,一定会保存到我们读取到的buffer里面。所以http协议处理,本质是文本分析。
所谓的文本分析
1.0 http协议本身的字段,比如:将你的第一行拿出来,空行一分,拆出来你的请求方法,请求的URL,请求的版本;空行之前的所有内容:kv值把他放在一个map里,我们就有了一个kv的请求报头。
2.0提取参数,如果有的话。有可能客户端是给我们提取参数的,最大的变化是前端的数据经过表单提交直接被你的C++程序,或者其他语言读到。读到之后就将前端数据,转换成了后端语言。然后我们就可以用后端语言处理。GET或者POST其实是前后端交互的一个重要方式。
HTTP常见的状态码
应用层是人要参与的,人的水平参差不齐,http的状态码,很多的人,根本就不清楚如何使用,又因为浏览器的种类太多了,导致大家可能对状态码的支持并不是特别好。
比如:我们把我们代码的响应的状态码改成404,状态描述改为Not Found;
我们通过fiddler看到响应是404 Not Found
但是访问服务器的时候,仍然是正常显示的,并没有做任何处理
类似于404的状态码,对浏览器没有任何的指导意义,浏览器就是正常的显示你的网页,你返回的网页是什么我就给你显示什么,浏览器不根据404做显示。

eg:类似于这种我们发现访问失联的网页并不是浏览器给你显示的,而是服务器给你显示的。也就是浏览器对404不做处理,就做一个正常的页面显示就完了。

具有指导意义的状态码
但是也存在一些状态码对我们是有指导意义的。

- 1开头的状态码,表示请求正在处理, 比如服务器收到一个请求,服务器处理要花很长时间,它要给你返回一个响应,就相当于说客户端不要着急,这个请求正在处理。1开头的用的非常少。
- 2开头最常见的是200(OK-请求正常处理完毕)。
- 3开头的状态码叫做重定向,有301,302,307,308。
- 4开头的最典型的是403(Forbidden禁止访问),404(Not Found)我们要处理404这种错误不要指望浏览器,而是说如果是404错误就需要自己进行处理,比如如果404,那么你就应该有一个404的相关处理,当你请求的资源不存在,你的服务器就应该构建一个正常的响应,告诉客户端我不存在。
- 5开头的状态码,表示服务器内部错误,最典型的右500,503,504。
eg:手动写一个404
我们将代码进行修改,专门弄一个不存在的路径
#include"Sock.hpp" #include#include #include #include #include #define WWWROOT "./wwwroot/" #define HOME_PAGE "index.html-back"// 其中wwwroot就叫做web根目录,wwwroot目录下放置的内容,都叫做资源! // wwwroot目录下的index.html就叫做网站的首页 void Usage(std::string proc) {std::cout << "Usage: " << proc << "port" << std::endl; }void *HandlerHttpRequest(void *args) {int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));// 这种读法是不正确的,只不过现在没有被暴露出来罢了ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer; //查看http的请求格式// std::string http_response = "http/1.0 200 OK\n";//版本,状态码,状态码描述,\n做结尾 这就是状态行// //在我看来就是一个长字符串,所以不用一行一行发,只要构建好,一块发出去就可// http_response += "Content-Type: text/plain\n"; //text/plain:正文是普通的文本 这就是响应报头// http_response += "\n"; //这就是空行,用来区分报头和有效载荷// http_response += "Shi Jiayi is a beautiful and hard-working girl"; //这就是正文// send(sock, http_response.c_str(), http_response.size(), 0);std::string html_file = WWWROOT; //访问的文件在这个路径下html_file += HOME_PAGE;//接下来才是正文std::ifstream in(html_file);if(!in.is_open()){std::string http_response = "http/1.0 404 Not Found\n";http_response += "Content-Type:text/html;charset=utf8\n"; http_response += "\n"; //空行http_response += " 你访问的资源不存在
";send(sock, http_response.c_str(), http_response.size(), 0); //响应回去}else{struct stat st;stat(html_file.c_str(), &st);//返回的时候,不仅仅返回正文网页信息,而是还要包括http的请求std::string http_response = "http/1.0 200 OK\n";// Content-Type 代表正文部分的数据类型,今天我们响应回去的不是字符串,而是把web服务器的根目录的// index.html响应回去。http_response += "Content-Type:text/html;charset=utf8\n";http_response += "Content-Length: ";http_response += std::to_string(st.st_size);http_response += "\n";http_response += "\n"; //空行std::string content; //正文内容std::string line; while(std::getline(in,line)) //按行读取 {content += line; //正文就全部在content里面了。}http_response += content;in.close();send(sock, http_response.c_str(), http_response.size(), 0); //响应回去}}close(sock);return nullptr; }int main(int argc, char *argv[]) {if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}} }

404的错误属于客户端问题,还是服务器问题?
404的错误属于客户端的问题,就好比你去京东去看抖音短视频,你请求的资源在京东服务器上是没有的。只要一个网站的资源是具体的,那么他一定是有限的,只要是有限的就一定会碰到没有的 资源。
服务器的问题有哪些呢?
比如:今天来了个新请求,创建线程失败了。处理请求时因为代码里存在问题,而导致程序崩溃,等等与服务器逻辑有关的错误,客服端请求是常规请求,但你服务器内部因为创建线程,创建进程...出错了,这就叫做服务器出错。
这就是5开头的状态码,表示服务器内部错误,最典型的右500,503,504。
3开头的状态码
3XX的状态码是有特殊含义的,3开头的状态码主要是叫做重定向。
重定向:
1.永久重定向 301
2.临时重定向 302或者307
重定向是什么?
当访问某一个网站的时候,会让我们跳转到另一个网址;
当我访问某种资源的时候,提示我登录,跳转到了登录页面,输入完毕密码,登录的时候,会自动跳转回来(登录,美团下单,)。比如你在淘宝上买个东西,你下单支付后,会告诉你支付成功,然后说3秒内,网页会自动跳转回去,你可选择立即跳转,你不管的时候,3秒以后它就会自动跳转回去。像这种现象,我们都叫做重定向。
比如:在访问力扣的时候,力扣想把老的网址废弃掉,让我们使用新的网址。如果它直接把老网站封掉,这样就会让很多老用户以为网站没了,所以力扣就在网站上做处理,直接访问新网址没有问题,访问老网站时会自动跳转到新网站(只不过力扣选择的是让我们手动点击跳转到新网站)这就叫做重定向。

什么叫做永久重定向,什么叫做临时重定向?
因为老网址的服务器配置太低了,所以我改了,改成新网站了。但是其他的老的用户只认识老网站,我不能直接把老网站关掉。所以我就在老网站的服务器中做了一个永久重定向。意思就是说,现在有3个老用户,依旧习惯访问老网站,当他访问时,老网站的服务器不对他们提供服务,而是直接告诉老用户,你请求的已经不是我了,而是叫做www.new.com,请你访问这个网站,所以这个客户不需要知道,它的浏览器会自动向新网站重新发起请求,然后新网站重新得到响应给用户提供服务。如果用户将来还想访问老网站,那么这种永久重定向会把用户以前记录的,比如说书签,你添加的这个书签是在浏览器里添加的,当浏览器收到,这个是永久重定向,除了让浏览器访问新网站后,还要浏览器把用户记录的书签,由新的域名替换调旧的域名。以后用户点击书签,就会直接去访问新网站,再也不访问就网站了。
永久性重定向通常用来进行网站搬迁,域名更换。对我们来讲就相当于,把以前的服务全部迁到了新网站上面,然后在老的服务上,添加一个重定向功能,然后一个客户来的时候,老的服务器不提供服务,直接通过永久性重定向告诉浏览器说我已近搬到最新的地方了。然后在更新下本地浏览器的缓存的一些数据,包括书签,当用户再次点击书签的时候,就可以跳转到新网站,不在访问老网站,随着老用户不断去访问旧网站,最后用户就全部被切换到了新网站中。这就是永久重定向。
比如说:我今天在美团上下单,支付成功了, 就提示我支付已经成功,正在返回中,我从A页面,跳转到支付页面,支付成功后又返回到B页面(商家接单的页面),但是对我们来讲一定是从一个页面跳转到另外一个页面,而且每次下单都有如此操作。这个跳转是为了完成某种业务的需求,比如我进行注册后,要给用户提供一个注册页面,注册成功后要返回到登录页面,登录成功后返回到首页,当每一次登录或者注册成功,不需要你自己手动的再去回到登录或注册首页,而是服务器自动让你回去。每次登录注册都需要重复做这个工作,属于业务的环节。这种情况就是临时重定向。
模拟重定向
重定向是需要浏览器给我们提供支持的,浏览器必须识别310,302,307这样的状态码。server要告诉浏览器,我应该再去哪里。http响应的报头属性,Location:新的地址
eg:服务器构建响应的时候,状态码是301,描述是永久重定向,Location:告诉我要重定向到哪里,我们以重定向到腾讯的官网。访问我的时候就直接跳转到腾讯。

完整代码
#include"Sock.hpp"
#include
#include
#include
#include
#include#define WWWROOT "./wwwroot/"
#define HOME_PAGE "index.html-back"// 其中wwwroot就叫做web根目录,wwwroot目录下放置的内容,都叫做资源!
// wwwroot目录下的index.html就叫做网站的首页
void Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}void *HandlerHttpRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));// 这种读法是不正确的,只不过现在没有被暴露出来罢了ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer; //查看http的请求格式std::string response = "http/1.1 301 Permanently moved\n";response += "Location:https://www.qq.com/\n";response += "\n";send(sock, response.c_str(), response.size(), 0);}close(sock);return nullptr;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}}
} 测试:
从fiddler看出,别人给服务器请求,服务器给一个响应,直接就是301,永久重定向,Location填的就是腾讯官网,此时就直接跳转到了腾讯的官网,
这个过程对我们来讲,我们并不知道,你以为你当前访问的是这个服务器,实际上自动就别浏览器跳转到了新的网站。



测试302,临时重定向



永久重定向遗留的问题

做完301永久重定向这个实验后,我们会发现自己的浏览器把这个服务器端口记住了(这点还体现在你的服务端,只有第一次访问域名,服务器出现请求,之后多次进行访问,服务器并未出现任何请求),不管你的服务端时候运行,只要你访问这个域名就会直接给你重定向到腾讯官网,如何解决?
我们只需要清除一下301重定向这段时间内的浏览器缓存即可,博主的浏览器是Edge 。清除的内容不需要手动选择,浏览器默认的即可。清楚完毕后,我们就发现我们的域名不在进行重定向了。


再谈HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
我们之前的所有实验,全部都是请求,响应,断开链接,服务器上有很多资源。
一个大型的网页内部,是由非常多个资源组成的!!!每个资源都要发起http请求!!!这个就是基于短连接的策略。所有http/1.0叫做短连接。http/1.1之后,我们引入了长链接。其中客户端发起请求要设置一个Connection字段,叫做Keep-alive叫做保持活,说白了就是这个连接要一直使用,长连接服务端构建响应也要包括Connection,双方就任务我们都是1.1以上的版本,就都用长连接,这样的话,双方通信时复用同一个连接,此时就不用再打开连接,关闭连接。这样的成本就降低了。
长连接与短连接
一般而言,一个大网页是由多个元素组成的。
短连接
http/1.0 采用的网络请求的方案是短连接。
短连接的运算规则:request->response->close。实际上进行一次http请求的时候,本质就是把你要访问的对应资源打开,返回一个资源,这个资源可能是一张网页,可能是网页里面的一张图片,可能是一个视频等。所以如果网页由多个元素构成,那么一次请求只返回一个资源,在访问一个由多个元素构成的网页的时候,如果是http/1.0,就需要多次进行http请求,比如我的网页构成里面有100个元素,此时就要重复的进行http的100次请求,而http协议是基于tcp协议的,tcp要通信必须执行以下步骤: 建立连接->传送数据->断开链接。每一次的http请求都要执行该步骤,整体比较耗时间,效率不高。短连接的效率比较低,所以就诞生了长连接的概念,http/1.1支持长连接。
服务端有一张网页,这个网页里面又有很多很多的其他资源,比如图片之类的。当我们的一个客户端发起请求的时候,它请求到这个网页,这个网页给他进行返回,返回之后,客户端拿到了这个网页本身,我们发现这个网页里面有很多的,包含第三方的链接或者另外一些资源,客户端发现这些资源还是在你的服务器上,所以客户端不断的进行请求和响应,得到多份资源,最后经过不断的重复请求连接得到对应的资源构建的一个网页,这叫做短连接。
长连接
长连接:建立好一条连接,双方进行请求,响应的时候都用这一条连接,就能把这个网站中的所用的各种资源全部拿下来,拿下来的时候,这条连接始终不关闭,这种技术就称之为长连接。
长连接主要解决的就是每一次请求都要进行请求建立tcp请求,而导致每一次请求资源都要重新建立连接这样的频繁建立连接的过程。长连接通过减少频繁建立tcp连接,来达到提高效率的目的!我们虽然不知道tcp如何建立连接,但是我们写tcp套接字,我们的客户端必须得connect,当connect成功,才必须进行后序访问(之前我们的实验中connect都很快,这是因为你的服务器资源本身只有你一个人用,没有人和你抢,还有就是你connect的次数并不多),如果tcp请求的频率特别高,然后连接建立的次数太频繁其实就会降低我们的效率,而我们通过长连接就可以直接通过一个连接把网页的所有资源得到,在浏览器中构建一个完整的网页。
Connection

有可能双方有一方不支持长连接,我们就可以通过报头里Connection这个选项,Connection如果携带了Keep-Alive表示它支持长连接。有时候没有这个Connection选项,或者这个选项是close,就代表它不支持长连接,只支持短连接。
类比生活中的例子:我现在要让你办5件事情,我通知第一件事情,我给你打一个电话,打完电话一挂,过来一会,我在给你打第二个电话,以此类推,让你办5件事情,就给你打5次电话,这5次电话,每一次都要重新给你拨号,然后你接通之后,我们两建立连接成功,在进行沟通对应的一件事情;现在变成了我给你打一次电话,你不要挂电话,然后一个电话就把5件事情全部说完了,这就是长连接。
cookie 与 session
背景引入
现实生活中,很多地方我们用的都是http协议,比如:我们登录某些网站,然后你会发现,你把浏览器关掉了,或者直接把网页关掉了,过一会再重复的访问这个网站的时候,第一次需要你进行账号,密码的登录,但是第二次,第三次在访问这个网站的时候,你就不需要在输入账号密码,就能直接登入了。
http协议本身是一种无状态的协议!就代表它很简单。
在比如我们打开一个视频网站,我要看一个电影,但是这个电影是VIP才能看的,我登录账号以后,这个视频网站是如何知道我是不是VIP呢?如果是VIP就直接播放电影,不是VIP就不能播放电影。
我们的日常经验:在网站中,网站是认识我的。当我访问一个网页就是发起了一次新的http请求,我打开一部电影也一定是跳转到一个新的网页中。各种页面跳转的时候,本质就是进行各种http请求,这个网站照样认识我!
但是http协议本身是一种无状态的协议,它的无状态的含义就是今天我发起第一次http请求,那么再发起第二次请求,这两次请求对于http的客户端和服务器来讲,它不知道曾经发起了第一次,也不关心即将发起的第二次,只关心当前次干了什么,也就是http协议它并不记录我们发起这次http请求的上下文信息,谁发的?什么时候发的?历史上有没有发过?全部都不关心,http只关心本次请求有没有成功,对历史上的请求,它不做任何的记录,这就叫做无状态。
问题引入
目前。上述两个知识比较矛盾,
1.经验告诉我们,你今天进行各种页面跳转,本质就是发起了各种http请求,让我们得到网页的内容,但是我们发现不管怎么跳转,网站都是认识我们的,我是不是VIP它一看就知道。
2.http协议本身是一种无状态的,也就是说http协议,它压根就不知道发起这次http请求的是谁,历史上这个人有没有发起过,历史上它发起的内容有哪些,通通不关心,每一次http请求就是从最原生的方式帮我们继续重新请求资源,历史上的信息它从来不记录,也就是说http请求,在任何一次请求的时候,都不知道是谁发起的请求,只要告诉我你要访问谁就可以了。
eg:你的男朋友容易失忆,你今天和他一起玩了,但是第二天他就不认识你的,去了什么地方,你是谁,他都不认识,因为你的男朋友不记录历史数据,他只记录这次谁陪我去玩了。这就是无状态。
Cookie
对我们来讲,http是不记录上下文的是无状态的,那网站是如何认识我的呢?
当我请求各种各样新的网页的时候,有的视频就是需要VIP才能播放的,我登录的时候,只是在登录页面发起http请求,当我再去访问新的VIP视频的时候,它怎么能认识我呢?
我们肯定是有新的技术保证客户始终在线,网站认识我并不是http协议本身要解决的问题,网站认识我和http无状态是两种层面上的东西,让网站认识我,http可以提供技术支持(但是我的http照样是无状态的),来保证网站具有“会话保持”的功能。说白了,假设今天的网站有10000个网页,http的角度这就是10000个网页,每个网页都是独立的,站在网站的视角,就是我要知道谁都访问了哪些网页。
我们让网站认识我,实际是一种cookie技术,cookie主要是用来做“会话保持的”,会话保持更高级的说法叫做"会话管理"。
会话与会话管理
会话:我们登录xshell的时候,输入账号,密码,xshell就认识我了,其中我登录的时候,就叫做一个建立会话的过程。
会话管理:同样的,我们登录一个网站的时候,一旦登录成功,网站记录你的个人信息,让你在这个网站中可以进行各种你的权限范围之内的各种资源访问,这就叫做会话管理。
http的核心功能主要是帮助我们解决网络资源获取的问题,这些会话保持的功能本身http不给你彻底解决,但是我可以给你提供技术支持,会话保持就需要你自己解决。
eg:我当前的b站是处于登录状态的,关闭网页后,在打开还是登录状态,但是我将它的cookie信息删除
再次刷新页面网站就不认识我了,就需要我们再次登录了
刚刚的cookie就能决定网站是否认识我。


cookie
1.浏览器角度:cookie是一个文件(这个文件在浏览器中),该文件里面保存的是我们的用户的私密信息。
2.http协议角度:一旦该网站对应有cookie,在发起任何请求的时候,都会自动在request中携带该cookie信息!!!
我们进行登录注册的时候,服务器端得到用户名和密码,后端经过认证,登录成功。然后浏览器内部会形成一个cookie文件,里面保存的就是username和password,一旦登录成功,说明这次输入的用户名和密码是合法的,浏览器就把服务器认证成功的用户名和密码写到这个cookie文件中。后续的请求,每一个请求的请求报头属性,都会自动携带对应的cookie。
意思就是说:你一旦第一次登录成功,登录成功认证之后,浏览器自动会把你登录成功的用户名,密码写在一个cookie文件里,后续所有的读写请求都会在自己的请求报头属性里都会自动携带上对应的cookie,也就是它会把这个cookie里面的username,password这样的字段携带上,然后每一次都会发送给这个server,所以server就可以每一次针对你访问的所有请求,因为你自动就携带了用户名,密码,所以在后端,没访问一个网页,每对应一个网页都可以进行用户名,密码的认证,只有你通过了,server在给你响应回你的请求,如果认证不通过,就告诉你这个视频是VIP要看到,你看不了。或者你得先登录,登录后才能看。浏览器会自动帮你在请求的报头属性里携带这个cookie。所以服务器在后续请求时,就认识了你。以上是基本理解,仅仅是为了理解,实际上我们现在很少有情况是把用户名,密码保存到cookie。
验证cookie
Set-Cookie:服务器向浏览器设置一个cookie。当我们一旦使用了这样包含Set-Cookie这样的选项这样的请求返回给浏览器时,就是在指挥浏览器,让浏览器帮我把Set-Cookie后面的内容,写在你自己的cookie文件里,从此往后,你每次向我请求时,都把这个信息带上。
Sock.hpp
#pragma once#include
#include
#include
#include
#include
#include
#include
#includeusing namespace std;
class Sock
{
public:static int Socket(){int sock = socket(AF_INET, SOCK_STREAM, 0);if (sock < 0){cerr << "socket error" << endl;exit(2); //直接终止进程}return sock;}static void Bind(int sock,uint16_t port){struct sockaddr_in local;local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0){cerr<<"bind error!"<= 0){return fd;}return -1;}static void Connect(int sock, std::string ip, uint16_t port){struct sockaddr_in server;memset(&server, 0, sizeof(server));server.sin_family = AF_INET;server.sin_port = htons(port);server.sin_addr.s_addr = inet_addr(ip.c_str());if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0){cout << "Connect Success!" << endl;}else{cout << "Connect Failed!" << endl;exit(5);}}
}; Http.cc
#include"Sock.hpp"
#include
#include
#include
#include
#include#define WWWROOT "./wwwroot/"
#define HOME_PAGE "index.html"// 其中wwwroot就叫做web根目录,wwwroot目录下放置的内容,都叫做资源!
// wwwroot目录下的index.html就叫做网站的首页
void Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}void *HandlerHttpRequest(void *args)
{int sock = *(int *)args;delete (int *)args;pthread_detach(pthread_self());#define SIZE 1024*10char buffer[SIZE];memset(buffer, 0, sizeof(buffer));// 这种读法是不正确的,只不过现在没有被暴露出来罢了ssize_t s = recv(sock, buffer, sizeof(buffer), 0);if (s > 0){buffer[s] = 0;std::cout << buffer; //查看http的请求格式std::string html_file = WWWROOT; //访问的文件在这个路径下html_file += HOME_PAGE;//接下来才是正文std::ifstream in(html_file);if(!in.is_open()){std::string http_response = "http/1.0 404 Not Found\n";http_response += "Content-Type:text/html;charset=utf8\n"; http_response += "\n"; //空行http_response += "你访问的资源不存在
";send(sock, http_response.c_str(), http_response.size(), 0); //响应回去}else{struct stat st;stat(html_file.c_str(), &st);//返回的时候,不仅仅返回正文网页信息,而是还要包括http的请求std::string http_response = "http/1.0 200 OK\n";// Content-Type 代表正文部分的数据类型,今天我们响应回去的不是字符串,而是把web服务器的根目录的// index.html响应回去。http_response += "Content-Type:text/html;charset=utf8\n";http_response += "Content-Length: ";http_response += std::to_string(st.st_size);http_response += "\n";http_response += "\n"; //空行std::string content; //正文内容std::string line; while(std::getline(in,line)) //按行读取 {content += line; //正文就全部在content里面了。}http_response += content;in.close();send(sock, http_response.c_str(), http_response.size(), 0); //响应回去}}close(sock);return nullptr;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock);for ( ; ; ){int sock = Sock::Accept(listen_sock);if (sock > 0){pthread_t pid;int *parm = new int(sock);pthread_create(&pid, nullptr, HandlerHttpRequest, parm);}}
} 首先我们不加 Set-Cookie
我们看到cookie是空的,没有任何的cookie信息

添加cookie
 至此,我们就添加了一个cookie ,这个Set-Cookie就是我们在响应报头里添加的报头属性,id=...就是我们要设置进文件中的内容,\n代表它是一行。
至此,我们就添加了一个cookie ,这个Set-Cookie就是我们在响应报头里添加的报头属性,id=...就是我们要设置进文件中的内容,\n代表它是一行。
我们访问我们的服务器,就看到了两个cookie
然后我们在多刷新几次这个网页。
我们发现第一次,访问这个网页,正常请求,然后进行Set-Cookie,然后浏览器就包含了cookie信息,然后从第二次访问开始,在进行刷新的时候,我们就会发现请求中就会带上Cookie属性。以后每一次请求,浏览器都会自动检查你访问的这个网站,也叫作你访问的域,只要这里有cookie都会自动给你把cookie携带上。


所以只要你访问的是目标的网站,浏览器会自动把你曾经给这个目标网站对应的浏览器内部写入的cookie信息给你携带上,作为请求的一部分。你想设置cookie,我们的选项就是Set-Cookie: ...
你登录任何网站的时候,只要你登录上了,一定会有cookie正在使用,如果你不想让他认识你了,你把这个cookie信息移除掉,再次刷新网页,它就不认识你了,如果你把这个cookie一直保留着,此时对应的浏览器向任何目标网站发起对应请求时,请求里面都会携带上Cookie字段,然后支持服务后端对你的身份进行多次认证,每一次都要进行认证。
类比生活:当客户端第一次请求时,服务端说给你个工牌,你把它保存好,以后你再出入我这个服务器的时候,你都把这个工牌带上,客户端说:好的。再比如:你去了腾讯,当你入职第一天,你的领导就给你一个工牌,以后进公司就没有人拦住你了,第一次请求的时候就相当于你入职的过程,往后你每天上班,带着你的工牌,也就是每次发起请求,服务端也就是保安总是认识你,因为它发现你带着工牌,它可以核实你的信息。这就是为什么网站认识我。
cookie文件的存在形式
它有两种存在形式:
1.文件版,如果是在文件中,那么它就是在浏览器的安装目录下,以及它使用的某些相关的用户级目录下,他会把用户对应的cookie信息保存在文件里。即便你把电脑关了,你再去访问目标网站,这个cookie信息他还能知道。
2.内存版,意思就是说,浏览器一关闭,访问的目标网站就不认识你了。
cookie的安全问题
我今天把登录把账号密码输入给服务器,服务器认证通过后,给我返回登录成功请求,然后我本地就把账号,密码这样的私密信息更新到cookie里面,包括我的浏览痕迹等。目前最私密的就是账号,密码。如果今天我不小心点击了恶意网站,这些恶意网站今天向我的浏览器端注入了一些木马程序,盗取了我的cookie文件,然后别人把这个cookie文件放在他自己浏览器的特定目录下,然后访问和我访问一样的网址,此时因为有cookie信息了,他就可以以我的身份访问目标网站了。所以这就是大部分人被盗取账号的底层重要的理论。
如果别人盗取我的cookie文件有两个安全问题:
1.别人可以以我的身份进行认证访问特定的资源
2.cookie如果保存的是我的用户名和密码,那么这个账号就直接泄露了。
单纯使用cookie是具有一定的安全隐患的。
比如:你自己的账号经常被盗。当你在你的电脑上登录QQ 的时候,QQ的服务器是如何知道你是登录状态,它如何维持它的会话保持呢,包括你只要登录上你的QQ,我要访问QQ邮箱等一些其他功能,基本上都是以我当前的这个账号就进行访问了,也就是访问其他功能就不需要我再次输入账号密码了。QQ的好多功能都是相互打通的,就是因为你在登录你的账号的时候,它也会形成对应的cookie信息保存在它自己的服务当中。就比如你访问QQ空间,然后就自动打开了浏览器,浏览器为什么知道是你这个人的QQ空间而不是其他人的,说明你在登录状态打开QQ空间的时候,QQ的请求就自带cookie信息了,说明cookie信息早就被保留了。这也说明当你在访问恶意网站的时候,别人盗取了你的cookie信息,别人就可以以你的身份访问你的QQ空间了,甚至登录你的QQ,然后就可以访问你的资源了。
别人盗取我们的cookie信息现在仍然存在,信息泄露的问题也是永远解决不了的,安全级别更高,那么攻击手段就越强。所以才有了各种各样的杀毒软件,对我们的软件进行保护,我们的服务器也有自己的安全策略,但是这样的问题依旧避免不了,只要用cookie,信息就有泄露的风险。
这两个问题,最严重的是第二个问题,我的身份认证信息泄露了其实也不影响,比如你的QQ被盗了,以你的身份行骗,但是你的人际关系不好,没有人借给你钱,这样也算从另一个维度保护了账号安全。最严重的是个人私密信息泄露了,用户名,密码,浏览痕迹都会被泄露,这是很危险的,我们要想办法把这些私密的信息保留起来的,所以我们今天有了一个新的技术,就叫做session。
现在市面上主流的使用方式是cookie+session。但是session是没法举例的,因为session的实现是需要服务端有更多的实现方案的,session的代码量太大了,我们没办法实现。
session
核心思路:将用户的私密信息,保存在服务端。
为什么私密信息会被盗取呢?
因为你是个普通小白,作为普通的用户,你的私密信息是所有的恶意分子想要的并且你的防护级别很低。所以有些人就喜欢安装些杀毒软件,但是这些软件的级别也不够。因此衍生出session。
当你登录某个网站的时候,一定携带用户名+密码,服务端首先就要先认证,认证通过之后,构建一个响应告诉你认证通过了,客户端这里就可以通过服务端给的Set-Cookie命令,然后把个人认证的信息保存起来。这是我们刚刚所说的。
session处理策略

现在,服务端认证通过后,在服务端的磁盘上(直接理解成linux的目录中)就形成一个session文件,这个session文件比如说叫做123,这个文件里面保存的就是该用户的私密信息,用户名,密码,浏览痕迹...然后服务端进行构建http响应,构建响应的时候,需要设置Set-Cookie:session_id=123。换言之,依旧会给客户写回一个cookie值,这个cookie值照样会正常的保存在浏览器的cookie文件中,只不过这次保存的cookie文件里面,只有一个数字,叫做123,我们把这个123称为当前用户的会话id(session id)。如果这个网站有100个人访问,那么每一个人都要形成一个session文件,这个文件的文件名必须具有唯一性,所以这里的session id 在服务端一定是一个具有唯一性的值。也就是有100个人,每一个人都会形成唯一的session文件,每个人的session id都不一样,这个是可以通过算法解决的(比如文件名,我们就可以把时间戳带上,然后给每个人添加一个递增编号,组和就形成了唯一值)。此时响应回去照样写cookie,只不过这次的cookie里面保存的就是用户对应的session id。所以后续所有的关于server的访问,所有的http请求,都会由浏览器自动携带cookie文件中内容(就是当前用户的session id)。当服务端搜到客户发来的session id ,它对用户的身份认证,就不在需要用户名,密码了,只需要确定session id 有没有在服务端中,只要通过session id找到对应的文件,就能找到用户的私密信息,从而对用户做认证。后续,server依旧可以做到认识client,这也是一种会话保持的功能。换言之,我们应该看到所有的客户端访问服务器上所有的请求,包括看所有视频,所有的网页,只要你曾经登录过,往后server端就可以根据你的session id来确认你的存在。
cookie安全的第一个问题
因为客户端的cookie里面不在保存用户任何的私密信息,所以也就杜绝了,即便是用户他将自己的cookie文件泄露了,也不会导致用户的私人信息被泄露。但是,我们还有cookie文件被泄露的风险,这个问题是无法被杜绝的,因为这个cookie文件是在用户的电脑上,用户没有防护意识,用户电脑上它被盗取几乎是必然的,所以是没有办法解决的。这也就是为什么腾讯这么大的公司,它的QQ照样还能被人盗取,解决不了。
cookie安全的相关策略
cookie文件被泄露了,别人拿着我的cookie文件去访问曾经这个cookie对应的网址,别人就冒充我的身份了,这个也是只能解决cookie安全的第二个问题,cookie安全的第一个问题照样没法解决。
但是可以有一些衍生的防御方案了。比如:你的QQ,如果你跨越地区了,你的QQ就会提示你当前QQ登录地点异常,请确认是否是本人操作,包括用一台新设备登录也是如此...这是因为ip地址是可以确认出地域的,比如:最近的好多软件,如果你评论的话是会显示你的对应的地址的,这就是通过ip的归属处理的,不同种类的ip隶属不同的片区,所以通过ip就能确认地区。每次登录QQ就对你的ip做认证,如果你的QQ被盗了,假如你是山西的,盗取你QQ号的人是缅甸的,那么1分钟前你还在山西,1分钟后你就在缅甸了,此时QQ就立马识别到用户异常,然后让你重新登录,让你重新登录的本质是废弃掉刚刚的session id,重新给你形成新的session id。所以一旦重新登录了,对端的session id也就失效了。
再比如:如果我是一个不法分子,我盗取了你的账号,以你的身份访问了某些网站,我最想做的事情不是立马试试诈骗,我最想做的就是把你这个人的用户名和密码改掉,让这个账号永远是我的了,但是这种情况是不可能存在的,因为诞生了一个新的设备--手机,所以以前没手机的时候,我们用的是邮箱认证,现在有手机了,如果你要改密码,第一件事情永远是输入旧密码,第二件事情如果你的登录地址有异常,或者它的审核标准比较严,还需要你进行短信认证。也就是数据层面上你把cookie文件丢了,但是手机没丢,即便是手机也丢了,手机和cookie都被同一个人拿走了,你手机也有密码。短信上面的认证,就相当于,即便你的信息被盗取了,他要改你密码,他也改不了,这也就是一般你的账号被泄露或者盗取,我们经常说的申诉,就是重新认证你,因为是账号的拥有者,当初绑定的是你的手机号,所以最后可以通过手机进行二次认证,使别人盗取到的cookie信息失效就可以了。所以只要session id是server去指派的,它的session id管理工作是由server去做的,虽然你的客户端保留了一个session id,但是server随时可以让这个session id失效,让别人盗取也没有意义,所以就可以有各种各样的策略,比如异地登录,短信认证,包括QQ检查内容,一旦发现有些账号有异常行为,比如频繁添加好友...侦测之后,就可以强制用户下线,强制用户下线也很简单,只要在服务端把对应的session 文件干掉。这就是cookie与session。
再谈http无状态
再来看看最开始的问题,网站是认识我的,但是http是一种无状态的协议,也就是你请求什么网页,请求前,请求后和我没关系,http只是你告诉我要什么,我给你拿什么,哪怕是上次刚要过,这次还要要,我也会给你拿,这就是http的无状态,它不记录用户的任何行为,但是网站是需要认识这个用户的。
为什么网站需要认证用户,也就是为什么登录这个网站的时候它需要永久的认识用户呢?
因为http无状态,所以今天你登录成功了,如果我的网站不认识你,你只在访问该页面的时候,它认识你,但是我一旦点击一个新的页面,查看一个新的视频,那么对不起,你要先输入用户名和密码你才能看,你要手动进行一次认证,换言之,引入cookie+session本质就是为了提高用户访问网站或者平台的体验!你只要登录我的网站,所有内容你都可以随便访问,当然增强用户体验就是上下文要记录用户的状态,而http是无状态的,所有就有了cookie和session来解决这个问题。
HTTPS
http的信息在互联网中传送基本就是数据在互联网中裸奔,别人想在随时随地想抓取你的数据就能抓取。局域网通信本质上就是你发收到数据和你在同一个局域网的所有人都能够看到,只不过别人不处理罢了,所以局域网通信本质就相当于有两个人在自认为双方在通信,实际上有一大批吃瓜群众在 围观,如果你不加密数据本来就是在裸奔,这也就是不管用POST还是GET方法都解决不了的,我们只能对网络数据进行加密。自从中国互联网因为以前的互联网巨头出现了很严重的安全隐患,我们国家的互联网从安全领域就变的越来越重视了,现在你访问的所有网站都是HTTPS
eg:你现在能叫上名字的所有网站全部是HTTPS
像我们自己搭建的浏览器就提示是不安全的


背景认识一
https其实是http+TLS/SSL。TSL/SSL简单的理解成http数据的加密解密层,这一层也是软件层。

我们使用http然后直接使用系统调用就叫做http,如果我们使用http,然后向下访问时不直接访问系统调用接口,而是访问一些安全相关的接口,然后再用安全访问的相关层在访问系统调用接口,在把数据发出去,因为http的请求和响应都要经过这个加密解密层,所以请求时完成了加密,响应时完成了解密,这个协议就叫做HTTPS。因为这里的TLS/SSL是属于应用层协议,也就是说它只会在客户端和server端两端出现,换言之也就意味着我们的数据在网络中总是被加密的(对于下三层数据是没有被加密的,也不需要,你加密主要是为了保护用户的隐私,所以只要把应用层数据加密就可以了)到了对端,对端向上贯穿的时候也会自动进行解密,所以同样的在http依旧是请求和响应,就是加了一层软件层。
实际上在网络里,是整个http请求+有效载荷被全部加密了,当然有些版本只对有效载荷加密,因为http本身就是一些私密信息,但只要服务器和客户端双方认识就可以,其实http的报头也可能包含用户私密信息(eg:session id),一般是对整个http进行加密,加密后交付给下层去传输,然后到对端解密,出来之后就是http,相当于在同层看来依旧正常通信,没有加密解密的过程。
背景认识二(数据的加密方式)
1.对称加密
这里有个秘钥的概念,这个秘钥只有一个,比如说秘钥是X,所谓的对称秘钥就是用X加密,也要用X解密。就像你家里的门钥匙,锁门你用这个钥匙,开门也用这个钥匙。
假设现在有个数据data;
data 异或 X = result;
X 异或 data = result;
你要发的数据是12345,实际发的是12644,服务端收到后进行解密就是12345。所以曾经学的异或运算,让不同数字异或同一个值(src_key),这样的src_key就称之为对称秘钥。
对称加密就是使用同一把秘钥进行加密,解密。异或其实就是一种简单的加密算法。

2.非对称加密
有一对秘钥:分别叫做公钥和私钥。可以用公钥加密,但是只能用私钥解密;如果用私钥加密,只能用公钥解密。你必须用一个加密,另一个解密,这就叫做非对称加密,最典型的非对称加密算法常见的就是RSA。
一般而言,公钥是全世界公开的,私钥是必须自己进行私有保存的!也就是私钥不能暴露给外部,你必须自己保存起来。
背景认识三
假设现在有一篇论文,那么如何防止文本中的内容被篡改?以及识别到是否被篡改?
 我现在需要有一个方法来甄别是否有人改过这篇论文,哪怕是改过一个标点都不行。我们这篇文本的文本量是可大可小的,我们可以针对该文本进行Hash散列,形成固定长度,唯一的字符序列。这种算法的特点就是对文本进行任何改变,哪怕是一个标点符号,都会形成一个差异非常大的hash结果!也就是说,我选择的hash散列算法,如果文本有一点点不一样,那么形成的字符序列的变化就特别大。最典型的这样一个算法时md5。所以我们把这个固定长度,唯一的字符序列我们称之为数据摘要或者叫做数据指纹。然后我们再采用加密算法(一般是非对称的),我们将这个固定长度,唯一的字符序列在进行加密,得到加密结果,这个加密结果我们一般把它叫做数字签名。
我现在需要有一个方法来甄别是否有人改过这篇论文,哪怕是改过一个标点都不行。我们这篇文本的文本量是可大可小的,我们可以针对该文本进行Hash散列,形成固定长度,唯一的字符序列。这种算法的特点就是对文本进行任何改变,哪怕是一个标点符号,都会形成一个差异非常大的hash结果!也就是说,我选择的hash散列算法,如果文本有一点点不一样,那么形成的字符序列的变化就特别大。最典型的这样一个算法时md5。所以我们把这个固定长度,唯一的字符序列我们称之为数据摘要或者叫做数据指纹。然后我们再采用加密算法(一般是非对称的),我们将这个固定长度,唯一的字符序列在进行加密,得到加密结果,这个加密结果我们一般把它叫做数字签名。
我是一个通信端,我现在要发送这段文本,我怎么保证这段文本没有被篡改?
我就可以在发送的文本当中把原始文本带上,另外在文本的尾部带上该文本的数据签名,最后在我们在网络里,就把它俩作为一个整体发送出去,当接受端收到数据,就要确认这个文本是否被篡改。

校验
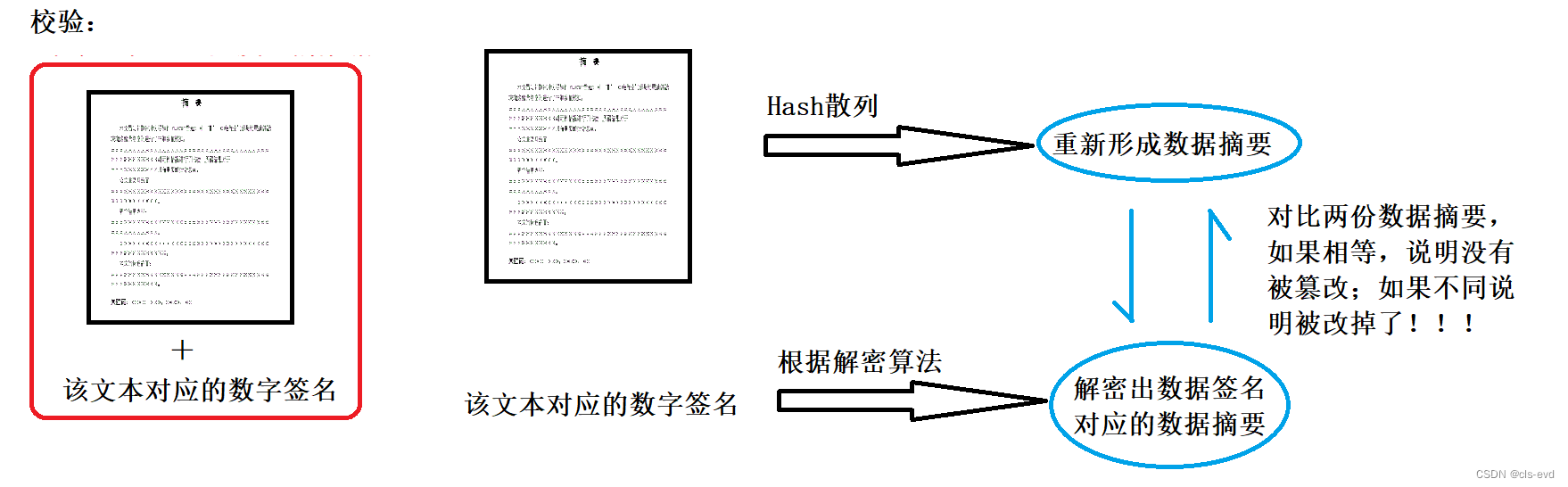
1.从接收到的数据中把原始文本拿出来,紧接着对原始文本采用相同的hash散列,对于这段文本重新形成数据摘要。
2.把数据签名拿出来,根据解密算法,把这个数据签名解密出数据签名对应的数据摘要。
然后对比两份数据摘要,如果相等,说明没有被篡改,如果不同说明被改掉了!
https是如何通信的呢
首先我们进行通信,双方的数据是必须得被加密的。既然加密,也必须解密。
如何选择加密算法
1.对称加密
2.非对称加密。
如果我们选择对称加密,假如客户端用X秘钥进行加密,那么server端怎样得知这里要用X秘钥解密呢,反过来也一样,如果server端给客户端发消息,server端用X秘钥加密,那么客户端如何得知X呢。
方案一
预装。也就是我们给服务端和客户端把世界上所有采用的对称加密的秘钥信息都给他俩预装好,在你开始买机器的时候,天然就有了,这样的话双方就可以直接用了。
但是这样有几个问题:
- 预装的成本太高了。
- 如果我没有预装,就得进行下载,我下载的时候就要把一些软件及秘钥的相关信息全部下载下来,还是在网络上跑。
- 既然这个信息已经被预装了,那么代表别人也能预装,如果你的秘钥是明文,那么别人也就知道了,如果你的秘钥是暗文,那么对这个暗文也需要进行解密,然后就有非常大的鸡生蛋,蛋生鸡的问题。
- 所以这个预装是非常的不靠谱的,是不行的。
方案二
对称加密
双方通信的时候协商秘钥。这种方案看起来可行,假设服务器现在并不知道秘钥是什么,客户端形成了一个秘钥X,然后因为是对称加密,所以它发过去的数据加密是需要被server知道的,所以它需要把自己的X交给https,所以就进行通信,但是第一次决定是没有加密的。就是说客户端告诉服务端,我要用X进行加密,我把X先给你,你一会用X进行解密,这里就特别搞笑,因为第一次传送第一条数据的时候,服务端还没有收到X,所以客户端不能进行加密,因为客户端一加密了,对方就不知道了,所以客户端的第一条消息必须是把秘钥以明文的方式发送过去,这里就很尴尬,我把秘钥以明文发送过去,如果这个秘钥信息被盗取了,后续双方进行加密通信就没有任何意义了。说明在刚开始通信时,协商秘钥阶段,采用对称加密的方式是根本不可能的。

秘钥协商,采用对称方式是绝对不可能的!
非对称加密
我们采用非对称方式加密,我们用S表示公钥,S^表示私钥。
当客户端请求服务端的时候,服务端首先进行秘钥协商,服务端把他的公钥S给客户端,此时客户端就拿到了一个公钥S,紧接着客户端拿到了公钥S之后,用公钥S对数据进行加密,此时客户端在把加密号的数据发送给服务端,所以客户端发出去的数据是用服务端提供的公钥S进行加密的。因为这个世界上只有server具有私钥S^,也就只有server能进行解密!如果其他人拿到了这个数据也是没办法的进行解密的,因为其他人没有私钥S^。此时服务端收到加密数据根据私钥S^,解密出data,就拿到了数据。换句话说就是server端把公钥暴露给了全世界,全世界的客户端都能拿到公钥,但是任何人拿到公钥一旦加密,那么除了服务端没有任何人可以解密。所以经过这样的方案,我们就能保证数据从客端传输到服务端的安全。但是从服务端到客户端,是不能用私钥S^加密的,因为一旦用私钥S^加密,那么只能用公钥S解密,可是全世界都知道公钥S,所以从服务端发送给客户端的数据就是不安全的。也就意味着如果只要一对公钥和私钥只能保证单向数据安全。
那么我们给客户端一对公钥和私钥,给服务端一对公钥和私钥,在通信阶段,提前交换双方的公钥,就能保证双向数据安全。
既然一对非对称秘钥,可以保证数据的单向安全,那么两对就可以保证数据的双向安全了。

两对非对称秘钥的问题
但是事实并非如此!!!
- 依旧有被非法窃取的风险,暂时先不谈。
- 非对称加密算法,特别费时间!就是因为这一点,这种方案就几乎已经不被采纳了。对称加密是比较省时间的。
所以在我们实际进行http通信的时候,我们根本就不是采用纯对称或者纯非对称,纯对称有安全隐患,纯非对称有效率问题。
实际中的加密方法
实际中采用的是非对称+对称方案!
当客户端发来一个请求,服务端是有自己的非对称的公钥S和非对称的私钥S^的,当客户端一旦分发起请求,服务端给客户端进行响应的时候,服务端就将自己的公钥给客户端,客户端就收到了公钥S,接下来,客户端形成对称秘钥的私钥X,然后客户端用公钥S对私钥X进行加密形成X+,然后客户端把经过加密的对称秘钥的私钥交给服务端,这个世界只有服务端有S^,所以只有服务端能用S^对X+进行解密,然后就得到了X,所以server就以安全的方式拿到了客户端发来的对称秘钥的私钥X,然后这个阶段完成后,因为客户端和服务端都知道了对称加密的X,所以他俩就采用对称方案进行数据的加密和解密。
将对称秘钥发送个对方叫做秘钥协商阶段,采用非对称算法。
利用对称秘钥传输数据叫做数据通信阶段,采用对称加密。

什么叫做安全
不是让别人拿不到就叫做安全,而是别人拿到了,也没办法处理。只要别人有一点点可能性能侦测到你的数据,你就要把这种可能性无限放大,这就是安全意识,小小的漏洞都要认为它是一个普遍问题。你的数据是随时随地都能被别人抓到的。只要你的数据在网络里跑,别人据一定能拿到。现在的问题是数据加密了,能解开就是不安全的,解不开就是安全的 。
在安全层面,解密的成本远远超过了解密后带来的收益就是安全的。
比如:别人出价10块,让我破解你的信息,但是我破解你的信息要花费10000,如果我不考虑成本,我一定能破解,但此时考虑了成本,我是不会进行破解的,此时就称你的数据是安全的,因为我破解了是没有任何意义的。这是以经济角度谈的。如果信息涉及到了国家安全,那么它就不是钱能衡量的,那么这个时候它的安全级别必须是特别特别强的,你要攻克我,可能要用一些超级计算机得几百上千年才能运算出来,这也就是为什么我们国家搞的一种量子计算机国外非常害怕,因为量子计算的运算能力是比现在的二进制计算机的效率高了几万,几十万,甚至几百万倍,所以本来破解一个密码需要1个月,现在就可能只需要几秒钟,一瞬间就把你建立好的安全全部破解了。
中间人
客户端和服务端之间的数据被中间的某些用户查看,阅读,甚至篡改,这种攻击手法我们称之为中间人。
那么在服务端把公钥给客户端的时候,可不可能出现问题呢?
在网络环节中,随时都有可能存在中间人来,偷窥,修改我么的数据。服务端在给我们客户端发送自己的公钥S(这也是一段报文或者是一段数据),假设此时出现了个中间人(一台监听设备),这个设备内部也有自己的公钥M,私钥M^,服务端发送的公钥S,是大家随时随地都可以获取的,只不过这个中间人做了一个工作,它将服务端发送个客户端携带公钥S的报文拿到,然后把自己的公钥M替换了服务端的公钥S,然后把包含公钥M的这个报文发送给了客户端,此时客户端并不知道中间人把服务端发给自己的报文篡改了,所以客户端就认为自己收到了一个公钥M,然后形成自己的对称加密的私钥X,将X通过M进行加密形成M+,然后客户端就把M+发送给服务端,可是中间人又把这个M+截取到了,因为你用的是中间人的公钥M,所以中间人就用私钥M^进行解密,然后就拿到了客户端和服务端进行通信的对 称加密的私钥X。然后中间人就把这个私钥X保存在自己的系统里,然后把解密出的数据私钥X重新用公钥S加密形成S+,然后把这个S+在交给服务端,此时服务端和客户端都认为自己交换成功了自己的秘钥,可此时中间人也拿到了服务端和客户端通信对称加密的私钥X,这样中间人就顺利成章的得到了双方通信的数据。
本质问题:客户端无法判定发来的秘钥协商报文是不是从合法的服务方发来的!!!!
证书
所以这种方案目前就无解了,别人想怎么搞你,就怎么搞你,所以当人们意识到这种攻击收发会让很多人无所适从,所以我们的网络中就出现了一种非常重要的机构:CA证书机构。
证书是什么
在生活中,我是用人方,你怎么证明你是一个大学生呢,我们就可以通过学校颁发的学位证进行证明,为什么信任各大高校呢,因为各大高校本身就有国家教育部在后面支持,所以只要一个服务商经过权威机构认证,该服务商就是合法的。
比如这个服务端是一个正规的公司的网站,这个服务商首先向CA机构申请证书,申请证书需要提供企业的基本信息,域名,公钥。CA机构拿到你的申请,给你进行创建证书。
CA机构
1.很权威
2.CA机构有自己的公钥A,和私钥A^。
ps:公钥和私钥只是一种算法,任何人都可以有,一点也不值钱。
创建证书
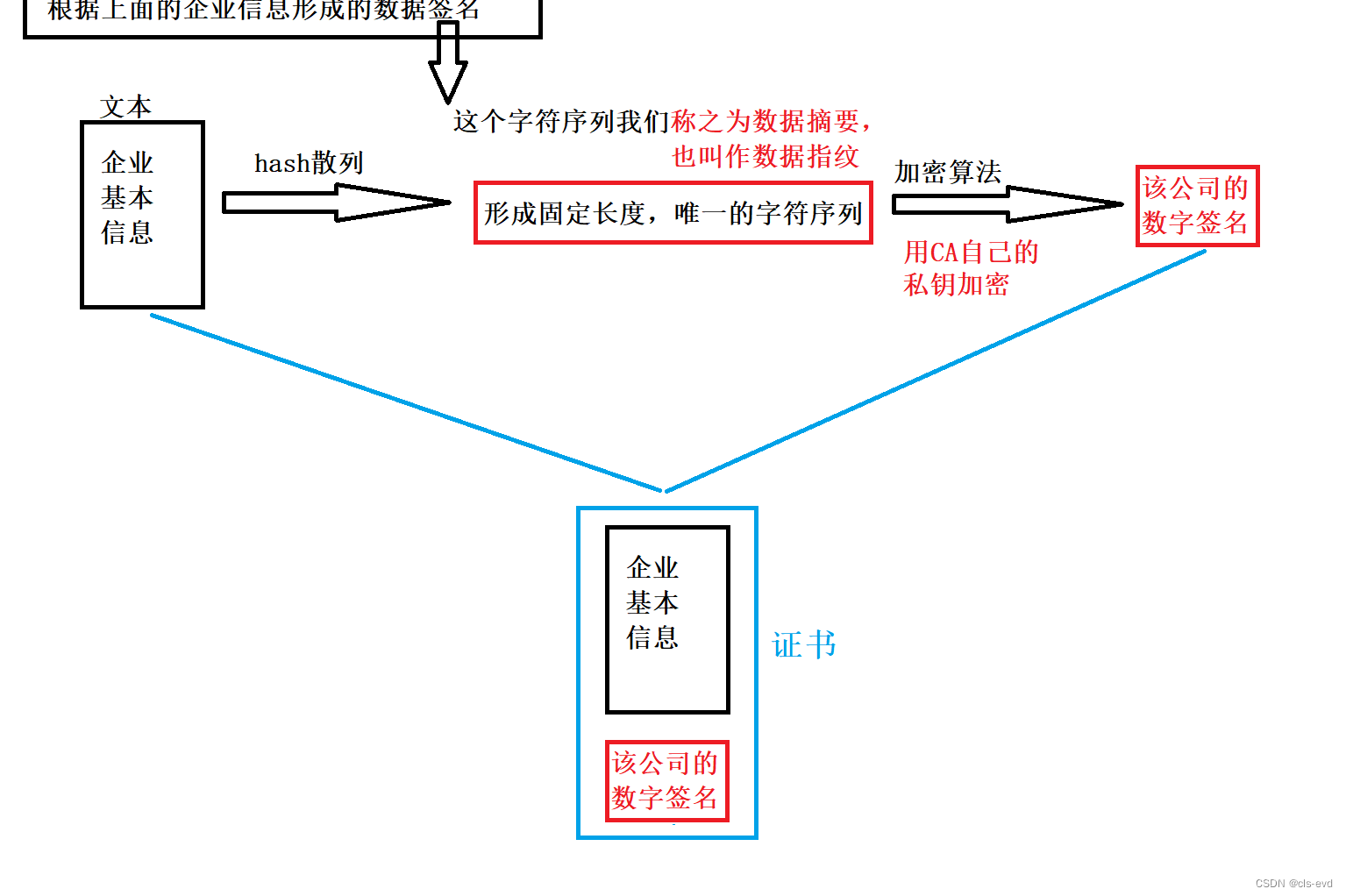
创建证书的时候,要有企业的基本信息{域名+公钥(这个公钥与CA机构没关系,是服务器发送给客户端的公钥)},这个企业的基本信息就是一段文本。所以我们根据企业信息形成一个数字签名。
回顾下数字签名形成:这个企业文本经过hash散列形成数据摘要,然后用CA自己的私钥加密,形成该公司的数字签名。 我们把公司基本信息+公司信息的数字签名统称为CA的证书。然后再把这个证书颁发给企业,这个证书里面就包括了公司的基本内容+域名+公钥+公司基本内容的数字签名。
创建证书
CA机构流程

有了证书后,请求该怎么做呢?
客户端发起一个请求,服务端就要把秘钥返回给客户端了,以前就是直接把公钥返回给它,现在就是把证书信息返回给客户端,假如现在中间人就截取了你的证书了,但是现在中间人就不能将服务端的公钥替换成自己的公钥了,因为域名,公钥,基本信息都是明文传送,所有人都能看到,但是人家带了数字签名。当客户端收到证书时,它会把文本内容和签名内容拆出来,然后使用相同的散列算法(这个算法也可以体现在证书上)对该文本进行形成摘要,如果中间人对公钥进行篡改,那么形成的摘要就不是服务端发过来的,而是新的中间人篡改后的摘要, 这样就和解密后的数字签名对不上了。
 数字签名中间人改不了吗?
数字签名中间人改不了吗?
是的!中间人是改不了数字签名的,因为数字签名我们用的是CA机构的私钥进行加密的(当然任何一个人都可以用CA的公钥解密) ,中间人是没有CA机构的私钥的,CA机构的私钥只有CA机构知道,也就是只有CA机构能重新形成对应的数字签名。所以中间人解密出来后,因为没有私钥,也就没办法进行重新生成数字摘要。
如果中间人也是一个合法的服务方呢?
我这个中间人,我也向CA机构申请,CA机构也给我颁发证书,身为中间人的我也就有了合法的证书,我直接把服务端的整个证书报文全部全替换掉,用成中间方的,这样行不行呢?
答案也是不行的,因为证书的基本信息里有一个域名,如果是合法的中间人,你的域名一定和客户端请求的域名一定是不一样的,正如中间人不能改你的域名,不能进行任何篡改,一旦改了就会被侦测出来。换言之,中间人将证书全部替换后,到了客户端,客户端进行秘钥解密的时候,发现一些列都对,但是客户端我原本请求的域名是www.123.com,但现在怎么变成了www.zhongjianren.com了,目标地址发生变化了,我客户端就不相信它了。
所以无论中间人怎么改这个证书,它都改不了!!!
我们认证一个证书是对原始内容进行散列,因为原始内容和散列算法本来就是公开的,我们直接用就可以,关键是对数字摘要解密。所以要求客户端必须知道CA机构的公钥信息。
客户端是如何知道CA机构的公钥信息呢?
1.一般是内置的!相当于你在下载浏览器的时候,这些浏览器本身就已经内置了很多的公钥相关的信息。
2.访问网址的时候,浏览器可能会提示用户进行安装。但这种出现的后果就需要用户自己承担。大部分情况下,我们见到的很多网站,很少提示你让你重新安装证书的。99%情况下直接访问网站,除非它是不合法的。
我们主流的方案是第一种,你的windows操作系统和浏览器都内置了很多的CA机构,这个是软件发布的时候厂商就内置好了,默认下载就有了,涵盖的就是CA机构相关的公钥信息。有了公钥就可以对我们对证书的合法性,是否被篡改做些对应的判定。
查看证书
受信任的根证书颁发机构,这就是默认设置好的。中间证书颁发机构:就相当于受信任的根证书颁发机构 信任 中间证书颁发机构,因为我们信任根证书机构,只要根证书颁发机构信任的,我们也信任。

传输层
再谈端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序;
比如:主机A在通信的时候,它的服务器上可能部署了大量的服务,我们的HTTP默认绑定的端口是80,这个端口不能改变,这是服务端口,必须是众所周知的。HTTPS默认的端口是443。底层收到的数据它的报文中会通过ip来标定是哪台机器,但这台机器上有众多的服务,我们就根据端口号进行交付。所以套接字通信的本质其实是进程间通信,ip标识唯一的主机,端口标识该主机唯一的一个进程。


端口号范围划分
- 0 - 1023: 知名端口号, HTTP, FTP, SSH等这些广为使用的应用层协议, 他们的端口号都是固定的.
- 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的.
认识知名端口号(Well-Know Port Number)
有些服务器是非常常用的, 为了使用方便, 人们约定一些常用的服务器, 都是用以下这些固定的端口号:- ssh服务器, 使用22端口
- ftp服务器, 使用21端口
- telnet服务器, 使用23端口
- http服务器, 使用80端口
- https服务器, 使用443
cat /etc/services我们自己写一个程序使用端口号时, 要避开这些知名端口号
两个问题
1. 一个进程是否可以bind多个端口号? 可以 2. 一个端口号是否可以被多个进程bind? 不能pidof
在查看服务器的进程id时非常方便. 语法:pidof [进程名] 功能:通过进程名, 查看进程id
netstat
netstat是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项:- n 拒绝显示别名,能显示数字的全部转化成数字

- l 仅列出有在 Listen (监听) 的服物状态
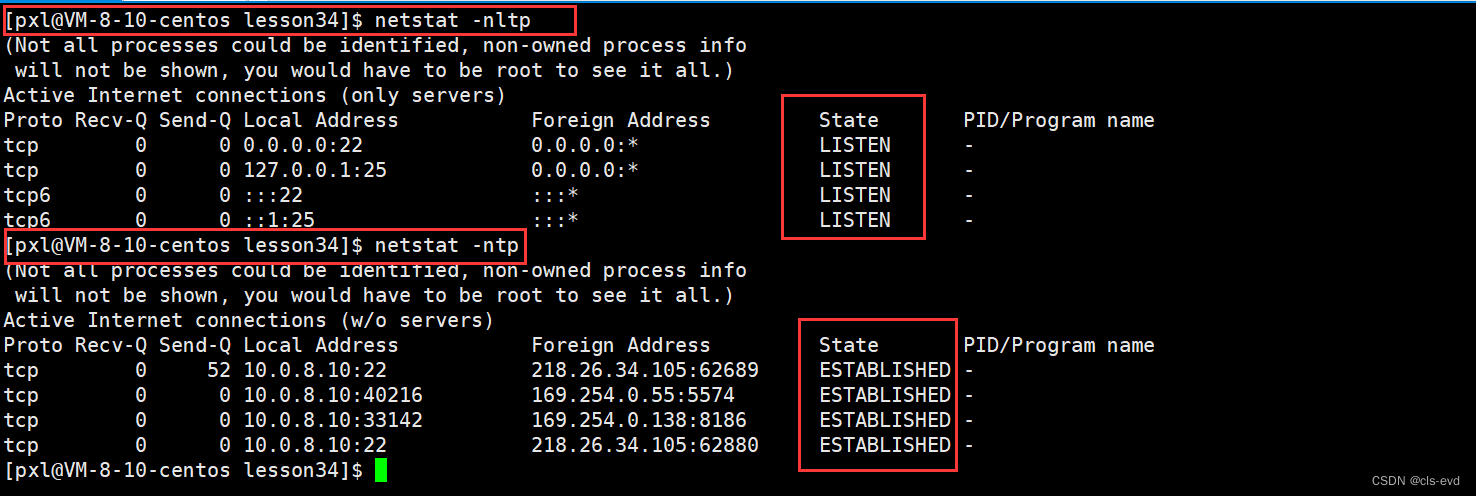
查普通状态的套接字不带l
- p 显示建立相关链接的程序名
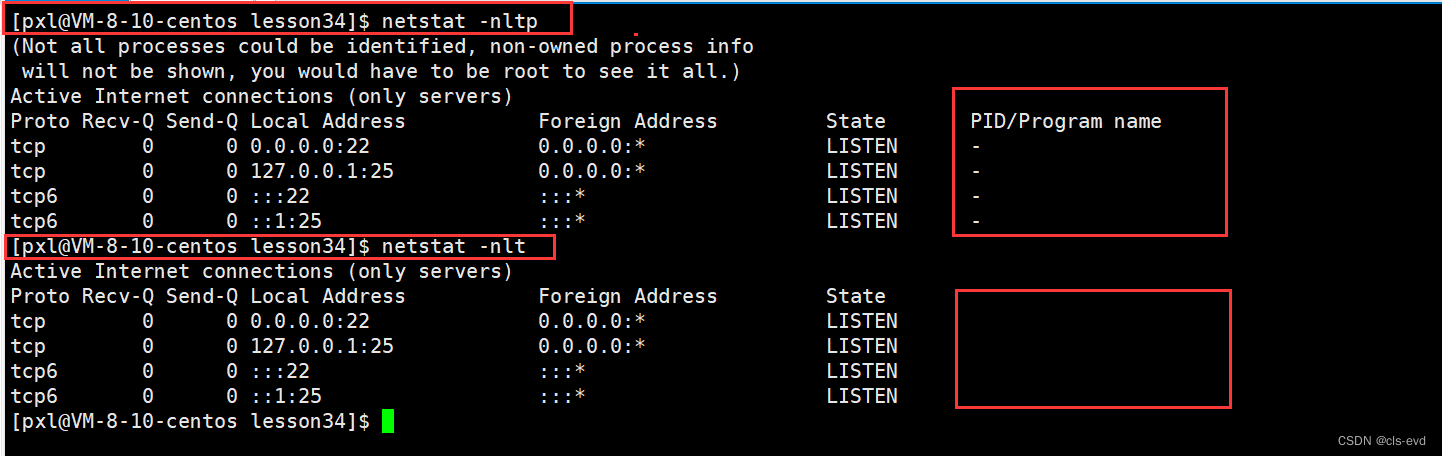
- t (tcp)仅显示tcp相关选项

- u (udp)仅显示udp相关选项

- a (all)显示所有选项,默认不显示LISTEN相关
我们最常用的还是
netstat -nltp
UDP协议
UDP协议端格式
应用层用的就是传输层的接口。传输层最简单的协议就是TCP和UDP。TCP和UDP一定是对上提供对应接口的东西,让应用层可以直接调用。
UDP的报文是这样的
UDP的报文结构的宽度是0-31,16位的源端口,16位的目的端口代表的是上层的应用程序它的源端口是什么,到了对端之后,它的目的端口又是什么,双方在通信时,源端口和目的端口就表明了我这个报文是上层的应用程序哪一个程序发的以及要发到哪一个程序当中。然后还包括一个16位的UDP长度,16位UDP长度指的是整个报文的长度,而UDP的报头长度是定长的(8字节)。

对于16位UDP长度的理解
16位的源端口,16位的目的端口,16位UDP长度,16位UDP校验分别都是2个字节,分别是UDP报头的4个字段,他们组成UDP的报头,一共8个字节。
这里的16位UDP长度:代表的是UDP整个报文的长度一共是2^16=65536字节,也就是64k。描述16位UDP长度的这个字段占2字节,也就是说以后在填写UDP报头的时候,你可以在这里填写一个0~65536的一个数字,单位是字节。
UDP如何做到封装和解包的?
UDP的封装就是添加上定长的报头;当它要解包本质就是将自己的报头和有效载荷做分离,所以我们读取UDP定长的报头,剩下的就是有效载荷。
UDP如何做到向上交付(分用问题)?
a.报头和有效载荷分离
b.根据目的端口号,交付有效载荷给上层应用
UDP的报文有一个16位的目的端口号,代表的是当这个报文被目标主机收到以后,会根据16位的目的端口号,交付给应用层对应的进程,其中会把数据交付给上层程序。
我们写代码的时候为什么需要绑定端口号?
就是因为当底层收到了对应的UDP报文,它会根据报文的目的端口号,把数据转给特定的绑定目的端口号的进程。
端口号为什么是16位?
我们之前UDP/TCP 套接字,端口号一直是uint_t 16 ,因为这是协议规定的。
Linux内核是C语言写的,请问如何看待udp报头?
所谓的报头就是一个结构体
struct udp_hdr{unin32_t src_port:16;unin32_t dst_port:16;unin32_t total:16;unin32_t check:16;
}
//:后面的数字用来限定成员变量占用的位数。所以经常说的给udp报文添加一个报头,就是拿着结构体定义一个对象,把这个对象的数据一填写,然后和上层的数据一拷贝,形成一个报文,然后就可以发了。
UDP的特点
UDP传输的过程类似于寄信.
- 无连接: 知道对端的IP和端口号就直接进行传输, 不需要建立连接;
- 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方, UDP协议层也不会给应用层返回任何错误信息;
- 面向数据报: 不能够灵活的控制读写数据的次数和数量;
面向数据报
UDP本身报文大小并不大,而且它是一个报文,一旦整个报文被你全部收到了,因为UDP是在底层协议,是属于传输层的,数据在读取时是应用层在调用系统调用接口把数据读上来。当应用层在读数据的时候,整个UDP可能有多个报文,而作为应用层要么就不读,要读就把完整的一个报文全部读上去。换句话说就是我们之前写的UDP套接字,客户端send多少次,服务器就必须recv多少次。客户端send的每一个报文,服务器在收的时候必须全部收到,要么干脆就不收,要么收就要全部收到。这种特点就叫做面向数据报,这样的UDP报文就是原样发,原样收,既不拆分,也不合并。这个就叫做面向数据报。
应用层交给UDP多长的报文, UDP原样发送, 既不会拆分, 也不会合并;
eg:用UDP传输100个字节的数据:
如果发送端调用一次sendto, 发送100个字节, 那么接收端也必须调用对应的一次recvfrom, 接收100个字节; 而不能循环调用10次recvfrom, 每次接收10个字节;
UDP的缓冲区
系统调用接口就是曾经的创建套接字,绑定,监听等这样的一批接口,我们以read/recv,write/send为例,这样的接口参数里面都会涵盖一些缓冲区和缓冲区大小,以及文件描述符。
我们以前认为它的数据是直接发送到网络中,然后由网络发送到对端主机,但这种认识是不全面的,这种接口,文件角度叫做读写,网络角度叫做收发,与其说是收发函数,不如说是拷贝函数!
最终我们的应用层无论是http还是https,还是曾经TCP/UDP传字符串的那些基本代码,本质上是要将自己发送的数据拷贝到TCP/UDP对应的缓冲区里面,TCP具有接受缓冲区和发送缓冲区,当你调用read的时候,其实你并不是把数据从网络里读上来,而是你把数据直接从传输层的TCP的接受缓冲区里拷贝到用户空间;当你写的时候,其实并不是你把你的数据直接发出去,而是把你的数据拷贝到对应的发送缓冲区当中。拷贝完成之后,具体该数据什么时候发,发多少?完全由OS(传输层)控制。
传输层主要解决的就是什么时候发,发多少,已经可能有协议会解决如果发送失败了会怎么班的问题。说白了,传输层更多的给我们提供传输数据的策略!UDP提供的策略就是越简单越好。对我们来讲,传输层提供的一些传输策略对我们后续保证可靠性,各种流量控制滑动窗口,这些机制全部会在这一层实现,具体点就是在TCP中;而UDP几乎没策略,有数据直接发。
因为应用层的各种读写接口,所以我们就不得不谈缓冲区的问题,这个缓冲区存在的价值,一方面要能够让传输层能够定制很多发送数据的策略,另外一方面,它将应用层协议和下层通信细节进行了解耦,应用层只需要把数据拷贝个传输层,因为传输层属于协议栈,协议栈在OS启动就在内存中,说白了,这块就是将数据从内存中拷贝到内存中,效率特别高,接下来的数据怎么发是要经网络的,说白了就是经过网卡,网线去长距离传送的,它比较费时间一些,所以我们只要正常拷贝,具体数据我们拷贝到之后,上层立马返回,就可以直接进行后续处理了,发送的细节就继续由OS帮我们进行把数据发送出去。
- UDP没有真正意义上的 发送缓冲区. 调用sendto会直接交给内核, 由内核将数据传给网络层协议进行后续的传输动作;换言之,只要你的报文交给了OS,OS直接就发了,所以UDP没有发送缓冲区。
- UDP具有接收缓冲区. 但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致; 如果缓冲区满了, 再到达的UDP数据就会被丢弃;也就是说网络把数据读到,它会把数据自底向上的交付给UDP,如果上层还没有调用read/recv接口,UDP会把数据暂存到它自己的缓冲区当中,上层读的时候直接从缓冲区里读上来即可。
UDP的socket既能读, 也能写, 这个概念叫做 全双工。
UDP全双工
什么叫做一个协议通信时全双工呢?
TCP和UDP都是全双工的。
eg:老师上课,老师在说,学生在听,这个就叫做半双工,是老师单向的给学生输出,然后将来学生和老师聊,学生说话给老师的时候,老师也就不说话了,就等学生说完,这就叫做学生给老师输出,我们都叫做半双工。我们两个在聊天的时候,我说我的,我说完了该你说,你说完了该我说,这个是一种交叉式的工作方式,是一种半双工的方式。意思就是说,我们两个在正常通信的时候,我们两个都可以进行发送消息,但是一个发的时候,另外一个人就不能在发了,我们两个就得等一等彼此,这个就叫做半双工。
进程间通信的管道就是最经典的半双工通信,因为它只能单向通信。
全双工就有点像两个人在进行吵架,你说你的,我说我的,我再说的时候,你也在说,甚至你在说的时候,我也在说,我也在听,相当于我们两个在同一个信道当中,我们两个可以同时收发,这就叫做全双工。
所以UDP中,既可以recvfrom,又可以sendto,可以被同时调用;如果我有两个线程,一个专门从文件描述符中读,一个专门向文件描述符中写,这个我们就可以理解成是一种全双工的工作方式。
UDP使用注意事项
我们注意到, UDP协议首部中有一个16位的最大长度. 也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部).
然而64K在当今的互联网环境下, 是一个非常小的数字.
如果我们需要传输的数据超过64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装;
基于UDP的应用层协议
- NFS: 网络文件系统
- TFTP: 简单文件传输协议
- DHCP: 动态主机配置协议
比如说:你自己接入到你家的WiFi的时候,你的手机自动的会获取一个ip地址,这个ip地址的获取其实是你的路由器支持DHCP协议,它能够自动给入网的主机分配ip地址
- BOOTP: 启动协议(用于无盘设备启动)
- DNS: 域名解析协议
当然, 也包括你自己写UDP程序时自定义的应用层协议;
TCP协议
TCP全称为 "传输控制协议(Transmission Control Protocol"). 人如其名, 要对数据的传输进行一个详细的控制。
在生活中我们做事情无非就是两种事情:
1.做决策 2.做执行
eg:公司中,做决策的就是老板,做执行的就是员工。
TCP会定制各种决策策略,我们真正做数据通信的是下两层帮我们去做执行,传输层更多的是定一些策略,当然策略要被执行,也一定要和下层关联起来,就好比你的老板要做一件事情就要和手底下的员工进行沟通。

TCP协议段格式

TCP的标准报头长度是20字节,一行就是4个字节,有5行。TCP也可以携带一些选项,这里我们不谈选项,我们说的是TCP的标长报头。无论是封装,解包,还是向上交付,我们首先都要将它的报头和有效载荷进行分离。
- TCP的标准长度是20个字节。
- 4位首部长度是4个比特位对应的2进制范围,也就是[0000~1111]。这里的首部长度是以4字节为单位的。eg:如果首部长度是1,那么报头就应该是1*4=4,如果首部长度是10,那么报头长度是10*4=40字节。所以首部长度不能只看字面值,还要乘上基本单位。所以TCP报头最大长度就是1111,就是15*4=60字节。又因为标准报头是20个字节,所以选项最多40字节。假设4位首部长度描述的长度是len, len*4=20,所以len就是5,所以默认情况下,在TCP的4位首部长度中,这个字段一般被填充的基本都是0101(5转2进制就是0101)。所以当我们读到一个完整的TCP报文,我提取到它的前20个字节,从20个字节中在分析出报文长度,确定清楚它的报文确实是20个字节,然后就把前20个字节拿走了,剩下的就是有效载荷。所以我们能够让报头和有效载荷进行分离。
- 6位标志位:
- 16位窗口大小: 后面再说
- 16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含TCP首部, 也包含TCP数据部分.
- 16位紧急指针: 标识哪部分数据是紧急数据;
- 40字节头部选项: 暂时忽略;
TCP报头里有一个4位首部长度,能够做到将报头和有效载荷进行分离,只要分离了,报头还包含源端口号和目的端口号,通过目的端口号就可以做到向上交付。
任何协议都要回答两个经典的问题
TCP如何做到封装和解包的?
完整报文就是报头+有效载荷,报头的长度我已经知道了,把报头的长度去掉就是数据,所以我们可以做到对报文进行解包和封装,封装就是添加报头,解包就是去掉报头。
TCP如何做到向上交付的(分用问题)?
分用就是将有效载荷交付给上层,通过TCP的目的端口号就能做到。
总结:通过4位首部长度做到解包和封装;通过16位目的端口号做到向上交付。16位源端口,目的端口表明你的报文从哪个进程来的,要发送到哪个进程当中。
确认应答(ACK)机制
TCP叫做保证可靠性:
要理解TCP的可靠性,必须理解TCP可靠性中最核心的机制:基于序号确认应答机制!!!
eg:常年上网课的我们,当老师说:某某某知识大家听懂了吗?当老师说出去这句话以后,能不能保证这句话被每个相隔千里之外的学生听到了呢?
并不能,因为大家经过长距离传输,就不得不面对一个问题,这个长距离传输的报文在路上丢了怎么办,错了怎么办,其中对方与我相隔千里之外,我是得不到任何反馈的,也就是说老师在说这个话的时候,并不能确定在屏幕前的同学已经收到了这个消息。
可靠性,作为发送方,我想知道的是我发出去的数据,你有没有收到,我把话说了一大堆,我说完了,可是我并不能确认我说的话你听到了,什么时候可以证明老师说的话,被学生听明白了呢?
就是我们平常熟悉的扣1政策“同学们,听懂扣1”,当学生给老师反馈的时候(扣1),此时是学生给老师发消息,同样的学生也面临着同样的问题,学生给老师发的消息,也并不能确认老师是否收到了,但是老师一收到反馈,就能立马意识到他刚刚说的话,同学听懂了。
client与server通信时,client给server发送消息,在server没任何反馈的情况下,client是没有办法确认这条报文是否被对方收到了,有可能这个报文丢了,有可能server的反馈丢了...但是如果server给了client一个响应,对于client讲,最大的意义不在于自己收到了一个响应,而在于client终于确认了,他刚刚发给server的消息已经被对方收到了。同样的对应server,它也无法确定刚刚的响应是否被client收到了,所以client也应给server一个响应,这个响应对应server的意义就是确认了自己发给client的报文被对方收到了。
所以确认应答机制是通过应答,来保证上一条信息被对方100%收到了!!!但是在双方通信的时候总会遇到最新的一条消息是没有任何应答的,最新的消息没有应答,我们就无法保证整个通信彻底是可靠的,所以TCP不是100%可靠的!!!但是只要一条消息有应答,我们就能确认该消息被对方100%收到了。
TCP常规可靠性-确认应答的工作方式
client端在和server端正常通信时,client进行发送数据,但client无法确定被server收到了,因为TCP需要确认应答,所以server需要对这个消息进行确认(目前没有携带任何其他数据,就是单纯的确认),server发出的确认也不能保证被client收到了,但是当client收到了确认,client就知道了向server发送的这个数据被对方已经收到了。
如果单向的发,client只向server发消息,server不断进行确认,只要是client收到了确认就能保证自己刚刚发的消息被对方收到了,就能保证数据从client到server端的可靠性!意思就是说:今天就是client向server发消息,server对client发送的每一条消息都进行应答,虽然server无法确定应答是否被client收到了,但是server也不关心,只要把确认应答发出去就可以了,对与client,只要发现我收到确认了,我就能100%确定我发的消息被server收到了。反过来server给client发消息,做的工作也是一样的。
无论是client给server发消息,还是server给client发消息,我们只要能保证每一个方向发出去的消息都有对应确认,我们就能保证发送的数据被对方可靠的收到了。所以我们能保证client收到确认,就能保证它发的数据被server100%收到;能保证client到server方向的可靠,反过来server到client的可靠性,我们也能保证。
client和server在进行常规的数据报文交换通信的时候,只要我发消息,你必须给我么这个消息发确认,只要你给我确认,我就能保证这个消息是可靠的被你收到了;如果这个确认丢了,我就收不到,我就认为这个数据丢了。所以可靠性不仅要判断对方100%收到,也要判断对方没收到。所以基于确认应答机制,双方给给对方都做应答的时候,我们就能保证历史数据能被对方可靠的收到,可靠性就是100%的。
TCP的其他策略都是基于确认应答基础之上构建出来的。网络里不存在100%可靠的数据通信,总有最新的报文没确认应答。但是在单方向角度,我发出消息,如果我收到应答了,我就认为我的上一条消息,对方已经收到了,我没有收到应答,我就认为我的上一条消息丢了。换言之TCP的可靠性体现的是对历史数据的可靠性,对于当前最新数据不关心。
确认应答
我们发送的数据,在TCP叫做数据段,在IP叫做数据报,在Mac叫做数据帧,今天我们认为发送的都是报文。
如果client发出去了一批报文,假设这批有5个报文。只要client收到了各个报文的应答就能知道数据被服务端可靠的收到了。如果发送报文的顺序是1,2,3,4,5,接收方收到的顺序一定是1,2,3,4,5,吗?
被服务端收到了,并不意味着被服务端按顺序收到了。如果我发的这一批报文,对方给我都做响应,我可能发的是1,2,3,4,5,但是在做网络传送的时候,有可能1号报文在路由转发的时候,它选择的路径比较长,2号报文比较快,3号报文网络环境差,总之网络的环境很复杂,所以此时就存在一个问题,server端收到的报文是一个乱序的报文。所以client发送数据的顺序是12345,但是对方收的时候变成了54321,全部乱套了。乱序的数据问题是挺严重的,因为TCP要保证可靠性,除了要保证被对方收到,也要保证按序到达!你必须保证client发的是12345,服务器收的也必须是12345,不能乱序,乱序就出问题了,一旦乱序就导致业务逻辑出现紊乱,所以按序到达也是需要做到的点。
如何保证按序到达呢?
TCP报头里面就涵盖了一个叫做32位的序号,我们都有序号,序号只要编好了,到时候被对方收到的时候,我们只要按照序号进行升序排序,我们就能保证数据全部被对方收到的同时,然后保证它按序到达,所以32位序号的作用:保证按序到达。
如何确认信息和发送信息的对应关系呢?
之前确认的意义在于保证发送方发送的数据被对方收到了,现在我们的报文是有序号的,我现在发送10,11,12,对方可能是乱序接收的,但是因为有序号就可以升序排序就变的有序了,紧接着我收到了3个确认,可是我怎么知道这三个确认报文,哪一个报文是对应历史上发送出去的这些数据报文的呢?也就是确认信息和发送信息对应关系的问题
TCP的报头中涵盖一个确认序号,这个确认序号是对历史确认报文的序号+1。比如:客户端发送的是编号10,11,12的报文,那么10号报文对应的确认报文是11,11号对应的就是12,12号对应的就是13.
当发送方收到确认应答tcp报文之后,可以通过确认序号来辨别是对哪一个报文的确认。当我收到了确认序号为11的确认应答,我就知道了11号报文之前的报文我已将全部收到了,因为我发的是10,11,12,所以10号肯定收到了,如果我收到的是12,我就认为历史上12号之前的报文我已经全收到了。
准确表述一下,确认序号就是对历史报文的序号值+1,代表的含义:以确认序号是13为例,就代表13之前的所有的报文我已经全部收到了,下次发送请从13号报文开始发送!!!
无论是数据还是应答,本质都是发送的一个TCP报文,我发的和我收的都是TCP完整的报文,可以不携带数据,但是一定要具有一个完整的TCP报头!!!
eg:来回通信的都是TCP完整的报文

为什么一个报文里面,既有序号,又有确认序号?
我们双方在数据通信的时候,发送的一定是TCP报文,对于客户端和服务器来讲,我们一定是要填自己的序号的。
我们发现一个报文里面,既有序号,又有确认序号,为什么TCP报头在设计的时候序号和确认序号是两个字段,每一个人都要占4个字节?
貌似我们只要有一个序号字段就可以了,比如:服务端发送数据时序号填写10,那么服务端应答的时候同样的序号字段填写成11,我就可以用一个序号,发的时候代表序号,确认应答的时候代表确认序号。换言之,在通信过程中,我们完全可以使用一个序号值就表明刚刚的通信过程了,为什么TCP协议在设计的时候序号和确认序号是两个独立的字段呢?
根本原因是因为,我们刚刚在谈的时候,只谈了数据单方向的从客户端到服务器。但是TCP是一个全双工的通信协议(你在给我发消息的同时,我也可以给你发消息;你在给我进行确认的时候,我也可能在给你确认),我们实际上对应的一个客户端在发送数据的时候可能是既有自己要发送数据的序号,也有可能这个报文是对对方的确认。
比如:你和你爸说,我想吃拉面,你爸说,好的,这是单纯的你在给你爸说话,你在给你爸说话的时候,你爸的给你的应答就叫做好的。这就是单向的你爸给你发消息,你爸给你一个应答。还有一种情况,你和你爸说,我要吃拉面,你爸说,拉面不好吃,我们吃火锅。你爸说的话里面,拉面不好吃就是对你刚刚的消息做确认,“我们去吃火锅”这句话是既有对你报文的确认,又有他自己想给你发的消息。一个确认不是干巴巴的确认,它可能还会携带一部分数据。
所以我们的最终结论:双方通信的时候,一个报文,既可能携带要发送的数据,也可能携带对历史报文的确认。换言之:我可能给你发的消息,即是对你上一个报文的确认,同时里面可能会携带上我想给你发的数据,所以一个报文即可能是对别人的确认,又可能携带自己的数据。所以这就是为什么TCP要设置两个序号。
16位窗口大小
单纯的发数据也是有问题的,比如客户端疯狂的给服务端发数据,但是因为你的机器是发送方,对方的机器是接收方,接收方机器的状态你并不清楚,机器内存,有多少内存是接受缓冲区,接受数据的能力是多少。就好比有一种饿叫做你妈觉得你饿,不管你吃的再多,你妈总让你多吃点,实际上你早就吃不下了。同样的万一你频繁给对方发送数据,导致对方来不及接收,这个报文就只能被丢弃,TCP虽然有策略保证丢包可以重传,但是一个报文千里迢迢经过公网传到目标主机,但是它的下场就是直接被丢弃,而且还浪费了很多网络资源,这种大量发送对方来不及接受,进而导致对方把报文直接丢弃的现象,我们称之为因为没做流量控制而导致对方丢包的问题,虽然并不是大问题,但这就是浪费网络资源,所以我们必须得修复它,所以我们必须保证,我向对方发消息,报文的总数一定是在对方的可承受范围之内,所以我们就要有16位窗口。
TCP协议是自带发送和接收缓冲区的!TCP协议内部是会为了方便数据的收和发,是会自带接收和发送缓冲区的,就是TCP内部malloc了两段内存空间。

TCP为什么要弄两个缓冲区?
如果调用send/write直接把数据发送到网络里,本质就是要用网卡,把数据通过网卡发出去,相当于write/send直接调用了网卡接口把数据直接发出去,可是网卡也是外设,所以直接把数据发送到网卡中,就等价于你直接调用printf的时候,直接把数据写到显示器里面,就等价于你要进行fwrite的时候,直接把数据从内存刷新到磁盘里,这样的话效率是比较慢的。我们如果带一个中间的缓冲层的话,应用层只需要补数据拷贝到发送缓冲区的内存空间里就够了,就如同文件把数据拷贝到你的文件的对应的写入缓冲区之中,其中上层就可以进行返回了,剩下的就是系统的事情了。TCP虽然隶属网络,但是它是在OS内部实现的,所以它带个缓冲区很正常。
1.提高应用层效率,如果有这个缓冲区,应用层把数据只要拷贝到发送缓冲区里面,应用层就可以直接进行返回了,至于这个数据什么时候发,怎么发,应用层不关心,这个就是TCP的事情了。
不管是客户端,还是服务端,你想把数据发到网络里,网络能不能让你发呢?对方能不能接受你的数据呢?...像这些问题都属于网络细节,如果把这些任务交给应用层,应用层是无法知道的,但是只有OS中的TCP协议可以知道网络,乃至对方状态的明细。所以也就只有TCP协议能处理如何发,什么时候发,发多少,出错了怎么办?等细节问题。这样的话题就叫做传输,控制,协议,意思就是你的应用层只需要把数据拷贝到我的缓冲区里,应用层就别管了,剩下的事情就交给TCP了,至于这些通信传输过程中遇到的问题,由我来统一控制,所以TCP协议才叫做传输控制协议。就如同现实中:你发快递,到了一个快递点,工作告诉我,你只需要填一个单子,然后你就走吧,不用管了,至于这个快递什么时候发,如何发,中间如果有人快递丢了怎么办?这些细节问题与你无关,所有发送快递的细节有快递公司统一承担,这就是传输控制协议。
TCP协议只关心数据如何发出,应用层只关心数据如何拷贝进来,拷贝完成应用层返回,剩下的工作应用层完全不考虑。
2.因为缓冲区的存在可以做到应用层和TCP进行解耦!
再次复盘:
如果我要发一个数据,应用层把数据拷贝进来,在我拷贝的时候,有可能发送缓冲区里本来就有数据也在发,所以当我实际在进行拷贝的时候,我就是写入;当人家把数据发出去的时候,就对应发出,这里就相当于一个在写入,一个在发出,一个在生成,一个在消费,这种也是用户和内核级别的一个生产消费者模型。同样的如果对方接收的话一定是有人从网络里把数据给他发出去,发出去之后,应用层只需要把数据读上来就可以,至于这个数据怎么收的,收多少这些问题应用层也不关心,所以这就是发送和接受缓冲区存在的问题。
16位窗口大小
客户端和服务器是相隔千里之外,所以当客户端给服务器发送消息的时候,客户端自己有发送缓冲区,应用层无脑给他拷贝,客户端也无脑给对方发,因为服务器是有自己的接受缓冲区的,所以服务器在接收的时候,有可能把缓冲区已经接收满了,也就是说当我实际在给对方发消息的时候,如果不加任何速率方面的控制,其中我给对方发大量的数据,可能导致对方来不及接受。TCP应用层拷贝给它的数据拷贝到发送缓冲区里,它在自己的发送缓冲区里拿数据,然后不断的把数据扔到网络里,如果上层就是不断的在发,如果TCP没有任何控制策略,最终的结果就可能是服务器的接受缓冲区满了(假设上层不接受,或者调用read/recv频率低),当服务器的接受缓冲区满了以后,在来一个数据,那么此时这个数据就被丢弃了。
如果对方来不及接受,对方就只能丢弃。对于TCP来讲貌似是没啥影响的,因为TCP有超时重传的机制,也就是丢包重传,只要丢包了,我之后就可以给你重传。可是虽然不影响,报文传输经过封装,路由器转发,消耗了网络资源,因为server来不及处理导致它被丢弃了,这是server的问题,报文是没错的,全网的所有主机全都用TCP通信的话,我们有几十亿台机器,一人丢十几条报文,我们光在来回传输这些丢弃报文就不知道要浪费多少电力和人力!!所有我们是不想报文被丢弃的。
所有我们就有一个流量控制。所谓的流量控制和报文中16位窗口大小紧密相关。
server有接受缓冲区,客户端给server发消息,server是会进行应答的,其中server如何让客户端慢一点呢?
类比生活,一个人蒙住眼睛,拿上水壶,另一个人拿上水杯,你拿水壶给我的水杯倒水,我怎么样让你慢一点呢?
1.直接和对方说话,让他慢一点。但是server给client说慢一点,client是不理解的,计算机为了方便计算必须量化处理。
2.比如水杯是500毫升,你给我倒一次水,我是还剩400毫升,又倒一次,还剩300毫升....还剩0毫升。我看着水杯不断给你通告还剩多少空间,你作为倒水的一方,你听到还剩多少的时候,你根据剩余的数据量,就可以动态的调整倒水的速率乃至倒水的策略。
换言之,我们此时的server端,收到数据要给对方应答,发的数据和应答的数据都是TCP报文,所以我们可以在应答报文中,在报头里面填上,我自己的接受缓冲区中剩余空间的大小;
eg:client给server发消息,server的缓冲区假设是100kb,你给我发消息发了1kb,我的接受缓冲区剩余的大小还是99,我给你的应答报文里携带上还是99kb的空间,那么client是不是就知道了server端的接收能力。
我如何把我自己的接受缓冲区中剩余空间的大小通告给你呢?
通过TCP报头中的16位窗口大小。这就是我的接受能力,知道了我的接收能力,你就可以根据我的接收能力来动态的调整你自己发送数据的多少问题。我们的TCP不仅仅是客户端向server发消息,server也可能在给客户端发消息,甚至是同时进行的,server同样要考虑,是不是给客户端发的消息过多了,来不及接受。双方在通信时,都可在报文中携带上自己的接受缓冲区剩余空间的大小,所以此时双方就可以动态的进行数据发送。流量控制主要是为了让数据量发送的速度变得合理而不是一味地快或者一味地慢。
如何通过端口号找到目标进程?
进程要被OS管理起来,就是有一个pcb,进程PCB就是一个内核数据结构,我们把他想向成一个大链表,网络里是有端口号的,进程是要和端口号进行绑定的,我们要根据目的端口号找到对应的进程其实就是根据一个整数找到一个进程,用的就是哈希的策略,我根据目的端口做哈希,然后就可以找到目标进程的PCB,只要目标进程的PCB找到了,这个进程的对应打开的网络文件,那么网络文件对应的网络缓冲区也就有了,报文收到之后把他拷贝到它自己的网络缓冲区里就可以了。
系统中存在很多文件,为什么你读取文件的时候,这个文件读取到系统之后是读给你的?
你创建一个进程打开一个文件,这个文件是配套的,有缓冲区的,其实当网络里来了数据,我们根据端口号,哈希算法找到目标进程,根据目标进程的相关指针数据就可以找到这个进程打开文件对应的缓冲区,然后把数据拷贝进去,这个时候,这个进程就拿到了这个数据。
根据端口号能找到进程,只要找到进程就能找到这个进程曾经打开的socket文件,socket文件是有缓冲区的,然后把数据放在缓冲区里,这个数据就属于这个进程了。
6个标记位
实际上有些TCP标准,它的标记位不是6个而是8个,但是多的2个特别不常用。
TCP协议是面向连接的。TCP socket(就是基于TCP协议在应用层用的接口),要通信的时候,需要先connect!所谓的面向连接,本质就是通信前,要先建立连接。
为什么要建立连接呢?
是为了保证TCP的可靠性的。
如何建立连接呢?
TCP的三次握手。三次握手,是一种形象化的表述,说人话就是在通信前,我们要进行三次数据交换。三次数据交换,再说人话就是我们要进行交换三次报文。现在的报文我们暂时不考虑携带的数据,只是一个报头。
作为一个server,在任何时刻可能有成百上千个client都向server发消息。server首先面临的是,面对大量的TCP报文,如何区分各个报文的类别?
eg:我是一个餐厅的老板,我把我的餐厅的生意打理的特别好,饭特别好吃,服务特别好,所以陆陆续续有好多的人来我的餐厅吃饭,可是除了到现场吃饭的人外,还有很多人点的外卖,作为老板,我怎么区分这个人是正常来吃饭的客人,还是来取餐的外卖小哥呢?
一般就是通过他们的穿着,外卖小哥穿着很具有特定。不同的人群老板有这不同的处理策略
server就是通过TCP的标志位来进行区分,所以这里的6个标志位表征的是不同种类的TCP报文,不同种类的TCP报文,对应的接收方给他们的处理策略是不一样的。所以如果server收到一个报文,标记位填写的是ACK我就认为这个报文是一个确认报文;如果是SYN,它就是一个连接请求的报文;如果是FIN,我认为它是断开连接的报文。换句话说,不同标记位可以让server做出不同的动作。
ACK标记
假设client和server进行通信时,客户端发消息后,server端进行响应,因为我们已经有了一个确认序号,对于这个响应我们就可以填上一个确认序号,除此之外,我还得表示下我这个报文的类别,就好比如果你是一个外卖小哥,就应该穿上黄色的或者蓝色的衣服,上面必须得把对应的美团外卖,饿了么外卖的标志带上,所以作为老板一眼就看出这个人是取饭的。确认序号是用来供client确认它发出去的报文有多少被对方收到了,我们要表征一下这个报文就是一个确认报文而不是一个连接断开,连接请求的报文,所以这就要将ACK设置成1,ACK就叫做对报文做确认,表征报文自己是一个确认报文。几乎在所有的TCP通信的过程中,ACK都会被设置。
SYN标记
server端可能会收到一个连接建立的请求,请求虽然叫请求但是它也是数据,所以也要进行交换,server端如何区分发来的报文是请求呢?
我们就通过SYN标记位,SYN称之为同步标记位,也叫作建立连接请求的标记位。也就是说,只要client发送一个报文,SYN位被置1了,就证明这个发来的请求,它是一个连接建立的请求。一旦收到了一个SYN的请求之后,server和client要进行数据交互,此时就要完成3次握手。
建立连接,三次握手的过程
三次握手的过程:
首先client(建立连接的一方)要先发送SYN(注意这里不是只发了个SYN过去,而是发送了一个完整报文,报SYN位置1),server端进行确认,确认的时候带了SYN+ACK。紧接着client(主动发起连接建立的一方)再次给对方一个响应。这个就叫做3次握手的过程。换句话说,当我们建立连接的时候,我们首先需要的是3次握手的过程,而SYN的标记位代表的连接建立的请求,server端一旦收到SYN,也要返回一个同样的SYN标记位,以告知客户端我们可以来连接。然后client再给server一个响应。

eg:在学校里你喜欢一个女孩,你和她说,做我女朋友吧! 对方说,好啊,什么时候开始呢?你说:就现在。此时我们就以一个较快,较短的方式就完成了一次3次握手的阶段。

3次握手的目的就是建立连接,我们理解下什么叫是连接?
一个client可以向server建立连接,10个client也可以向server发起10个建立连接请求...所以在某个时间点,server中是可能会存在大量的连接的。server端一旦存在大量的连接。那么server需不需要管理这些连接呢?
当然是需要的,管理方式就叫做先描述在组织,也就意味着server端一定存在描述连接的结构体,结构体里填充的就是该连接的各种属性,最后把所有的连接以各种数据结构组织起来,比如说链表,哈希表,二叉树....
建立连接的本质:3次握手成功,一定要在双方的OS内,为维护该连接创建对应的数据结构(这就叫做创建一个连接),所以双方维护连接是有成本的(时间+空间),创建对应的数据结构要花时间更要花空间。
为什么是3次握手呢?
3次握手,我们并不担心第1次丢,第2次丢,我们担心的是第3次丢,因为,第一次它有应答,第二次它也有应答,第三次它没有应答,最后一次没有应答就有可能有丢失的风险。不要认为3次握手就必须成功。三次握手指的是以较大概率建立连接的过程。
我们注意到,建立连续的线都是斜着向下画的,以证明报文除了从左(右)向右(左)迁移之外,从上到下也在进行时间的流逝。
我们要进行3次握手,client和server都要认为只要3次握手完成,连接就建立好了。其中对于client来讲,是不是只要最后把ACK发出去,client就立马认为连接已经好了?还是client发出去的ACK被server收到之后,才任务连接已经建立好了?
答案就是只要把ACK发出去了client就立马认为连接建立好了,因为最后一个ACK根本就没有响应,所以client就没有办法得知最后一个ACK是否被server收到了。假设client最后发送的ACK的时间是10:00,当然这个ACK有没有被server收到client是不确定的,有可能这个ACK就丢了,这个时候就是搏一搏单车变摩托。此时,当ACK被server收到,假设收到的时间是10:02,此时server的3次握手才成功。
一般而言,双方握手成功,是有一个短暂的时间差的。
RST标记位
假如最后的ACK丢失,client认为连接已经建立好,server认为连接还没有完成,那么server就不可能给client发消息,但是此时client就开始发送它的消息, 一旦发送消息时,这个消息经过网络被传送到了server端,server端会认为:你这个client访问我的8080端口,不是应该建立连接吗?你怎么连接都没建立好,就给我把数据发过来了。此时server就有可能给client发送一个响应回的报文,这个报文的标记位携带RST,client一旦识别到了RST,client就意识到连接建立失败了,client最终就会关闭掉它的连接,所以RST是用来重置异常连接的。
第三次的报文丢失只是连接异常的一种情况,只要是双方连接出现异常,都可以进行reset,来进行连接重置,所谓的重置就是把双方连接对应的我们曾经维护的连接对应的在双方内存空间的数据清理掉,让我们的客户端重新连接。这就叫做RST。
PSH标记位
如果客户端给服务端发消息,服务端的接收缓冲区快打满了或者已经打满了,然后客户端就想催对方,让对方把数据尽快向上交付,客户端就可以发送一个报文,报文里的PSH标记位置1,它的作用就是告知对方,尽快将接收缓冲区中的数据尽快向上交付。
如何理解这个让上层尽快将数据取走,是怎么个取法?
read/recv是用户层在调用,我如果是个恶意用户,你发的数据我压根就没调用read/recv或者我就干脆不给你读取,这样的话,神仙来了也没办法。
再者,如果你作为一个服务端的程序员,有数据你不尽快读走,你是一名合格的程序员吗?
所以,一旦有数据来了,我们应该做的就是尽快取走,程序员在上层一定是会尽快把数据取走的,来不及取走一定的上层来不及读取。
我们现阶段理解告知上层尽快取走数据:当你实际在进行数据读取的时候,缓冲区里面不是说有数据就能让你读,而是说这个缓冲区里面的数据,实际是有它的低水位和高水位标记的,比如:缓冲区是100KB,接收到的数据假设超过了5KB,上层才能读,如果数据超过了80KB,你立马就要读了或者上层就不能在写了...OS能做的就是告诉你这个数据可以读了。比如:在read的时候,不是说来1个字节读一个字节,而是来了一批数据OS才让你读,因为过度频繁的通知你数据已经好了,就会导致你过度频繁的调用read,每一次read系统调用就会涉及用户和内核过度频繁切换,进而导致效率比较低,所以OS还是希望你一次读一批数据,而不是一个一个读,所以这里就可以在OS层面上告诉你数据已经就绪了。
URG
URG是和16紧急指针是搭配使用的。目前,因为TCP有按序到达!每一个报文,什么时候被上层读取到基本是确定的!相当于我读完第一个再读第二个,读完第二个再读第三个...如果我想让一个数据尽快的被上层读到,可以设置URG,URG表明该报文中携带了紧急数据,需要被优先处理。这个URG只是表明有没有紧急数据,99%的报文都是不携带的,有一个携带了,我们还需要确认这个紧急数据在哪里,这个紧急数据就又16位紧急指针指向。
16位紧急指针是什么呢?
TCP的报文后面携带的是数据,如果你把数据想象成一个字节序列,16位指针就会指向对应的位置。比如我送的是abcdefg123456,我如果想让对方优先读取的数据假如说是g,我们此时的16位指针就可以指向g在报文中的地址,这个就叫做16位的紧急指针。ps:TCP的紧急指针只能传输1个字节。如果紧急指针能让你传太多的数据,它就破坏了TCP本身按序到达的特性,它给你开个紧急指针让你传1个字节已经是仁至义尽了。
eg:send当中的flag参数可以设置为MSG_OOB,这个就叫做读取紧急指针
我们把这种紧急数据又称为带外数据,意思就是在TCP正常通信的数据流中,我们可以插队般的紧急把这个数据获得。

这个带外数据有什么用呢?
比如今天我有个服务,但是现在这个服务出错了,网络各方面状态都好着,但是它的服务出错了,出错后我在怎么请求都没用,就相当于它的服务已经出现问题了。但服务没挂掉,如果它的服务里专门有个线程读取带外数据,我就可以向我的服务发起一个带外数据的请求,最后它给我响应一个带外数据的响应,此时它可以给我传输一个状态码,比如,这个状态码中分别用1,2,3,4表示不同的错误,此时这里就可以用带外数据来做。
FIN标记位
一般而言:建立连接的一般是client,但是断开连接是双方的事情,双方随时都有可能,客户端可以断开,server也可以断开。我们以客户端主动断开为例。
客户端此时要断开连接,所以客户端也要发送一个表明自己是断开请求的报文,所以就在报文中携带FIN标记位。FIN相当于就是client告诉server我想断开连接。当然实际上,断开连接有很多场景,比如客户端想断,服务端不想;服务端想断,客户端不想;双方都想断;因为TCP本身是全双工的,只要一方想断开连接,就是说我对你没什么好说的了,但是有可能server还想向client发,因为TCP是全双工的,我们也不影响。
四次挥手
现在client向server发送断开连接,server同意断开连接就对他进行应答,就相当于把client向server通信的信道关闭了;假设现在server也要断开我的连接,就向client发送断开连接,然后client再对这个报文进行ACK,至此就称之为4次挥手完成。

eg:类比生活中离婚,这就叫做达成一致,征得双方同意的本质就叫做达成一致,关闭连接的过程用4次挥手本质就是为了以最小的成本达成一致。

以4次挥手的方式,达成连接关闭的一致认识。
如何理解序号
发送缓冲区我们可以理解成一个大的数组,比如应用层发一个hello,我们就把hello按字节为单位依次填写到了我们对应的发送缓冲区里。所以每个字节都天然的带有编号,如果你想把0~4这一段报文全部发出去,那么我们给这个报文的编号就是这批数据的最大下标4,作为我的序号给对方发出去。对方给我响应5的时候,我此时就认为4之前的全部数据(包括4)都发送了,接下来继续发后面的。不管是文本,图片...都是二进制流,所以我把所有的数据按字节为单位放在数组里,每个数据就天然带来编号。这个编号就是序列号。

TCP是面向字节流的,上层的数据交给发送缓冲区,在发送缓冲区以及接受缓冲区看来,数据全都是基于字节流的,也就是它的报文之间是没有明显的边界的,也就是全部放在数组里,上层去读就可以了。
超时重传机制
数据丢包了保证对方还能收到就只能重传。报头里没有体现任何超时重传的机制,TCP保证可靠性,有很多是在报头里就直接体现出来了,也有一些可靠性机制是没有在报头里体现出来的。因为凡是没有体现出来的,直接使用现成的(已经体现出来的这些机制),再加OS本身的一些机制就能完成。
超时重传就需要OS给每个报文设置一个定时器。
超时时间间隔应该是多长?
比如把报文发出去,1秒钟对方就绝对能收到,可是你非得等5秒,就会导致主机发送的效率特别低。如果我把超时的时间设置的特别短,就有可能导致重复发送报文的情况。
时间间隔:网络是变化的,网络通信的效率是变化的,发送数据得到ACK时间也是浮动的,超时重传的时间一定是浮动的!
当你把报文发出去了,发送方没有收到确认ACK,接收方是一定没有收到对应的报文数据吗?
不一定:
1.这个报文真的丢了
2.应答丢了
但是对于客户端来讲,从技术角度是可以识别出这两个问题的,但是这特别复杂,实际客户端根本不关心是啥原因,因为我们有重传。此时唯一带来的问题就是真的丢包情况还好,最害怕的是对方已经收到了,但是确认应答丢了。此时在重传就可能导致对方收到了重复的数据。当对方收到了重复的数据,本身也是不可靠的表现。
我们怎么保证对方收到的数据不是重复的呢?
很简单,就是因为每个报文都有序号,既然你是重传报文,那么这个报文在序号上一定没有变化,只要没有变化,服务器就可以根据序号进行去重,所以我们就不担心报文被对方重复收到。
那么, 如果超时的时间如何确定?
- 最理想的情况下, 找到一个最小的时间, 保证 "确认应答一定能在这个时间内返回".
- 但是这个时间的长短, 随着网络环境的不同, 是有差异的.
- 如果超时时间设的太长, 会影响整体的重传效率;
- 如果超时时间设的太短, 有可能会频繁发送重复的包;
- Linux中(BSD Unix和Windows也是如此), 超时以500ms为一个单位进行控制, 每次判定超时重发的超时时间都是500ms的整数倍.
- 如果重发一次之后, 仍然得不到应答, 等待 2*500ms 后再进行重传.
- 如果仍然得不到应答, 等待 4*500ms 进行重传. 依次类推, 以指数形式递增.
- 累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接,过了一会对方缓过来了,你把连接强制关闭了,对方连接还在,没关系,你给对方会发送reset,让对方重新连接。
连接管理机制
在正常情况下, TCP要经过三次握手建立连接, 四次挥手断开连接。
三次握手就是客户端发送TCP报文,SYN位被置1,服务端进行SYN+ACK进行响应,客户端在进行ACK,客户端只要发出去ACK连接就建立成功,服务端收到后连接才建立成功。客户端发送SYN,状态就变迁至同步发送:SYN_SENT,服务器发出SYN+ACK,状态变迁为同步收到:SYN_RECV。最后一个ACK丢了就丢了,我们就进行超时重传。
三次握手是双方的OS中TCP协议自动完成的,用户层完成不参与!!!应用层唯一要注意的是客户端调用connect就是在发起三次握手。直到server的accept返回就一定是3次握手已经成功了。所以在TCP中,不要认为用户的发送行为,会直接影响tcp的发送逻辑。
为什么是三次握手?
在我们两个想建立连接的时候,无非就是要确立两件事情:
1.对方好着没
2.网络好着没。
eg:你和你的朋友打电话,你的第一件事情就是先拨通电话,电话拨通之后,当你的朋友先接起来,“喂!”这叫做网络好着呢,但是你们两的状态适不适合谈话呢?你喝对方说,现在方便打电话吗,这叫做确认对方好着没。
建立TCP连接,确认的就是下面两件事:
a.确认双方主机是否健康(对应对方好着没)
b.验证全双工,三次握手我们是能看到双方都有收发的最小次数!!!(对应网络好着没)
验证全双工,就得验证客户端和服务器本身具有数据收和发的能力,只有具有数据收和发的能力,你将来才可能全双工的起来, 所以对于客户端来讲它发送SYN就是证明自己能发数据,它收到SYN+ACK证明客户端能收数据,前两次握手就证明客户端是能够收和发的,换言之客户端自己发送给服务器端的这条信道是通畅的,自己收这个报文的能力是具备的。对于服务器端,当他收到了一个SYN,就证明它是能从客户端收到消息的,当服务器端收到ACK,就证明它自己曾经发送的SYN+ACK已经被客户端收到了,就证明服务器端自己也有发数据的能力。换言之,客户端和服务器双方就能以最小的成本次数去验证全双工。
假如是1次握手,客户端无法验证自己收和发的能力。服务器即便收到这个报文也只能验证自己具有收的能力,发的能力无法验证。
假如是2次,客户端发个消息,服务端给响应。这可以验证客户端收和发的能力。服务器收到一条消息只能验证自己接收数据的能力,但是它无法验证自己发出去的消息是否被服务器收到,所以就无法验证发数据的能力。
所以3次能行了,3次肯定就是验证全双工的最小次数。
当我在验证全双工的时候,双方一定能够收和发数据的前提就相当于是对方好着呢,要不然我们就不可能收到对方的应答;网络好着呢,要不然我就不可能收到我们对应的收发的报文。所以我们只要能验证全双工,我们也就能同步的去校验对方是健康的,主机是没有问题的,甚至主机的网络通信的信道都是没有问题的。其中确认双方主机的健康,更多的是确认两方面:1.主机状态好着没,OS有没有挂掉 2.在OS层面上,双方的IO状况是健康的。同样的,我只要能收发到消息,网络的状况也是好的。
为什么4,5,6次握手不行呢?
4,5,6次不行是因为它们已经有些多余了,我们不是为了建立连接而建立连接,我们是为了验证网络状态,双方主机的就绪状态,验证全双工状态来发起3次握手。3次握手足以完成双方交互状态,那么4,5,6次已经不需要了,因为过多次的握手就会建立连接的成本。
为什么1,2次握手不行呢?
除了上述理由,还有些其他理由
1次握手这种情况是绝对不可以的,如果只是客户端发一条消息,双方的连接就建立好了,对于服务器端,一旦建立好连接,OS是会为了维护连接创建连接对应的数据结构,换言之,维护连接是有成本的,如果只是一次握手,客户端只需要向你发送一个报文此时就占据了一个连接的资源,如果客户端重复的发送海量报文的时候,那么它就很容易让你服务器上的资源很快被消耗完,那么客户端给服务端发送SYN请求的时候,服务端立马就把连接结构建立好了,但是客户端又不和服务器通信,客户端来10万次,就占据了我10万份资源。所以一次握手是绝对不可以的,因为这样的话服务器收到攻击的成本实在是太低了。
2次握手本质上和1次握手是没有区别的,客户端发一条消息,服务器发一条消息,此时连接就建立好了。对于服务端,只要收到一个消息,只要把这个报文发出,服务端就认为自己对应的连接就已经建立好了,甚至这个服务器的响应报文客户端压根没收到或者这报文已经丢弃了,服务端也认为自己的连接建立好了,所以作为客户端,我要攻击你这个服务器,给你发送大量的SYN,服务器发回来的ACK管都不管,服务器照样会维护大量的健康连接,可是这些连接从来没有人给你在进行后续工作了,维护连接是有成本的,发一个维护一个,发10万个维护10万个,我甚至无限给你发都行,因为对于客户端是没成本的,服务器可是要进行维护连接的,这样的话,你的服务器随随便便就被别人攻击了。
1次,2次握手是极度容易被别人通过发送海量的SYN而消耗完服务器上的连接资源的。维护连接是有成本的,比如一个连接5KB,对方给你发送100万条,就是5个G,后果就是服务器端充满大量的连接,我们把客户端发送大量SYN的请求,叫做SYN洪水。1次或者2次并不能很好的预防SYN洪水问题。
3次握手就可以预防了洪水问题了吗?
3次也有问题,也不一定能预防。但是3次握手相对而言,被攻击的成本会高一些,当然实际上为了预防这些攻击,我们也有其他的策略。当连接建立好,双方为了维护连接是有成本的!!!有了3次握手后,给了服务端一定的缓冲策略,实际上TCP就可以对有效连接做到甄别。
3次握手也不能彻底解决SYN洪水问题,它相较于1次或2次的优点如下:
当服务端发送SYN,服务端响应SYN+ACK的时候,也就是完成两次握手的时候,此时服务端并不认为连接是建立好的。说明如果客户端只给我发送大量的SYN的时候,服务器端并不认为连接是建立成功的,因为你给我发SYN,我给你发SYN+ACK,你又不给我响应(没有最后的ACK),所以服务器端并不会为你维护连接结构体,也就意味着服务器端的资源并没有太多的消耗;
那么如果客户端发送SYN,服务器响应SYN+ACK,客户端在响应ACK,我的连接不就建立好了么;如果这样的话,那么客户端至少得维护下,发送的SYN对应返回的SYN+ACK,那么这个连接才能合法的建立。这种情况说白了就是正常的进行3次握手,你消耗服务器的资源的同时,你也在消耗客户端的资源,所以双方是等量的一种消。如果是等量的消耗,就意味着普通的小白,如果拿着1台2台电脑,他是不可能把服务器全部攻击掉的,所以就基本杜绝了小面积的,个人的去攻击我服务器的可能性。
比如:如果我3次握手进行攻击,你就等价于是个合法连接,如果你是合法连接,那么这个连接一旦建立好,那么服务器就能把这个连接获取上来,你这个客户端的ip,端口号我都能拿到,那么一旦这个客户端是个恶意用户,跟我建立了好多连接,此时我在应用层得到了你的ip和端口号,“你为什么作为一个普通的客户端就给我建立了上百条连接呢”,所以我直接在应用层就可以做一些安全策略,比如黑名单,我一识别到你的连接是非法的直接就把你这个连接关掉,甚至我服务器底层也可以在防火墙层面上,用防火墙的接口,这个连接来的时候直接就拒绝掉,此时传输层和应用层配合共同去阻挡恶意连接的到来。
就相当于对我们来讲,如果是3次握手,客户端是不能通过只发送大量的SYN来对服务器进行海量攻击的,因为只发SYN,没有ACK,其中我的服务器也就不会为它维护连接。如果正常3次握手攻击,至少客户端和服务器是等量成本;其二就是服务器可以拿到这个连接的相关信息,做各种安全策略。
半连接
实际上,只发送SYN的时候,服务器也是会维护连接的,叫做半连接,只不过维护的时间特别短,半连接也有自己的安全机制,一旦是你发送的请求到我这边的时候,我在tcp底层也有相应的安全措施。总之如果是半连接的话,服务器的成本是非常非常低的。事实上,只发SYN这样的攻击在TCP这里是存在的,所以TCP有自己的策略。
事实上,通过3次握手这样的攻击也是存在的,虽然以一己之力是做不到的, 但大部分的恶意攻击其一是为了窃取你的信息,其二就是他想用你的资源,他不是为了攻击你,比如他给你种植了木马病毒,这个病毒可能就是有定时的任务,比如中午12:00统一向百度发起3次握手,他在全网中散播木马,他就可能在网络中劫持上万台机器,然后在12:00同时发起3次握手,发起之后,对于服务器讲,在某个时间点,突然来了一大批请求,因为服务器有可能每天的用户量是确定的,突然有一天来了大量的请求,服务器的硬件配置,各方面软件服务跟不上就有可能被搞垮了。别人通过一些恶意方式劫持你的机器,此时你的机器就叫做肉机,这个肉机就可以定时定点的向特定的服务定向的去发送某些请求。这种情况是真实存在的,而且像这种情况是防止不了的,因为被攻击的是客户,客户向你发起就是正常请求。当然劫持大量机器的成本也是很高的。
为什么是四次挥手?
断开连接的本质:双方达成连接都应该断开的共识。就是一个通知对方的机制。
四次挥手是协商断开连接的最小次数。你要和对方断开连接你得让对方知道,同时对方也要让你知道它同意了。四次挥手更强调功能性,只要能够以最小成本把连接断开就行了。
四次挥手的状态变化

当客户端发起FIN的时候,它的状态就变迁到FIN_WAIT_1,当服务端收到断开连接的请求并发出自己的ACK,服务端状态变迁到CLOSE_WAIT;然后客户端收到ACK,状态变迁为FIN_WAIT_2。此时2次挥手就完成,客户端告诉服务器连接它断开了,客户端不想和服务端说话了,注意这只是断开了单向连接,服务端还可以向客户端发。再下来,服务端向客户端发送FIN,此时服务端状态变迁为LAST_ACK,此时客户端收到后再给服务端响应一个ACK,此时客户端进入TIME_WAIT状态,服务端收到后变为CLOSED。
理解TIME_WAIT状态
现阶段看,先断开连接的一方,是客户端先动的手,经过4次挥手进入TIME_WAIT状态。主动断开连接的一方,要进入TIME_WAIT状态。
这个状态一般而言叫做连接有没有被释放,对于主动断开连接的一方,叫做4次挥手已经完成。可是对于TCP,TCP不能立马让你释放资源,因为我们无法保证最后一个ACK被对方收到了。最后一个ACK在发的时候是有可能丢失的,本来你可以重传一下,但是如果没有TIME_WAIT状态立马关闭,此时4次挥手没有完成,这个连接已经被你释放了,也就没人再次发ACK了。所以TIME_WAIT是主动断开连接的一方,即便4次挥手完成,也不能立马释放自己的连接结构,而必须得维持一段时间,这个时候所处的状态就叫做TIME_WAIT状态。
如果立马释放掉连接资源,万一最后一个ACK对方没有收到,就导致服务端认为连接还建立着呢,服务端就重复不断的进行LAST_ACK确认,它进行LAST_ACK确认就是超时重传,它在超时重传期间经过尝试一定的次数,如果不行,它的连接在断开。这虽然没有问题,但是这并不是正常手段的断开连接。所以当我们进行LAST_ACK不断重复的时候它就会过多的消耗服务器端的资源而导致服务器一直询问,所以我们为了节省它的资源,我们需要主动断开连接的一份进入TIME_WAIT状态。这只是一个非官方的理由,因为主动断开连接的一方通常是客户端,但这并不是100%,比如:之前写的HTTP协议,断开连接的一方的服务器。
验证主动断开连接的一方要进入TIME_WAIT
验证主动断开连接的一方要进入TIME_WAIT
我今天这个服务器,上面的代码压根就没有用,我们只是在main函数里创建了一个套接字,绑定了一下,然后监听了一下,一旦我们处于监听状态,我们是允许别人向我们建立连接的。
1.我们验证下当调用accept的时候,服务端把连接已经建立好了,你只是用accept从底层拿连接。
2.服务端想要主动断开连接。



验证过程

接下来,我进行telnet连接(因为博主只有一条服务器,只能自己连接自己)

然后我们再去查
红色框:我们看到81.70.240.196这个ip通过随机端口号连接我们。此时的连接已经建立,我们的套接字并没有accept,但是连接已经建立好了,说明accept只是把已经建立好的连接拿了上去。

验证主动断开连接的一方要进入TIME_WAIT
现在我们拿上来这个连接
启动服务器并建立连接
断开服务器并观察现象


总结一哈:
1.accept只是帮助我们获取新连接,在listen的时候底层就已经建立好连接了;
2.主动断开连接的一方,最终要进入一个TIME_WAIT状态;
3.一旦服务器进入TIME_WAIT状态,我们的服务是没办法立即进行重启的
为什么会要有TIME_WAIT,TIME_WAIT通常是多长?
MSL:Max Segment Life, 报文最大生存时间。意思就是说:如果一个报文从左到右或者从右到左比如从左到右,一个报文从一点到另一点最大花费的时间叫MSL,一个报文通过我自己的收发统计,我发现一个报文在发出去之后,有1毫秒,2毫秒,3毫秒大家都是在这个时间段内数据被对方收到了,那么其中3毫秒就是最大传送时间,也就是只要包含3毫秒在内,一个报文就已经能够从A点到B点了。当然具体到了没是另外一回事,反正如果没故障,一个报文从A点到B点最大时间就是MSL就叫做最大传送时间,换一种角度也就是报文的生存时间。
一个报文从一点到另外一点需要的最大时间是MSL,TIME_WAIT时间一般等于2倍MSL。MSL的时间不同的系统的规定是不一样的,在linux中默认是60s,但实际这个时间是变化的。
为什是TIME_WAIT时间一般等于2倍MSL呢?
因为有可能在你自己发出去最后一个ACK(断开来连接的要求的时候),曾今在网络里可能还会存在历史没有发完的数据,比如说服务端刚发出去一个报文,紧接着就发出去一个FIN,历史上曾今还有很多发报文可能滞留在网络当中,其中对我们来讲我们就需要在最后一次4次挥手ACK,等待2倍的MSL的时间:
1.尽量保证历史发送的网络数据在网络中消散;我发送断开连接的报文,如果这个时候把连接断开了,可能网络中还存在一些历史的数据并没有被双方收取,话说TCP不是按序到达么,按照道理来讲发出去的这个ACK它也要保证ACK被按序到达,但是所有的按序到达的前提是确认应答,最后一个ACK是没有确认的,当你发这个ACK时,历史上有很多的数据可能还在路上,而且这个报文有没有被对方收到你也不确定,那么其他很多东西也没法保证,所以保证历史的数据在网络中消散,这就是2倍MSL等的时机。
为什么是2倍的MSL,是因为历史上的数据刚好就在出口路由器上,2倍的MSL至少保证数据是一来一回的,因为当我们断开连接的时候,双方已经进入最后的握手阶段了,只要最后一次ACK的时候双方已经不在发数据了,历史上的数据也就不会被增多,不会在增多,历史上的数据最多残留的时间就是2倍的MSL。
再比如:有时候在网络上会进行超时重传,有时候重传的时候,报文并不是真的丢了,有可能这个报文没丢,而是阻塞在某个路由器上的,但是这个数据经过重传,这个数据可能早就不需要了,其中当你断开连接的时候,压根和这个报文没关系了。但我们担心的是,当你断开连接,立马重新建立连接,而这个报文恰好使用的端口信息又一样,恰好这个报文又被你的服务器收到了,此时这个报文就有可能干扰你的正常数据的业务逻辑。这种问题存在且或多或少的不可避免。所以我们只能设置门槛降低这种情况的发生概率。所以要保证历史上残留数据消散。
2.尽量的保证,最后一个ACK被对方收到了
建立连接不上100%成功的,断开连接也不是100%断开的,因为网络情况实在是太复杂了。归根结底就是最后一个ACK我没有收到或者丢失了,其中发出ACK的一端认为握手成功了,接受一方认为没有成功。当发送方发送了最后一个ACK,刚发出去就立马计时,一个报文发出去最多一个MSL,我对对方是否收到这个ACK确实不清楚,但是如果我在我等的这个时间段内,我又收到了一个FIN,就证明我曾经发的ACK丢了。因为我虽然无法确定ACK对方是否收到了,但是我只要一直收到FIN那么就证明我的ACK对方是没有收到的。只要对方给我再发FIN,我就继续ACK。换句话说,当我在等上2倍的MSL这个时间段内,如果我没有收到FIN,我就认为这个ACK被对方收到了,没有消息就是最好的消息。
对我们来讲,我在TIME_WAIT期间,我没有再次收到FIN,可能是ACK对方没收到,FIN也出现问题了,所以这也就是尽量的原因。
为什么会断开服务器后立即重启会bind error?

一个服务如果启动后,断开之后。当我想立马进行重启时,我发现无法立即重启,原因就是因为你是连接断开的主动一方。导致主动断开连接的一方进入TIME_WAIT,这个连接并没有被释放,连接还在,就意味着这个端口还被占领着,虽然没人用了,所以你再去绑定,就是一个端口被另外一个进程再去绑定,端口号只能被一个进程绑定,所以就会出现bind error。
如何解决bind error?
当一个主动断开连接的一方进入TIME_WAIT,实际上已经把4次挥手做完了,无非就是在等网络数据消散和最后一个ACK被对方收到。但是这个端口你别占着,因为此时这个端口上不会再有正常的数据发送了(正常就是一些控制端口连接的数据),所以你就继续等。我们同时也是可以把这个端口直接用起来的。所以linux提供了对应的接口。
这个接口就是setsockopt
使用setsockopt()设置socket描述符的 选项SO_REUSEADDR为1, 表示允许创建端口号相同但IP地址不同的多个socket描述符
这次我们断开后,立马启动就成功了。


服务器无法立即重启,会有什么危害?
比如:双十一,我的服务器上挂着大量的连接,当连接不断增多的时候,有可能随时来的一个连接都有可能是压死骆驼的最后一根稻草,比如服务器上已经有10万个连接了,然后又来了5000个连接,最后这5000个连接直接把我的服务器搞崩溃了,也就是进程挂掉了,进程挂掉是因为这5000个连接到了,但是我的服务器曾经还挂着10万个连接呢,所以此时对这个10万个连接来讲,我的服务器就是主动断开连接的一方,在技术角度没啥,等一等就可以了;在业务角度危害就大了,服务器如果无法立即重启,1秒就是几千万的流水,如果等上60秒损失就大了去了。所以一定要做到可以立即重启。又因为服务器的ip和port一定是众所周知的,所以你不能通过换一个端口号的方式重启服务器,必须得在原来的端口号重启。
CLOSE_WAIT状态
四次挥手,一定是你主动一次,对方主动一次;所谓的断开连接本质就是我的客户端调用close,服务端调用close。当你调用close的时候,就是你主动断开连接的时候。1个close就是两次挥手,2个close就是4次挥手。如果客户端给我断开连接,我在发送ACK,这个一来一回是客户端主动断开连接。可是如果我的服务器不断开连接呢(不调用close),如果服务器不调用close,就会导致服务器一直处于CLOSE_WAIT状态,而让服务器不会在进行后两次握手。
验证CLOSE_WAIT状态
CLOSE_WAIT状态我们可以正常的进行通信,但是进行通信的时候,我把你的连接拿上来,但是我不关你的连接,然后你的客户端你自己退。


ps: 我们只看红色框即可。
我们看到服务器的状态就处于CLOSE_WAIT,此时服务端没有关闭这个文件描述符,没有调用close,然后客户端告诉服务器我要跟你断开连接,服务器说好的,自此以后服务器就不说话了,也不关闭连接,此时四次挥手的后两次不会执行,我们的服务器就会把这个连接一直维护着,一直处于CLOSE_WAIT状态,客户端早就走了,CLOSE_WAIT对服务器的资源是一个非常大的消耗。
CLOSE_WAIT给我们带来的启示?
1.一个fd被用完,千万不要忘记进行释放!fd本质就是数组下标,它在linux内核2.6中是32个,但是实际上我们可以通过打开linux的一些选项,来把他的文件描述符调整成10万个。我们自己用的是生产环境(线上环境),能打开文件描述符的个数就是10万个(这是生产环境必须要有的,要不然一个服务器只能打开几个连接就太少了)。
 2.fd是有限的,假如你今天写的服务都忘记了close,只要有一个连接到来就少了一个fd,最终就造成了文件描述符泄露。所以你将来在你自己的服务器上发现有大量的CLOSE_WAIT状态,一定不是别人的问题,而是你的服务器上有问题。
2.fd是有限的,假如你今天写的服务都忘记了close,只要有一个连接到来就少了一个fd,最终就造成了文件描述符泄露。所以你将来在你自己的服务器上发现有大量的CLOSE_WAIT状态,一定不是别人的问题,而是你的服务器上有问题。
滑动窗口
我们现在已经有了确认应答机制
发一个数据,对方给我一个ACK,收到ACK之后,我再发下一个数据,对方在给我ACK,这样的话随着时间的推移报文就可以以确认应答的机制被对方收到,当然反过来也是可以的。但是这样的一收一发方式有一个致命的问题,就是所有的报文发送都是串行的,一旦所有报文发送是串行的,那么它的效率和性能势必会降到非常非常低,实际上TCP是允许我们一次发送多条数据的,就可以大大提高我们的效率。 eg:一家快递公司如果每次只能发一个快递,那么他发到猴年马月都发不完,但是他可以拿着车一次拉一大批过去,这样的话就可以把多个报文在路上的时间就进行了重叠,进而提高了效率。


所以主机A一次就可以向主机B发大量的数据,这也就是TCP向对方发起对应的数据的时候,每个报文都需要带序号的原因,因为一次你允许我发送多个,这多个消息你是按顺序发的,B不一定按顺序收。所以序号相当大的好处就是让我们的数据进行按序到达。
如果我们运行一个主机向另一个主机发送大量数据时,那么一次给对方多少呢?
一次给对方多少,由接收方决定,一方面我们要提高效率,另一方面我们还要保证发送的数据让对方可以按照自己的接收能力而接收。所以我们为了做到这一点,我们就引入了滑动窗口。
窗口大小指的是无需等待确认应答而可以继续发送数据的最大值,上图的窗口大小就是4000个字节(四个段).。说人话就是将来我们可能有个滑动窗口,以前的报文是发送一个,收到应答才能发送下一个,现在的如上图,发送第一个没有应答,发送第二个也没有应答,这个就叫做在你发出去一个报文,没有应答时,其他报文也可以发。就是可以直接向对方塞的数据量。
发送前四个段的时候, 不需要等待任何ACK, 直接发送;注意这里不需要ACK,不是永远不需要,而是当前短期内不需要。把数据发出去之后,理论上每个报文都需要应答。只不过我现在可以先不收到确认。你可以晚来但是不能不来。
滑动窗口在哪里,是什么?

我们的滑动窗口本质是发送缓冲区的一部分。16位窗口大小表明的是接收方中剩余空间的大小。我一次最多可以给对方塞多少数据,不是由发送方放决定的,而是由接收方决定的,所以就是由接收方的接收能力决定的。所以目前滑动窗口的大小是和对方的接收能力有关(今天就认为是对方的接收能力),比如说你自己的缓冲区里面还剩10KB,我这个滑动窗口的这部分区域最多一次可以给你发10KB的数据,也就是说我可以同时向你发10KB数据,这10KB数据可以暂时不收到所谓的应答。
- 收到第一个ACK后, 滑动窗口向后移动, 继续发送第五个段的数据; 依次类推;

滑动窗口有没有可能缩小呢?
滑动窗口不是固定的4个,8个,10个的它是可以浮动的,滑动窗口的概念我们叫做可以暂时不用ACK可以直接向对方发的,前提条件就是对方有能力可以把这些数据收到,所以对我们而言,如果再给主机B发消息的时候,比如现在的滑动窗口是4KB,我给它发了1KB数据,它给了我ACK,接收方虽然拿了一条数据,但是这个数据没有被上层拿走,也就意味着接收方的接收能力变少了,那么接收方的ACK给发送方的时候通告发送方窗口由4KB减成了3KB。换言之,这个时候的滑动窗口只会把左侧移动过去,右侧不变。如果对方一直不拿数据,最终这个滑动窗口会减成0。
如图:
 所以滑动窗口是可以不断的减少的,甚至也可能为0,右侧可以没有任何变化,根本原因就在于对方读取数据的时候,对方的应用层来不及接受数据,所以滑动窗口就会不断在减少。
所以滑动窗口是可以不断的减少的,甚至也可能为0,右侧可以没有任何变化,根本原因就在于对方读取数据的时候,对方的应用层来不及接受数据,所以滑动窗口就会不断在减少。
滑动窗口有没有可能扩大呢(向右移动)?
也有可能,当对方告诉我它的窗口大小是4KB,然后我的滑动窗口就是4KB,我一次给他发了4KB 的数据,接收方的上层一下子就把当初积累的数据全部拿走了,一下子接收方的缓冲区变成了12KB,然后接收方给发送发送放通告的窗口大小就是12KB,当发送方收到ACK时,发送方对它的滑动窗口一瞬间就不是仅仅向右移动了,而是移动的同时还扩大,所以就相当于可以快速扩大滑动窗口对应的区域。
如果今天我发4KB,对方收到4KB,然后对方把这个4KB全部读上去了并且给我的1000~2000先确认,所以才有了上图窗口整体向右移动的情况。所以滑动窗口最终能要进行大小调整是和对方的接收窗口,接收能力强相关的。
滑动窗口可能向左滑动吗?
不可能,凡是在滑动窗口左侧的都是已经发送,已经收到确认的数据
如果出现了丢包, 如何进行重传?
滑动窗口发送1001~5001这么多报文,最后ACK确认,先确认的是1001~2001,后面的2001~3001也会陆陆续续确认,但是如果中间的ACK丢了呢?
比如你已经发了你没有收到3001的确认,但是你收到了2001,4001,5001的确认,这该怎么办?

对我们来讲,如果我没有收到3001,我就认为发送方已经把2001~3001丢了,但是我收到了5001,序号的含义是我已经收到了该序号之前的所有内容。所有我在发送数据时,中间有些ACK丢了,我没有收到所谓的ACK应答,但是我的报文里却收到了5001的ACK,那么就其实已经告诉我了,不要害怕,实际上2001~3001我已经收到了,因为我的序号是从5001给你发的。换句话说,如果中间报文的ACK丢了,我们的窗口直接移动到5001,相当于这部分数据已经被全部收到了。所以TCP是允许少量的ACK丢失的。
如果此时我给对方发消息还是1001~5001,1001~2001数据对方收到了但是2001~3001数据丢了,因为对方收到了5001,可是2001~3001的数据没了,此时对方给我的ACK是什么呢?
不要忘了,确认序号的含义:它表示的是确认序号之前的数据已经全部被收到了,此时如果中间发送的数据丢了,此时这里的ACK 5001,4001,3001都不能发,你只能发送2001。当发送方收到2001的时候,它就立马知道了我发的这4个报文中,有可能有一些报文已经丢了,我试一试在发送一个2001~3001,一发完后,对方收到了完整的报文,ACK就成了5001。
总之,当我们进行数据发送的时候,因为是滑动窗口,只有收到ACK的时候,滑动窗口才会右移,所以不要担心当我收到ACK的时候,中间的ACK没收到,但是结尾的ACK收到了,只要你收到了最大就认为之前的全部收到了,协议就是这么规定的。如果ACK2001收到了,后面的3个没收到,我就判断是不是后面的丢了,我就进入超时重传的环节。换句话说,当我没有收到ACK时,窗口向右滑动的时候不会越过这几个没收到ACK的字段,数据就被暂时保存起来了。滑动窗口右移的过程就是删除数据的过程,所以如果我的窗口不向右滑动,不越过这个节点,不越过这个数据,这个数据就一直在发送缓冲区里面,它就在等ACK,如果等不到ACK就进行超时重传。所以,多我们来讲,我们曾经说你要把数据超时重传,前提条件是你把数据已经发出去了,但是你没收到ACK之前,你还得把数据保存起来,就是在滑动窗口里保存。
再次理解滑动缓冲区
我们曾经说过,发送缓冲区可以想象成一个数组。数组中的每一个元素就是一个字节,所以上层写数据的时候木就是把字符一个一个填充到数组里面,我接下来就是一个一个发了。所以所谓的滑动窗口,我们可以把他理解成,我定义两个int win_start ,int win_end
可以认为源码就是这么实现的。滑动窗口右移就相当于start++。滑动窗口扩大相当于end++。

当我们给对方发了一条消息,比如说我们的滑动窗口大小是4KB,我给对方一次塞了4KB的数据,比如对方接收缓冲区是16KB,可是现在只剩4KB了,然后我就给他发了一批数据,填到了它对应的发送缓冲区里,然后接收方的应用层没有把数据取走,所以接收方会告诉发送方它的窗口大小是0,所以当我收到了对方一个一个的ACK报文的时候,我发现接收方给我的窗口大小是0。发送方怎么办呢?
当我收到一个确认序号,我们的窗口左侧向右移动本质是win_start+=确认序号,所以当不断ACK的时候,win_start这个位置不断向后移动最后指向和win_end一样,其中当接收方通知窗口是0,win_end就不移动,此时win_start和win_end就指向同一个位置,就证明滑动窗口为0,此时就意味着我们不能在进行发生了。当再次ACK时,假设接收方的缓冲区变成16KB了,所以更新了一个窗口大小16,所以win_start不变,win_end +=对方通告的窗口大小。如此同步的告诉我确认序号和窗口大小,那么这个滑动窗口就整体的右移了。
貌似这个缓冲区是线性的,那么发送缓冲区不会越界吗?
不用担心,上层把数据放进来,你把数据发出去,这就是一个简单的生产消费。而且我们曾经还学过一个东西叫做环形队列,所以实际上发送缓冲区是环状的形式组织的,那么窗口不断移动的本质就是窗口绕着这个环不断的转圈,此时就不存在越界的问题。比如环形队列被我们写满了,你调用write是有可能阻塞住的,所谓的阻塞住就是环形队列被打满了,当然,网络中肯定是会被阻塞住的,当然也无需担心,你把数据从上层拷贝到你的环形队列里,然后环形队列的发送缓冲区里面,滑动窗口就控制它的发送速度,然后当你实际在向对方不断发送数据的时候,如果你的发送缓冲区被打满了,但是对方接收数据为0,你也就不发了,当你不发时,上层再拷贝数据就拷贝不下来了,因为缓冲区被写满了。你上层的read/write就会被阻塞住。
再次总结下丢包的两种情况
情况一: 数据包已经抵达, ACK被丢了
这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进行确认;
情况二: 数据包就直接丢了.
- 当某一段报文段丢失之后, 发送端会一直收到 1001 这样的ACK, 就像是在提醒发送端 "我想要的是 1001" 一样;
- 如果发送端主机连续三次收到了同样一个 "1001" 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;
- 这个时候接收端收到了 1001 之后, 再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中
- 这种机制被称为 "高速重发控制"(也叫 "快重传")
超时重传 vs 快重传
实际上TCP里这两种重传机制都是存在的,为什么超时重传还存在呢?
原因就是快重传是有要求的,你必须连续收到3个同样的确认应答。如果我滑动窗口只有两个空间,一次支持发送两个报文,其中1个丢了,我们也只能得到一个ACK,所以快重传不能解决所有的问题,所以超时重传是给我们兜底的,也就是说超时重传必须存在,快重传是在保证能重传的前提下为我们提高效率的。
流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被打满, 这个时候如果发送端继续发送, 就会造成丢包, 继而引起丢包重传等等一系列连锁反应. 因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow Control);- 接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 "窗口大小" 字段, 通过ACK端通知发送端;
- 窗口大小字段越大, 说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后, 就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端
什么时候发送方就知道了接收方的接收能力?
取决于对方什么时候给我发送的第一个报文!在3次握手的时候双方已经进行交互了,所以就是在3次握手期间协商窗口大小。双方就要根据对方的窗口大小,来设置自己的滑动窗口的初始值!进而调整发送的速率。滑动窗口就是既想提高效率(体现在滑动窗口内的报文可以暂时不要应答,立马发),又想保证对方接收。
如果我的接收缓冲区的窗口大小为0怎么办?
此时发送方就不发数据了,就停下来了,因为我们有流量控制。那么发送方什么时候再向接收方发消息呢?
理论上是不会再发了,因为接收方的窗口大小是0,如果接收方的应用层一直不取数据,就会导致发送方一直在等,所以发送方可以向接收方发送报文携带PSH标记,这个报文可以不携带任何数据只是报头,发过去之后并不占用接受缓冲区数据的空间。所以发送方发出PSH后,接收方意识到对面催了,我得赶紧让上层去取数据。
一旦发送方给接收方发了消息,接收方要不要应答呢?
TCP是确认应答的,所以接收方要应答,一旦应答了就要在通告自己的窗口大小,所以接收方一旦为0 了,发送方就可以等一会,然后给对方发一个窗口探测的报文,这个窗口探测就是携带PSH的普通报头,一旦对方应答就会告诉我窗口大小,如果此时对方给我通告的窗口大小还是为0,那么此时发送方只能定期的轮询式的向对方发送窗口探测。除了发送方主动问对方有没有窗口更新之外,接收方也可以主动进行。比如接收方上层拿走数据了,腾出来2000字节的空间,所以接收方就立马可以向发送方发送一个报文(不携带数据)告诉发送方,我的窗口大小更新了,你向我发消息吧。所以一旦接收方的窗口大小为0,发送方在等着发,接收方在等上层取数据,等的时候接收方要通告窗口的更新情况。一种就是发送方定期轮询,一种是接收方更新了进行主动通知。在TCP中,这两种策略都会被使用。
总结

接收端如何把窗口大小告诉发送端呢? 回忆我们的TCP首部中, 有一个16位窗口字段, 就是存放了窗口大小信息; 那么问题来了, 16位数字最大表示65535, 那么TCP窗口最大就是65535字节么?
实际上, TCP首部40字节选项中还包含了一个窗口扩大因子M, 实际窗口大小是 窗口字段的值左移 M 位;
拥塞控制
我们之前介绍的全部考虑的是两台主机的问题,我们并没有考虑过中间网络的问题。很多时候压根并不是两台主机的问题,而是中间网络的问题而导致数据传送出现一些奇怪现象。我们以前的所有机制都是考虑了发送方和接收方的问题。其实TCP也考虑了网络的问题。
如果我给你发了1000个报文,我只丢了1~2个,作为我来讲,我认为这是正常的,在正常的情况下,要么超时重传,要么就快重传;如果我发了1000个报文,999个报文全部都丢失了,作为发送方就是没有收到数据对应的ACK,如果此时我所发的数据这么多都丢了,那么我应该进行超时重传或者快重传吗?
首先当我丢大量报文的时候,绝对不是对方主机的问题,我发的数据量一定是对方可以接收的数据量,对方不可能在自己的机器上把数据直接丢了,大概率是在网络中间就把数据丢了。现在的问题就是少量丢包和大量丢包要不要重传的问题。
比如:你今天考试,参与考试的有300人,然后老师阅卷,发现有三两个人不及格,这当然是正常的,作为出题人,我也可以认为我出的题特别好,挂了课的人就是他们自己的问题。但是如果我阅卷子的时候发现只有三两个人及格了,290多个人全部挂了,此时就是老师出卷子的水平问题,题目出的太难了,这时候就是老师的问题。我们发现挂1个和挂200个都是挂,有时候就是怪自己,有时候就是怪出题人。所以量少和量多是两码事,归因的时候就归到了不同人的头上。
同样的,今天我给对方发报文,丢一两个报文是正常的,我给对方重复就行了,但是丢了大量的报文,我就不应该向对方重发。
背景引入
我们目前学习TCP,一直研究的都是一台主机到另外一台主机的情况。可是全世界里的大部分主机用的协议都是TCP,也就意味着所有人遇到了TCP中一些问题的话,所有主机都要采取相同的策略。比如A主机给B发,B给C发....如果每台主机都只丢1~2个报文,大家重发就可以。但是如果我发了1000个,999个报文都丢了。也就是说,如果你发了1000个,丢了1~2个,可能其他主机也可能是发100个丢1~2个;如果你发了1000个,900个都丢了,那么和你在同一个网段的其他主机就也有可能出现丢失大量报文的情况。
发1000个,丢1~2个,网络出现问题只是属于偶发性的个别逻辑出问题了,但是发1000个,丢900个就认为整个网络全部出问题了,更重要的是所有的主机都会这么认为,如果我们只有快重传或者超市重传,所有主机几乎在同一个时候都认为网络有问题了,所有主机都准备把自己的900个数据全部发到网络里,A主机发,B主机也发,C主机还发...但是网络已经出现了大面积丢包的问题,你还要让所有的主机都进行重传,更夸张的是所有主机几乎步调一致的重传,那就相当于所有主机进一步把网络冲垮了,本来网络缓一缓还能缓过来,现在一人给一脚,网络就扛不住了。所以一旦识别到有大面积丢包,TCP规定立马警惕起来,至少规定不要进行重传了,你这么认为的时候,别的主机也这么认为。换言之,少量丢包立即重传,大量丢包,此时发送端主机就应当等一等,让网络缓一缓调整一下,所有局域网中的主机都会这么认为,此时网络里就不会有新增报文了,它就可以让网络自己适应一下,自己处理一下。就跟你的电脑卡住了,你就不要点来点去,而是等一等一样的意思。
像上面这种如果发现大量丢包,TCP协议不会立即对数据重传而是等一等这样的机制就叫做拥塞控制。
所以流量控制,滑动窗口是为了考虑主机1对1进行数据通信时,解决数据通信太快或者太慢的问题。拥塞控制,就是控制的网络的一个情况,TCP不仅仅考虑了发送和接收方,连路上的时间都给你安排好了,而且拥塞控制是所有局域网中的主机都要考虑的,大家一旦发生网络拥塞,大家就有共识,大家都要等一等,这样就给了网络喘息的时候,这就叫做拥塞控制。
所谓的拥塞控制是TCP发现网络拥塞,然后尝试去恢复网络状况的一种策略。拥塞控制,最重要的是理解不仅仅是你一个人在控制,大家都用的是TCP,网络溢出影响的是大家,大家都会执行拥塞控制,这样就形成了一个短暂共识,给网络缓冲时间,所以在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的。
拥塞窗口

- 此处引入一个概念程为拥塞窗口
我们实际上在TCP协议里面最重要的窗口有三个:滑动窗口,接收窗口(报文里面的窗口大小),滑动窗口在我的发送缓冲区里,接收窗口指的是对方的接收缓冲区的剩余空间。拥塞窗口是一个对应的描述网络可能会发生拥塞的临界值,也就是说拥塞窗口是一个数字。拥塞窗口是用来描述网络状态的一个概念。所以我们的窗口依次对应的是发送方,接收方,网络。
- 发送开始的时候, 定义拥塞窗口大小为1;
- 每次收到一个ACK应答, 拥塞窗口加1;
- 每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
拥塞窗口:其实就是一个数字。
比如: int win=4096;意思就是主机A你如果一次向网络里塞大量的数据到对方的接受缓冲区当中,那么你一次塞的数据量超过拥塞窗口4096,就有可能引起网络拥塞,所以你发送的数据总量要限制在4096以内。限制发送放向当前的网络中发送数据的最大值,这个窗口就叫做拥塞窗口。

之前不是说滑动窗口是我向网络里塞数据,一次可以塞多少数据,而暂时可以不用应答的这样的一个范围吗?滑动窗口不是说好的是由对方的窗口大小也就是接收能力决定的吗?
是的,这都没错,这是因为我们之前只考虑主机B,不考虑网络,但今天TCP是考虑到网络的,所以实际上,滑动窗口发送的数据量=拥塞窗口和对方的窗口大小中的较小值。所以一个主机能向网络中发送的数据总量(防止拥塞,一次最多塞多少呢),是拥塞窗口和对方接收缓冲区的接收能力当中的较小值决定的。
所以实际上作为发送方向网络中发消息的时候,既要考虑网络拥塞的问题,还要考虑对方接收能力的问题,也就是发送方既要考虑流量控制的问题也要考虑网络拥塞的问题。
网络拥塞了,TCP该怎么办?
虽然TCP有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据. 但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题. 因为网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵. 在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的。 TCP引入 慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据; "慢启动" 只是指初使时慢, 但是增长速度非常快.- 为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍.
- 此处引入一个叫做慢启动的阈值
- 当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长

- 当TCP开始启动的时候, 慢启动阈值等于窗口最大值;
- 在每次超时重发的时候, 慢启动阈值会变成原来的一半, 同时拥塞窗口置回1;
为什么慢启动前期使用指数增长呢?
一旦网络拥塞了,我们发一个报文确认网络的健康状态,对方给我应答了,说明现在网络OK了,第二次我发2个还是OK,其中对我们来讲,一旦前面1~2次,2~3次发现此时网络已经能够正常通信了能够给我进行ACK了,这个时候我们已经不在需要探测网络的健康了而是要尽快的恢复网络的状态。
什么叫慢启动呢?
类比生活:在旧社会,有一些佃农(丧失土地的农民),只能通过租赁地主的土地来存活,租赁的话就必须付房租或者付所谓的地租,有时候碰到灾年荒年就没有钱去偿还。现在有一个地主,地主就跑过去找可怜的佃农老张,就说:“你欠我的钱什么时候还呢”,老张说,“我实在是没钱,付不起地租”。地主又说“这样把,你欠我的钱不用还了,今天你给我1粒米,第二个给我2粒米,第三天给我4粒米,依次类推,每一天都是前一天的两倍,然后你给我一个月,这样的话地租我就不要了”。佃农老张一听挺划算的就欣然同意了,同意之后就正常履行偿还的约定,但是当老张还到10几20天的时候就发现不对劲了,发现越靠后面就越还不起了。当初地主提出这样的要求的时候,老张为什么同意呢?因为老张看中的是前期还的少,后期的帐他算不来,他可能就同意了。
这种还米粒的方式就是指数级增长,指数级增长最明显的特点就是前期慢,一旦过了某个时间点它就变得非常快,所以指数级增长发送报文探测就叫做慢启动,慢启动就是前期慢,而一旦前期慢了。也符合我们前期需要发送少量报文的需求,可一旦前面的3~4次经过指数级探测发现都有应答,说明网络已经就绪转准备好了,我们不应该再慢下去,而是快速的恢复过来。所以指数增长前期慢,后期快,即保证前期不要把网络压垮,又保证了检测网络没有问题,我们就应该尽快让网络状况进行恢复,这就是采用指数级增长的根本原因。这就叫慢启动策略。
可是如果我们一直指数增长下去,这个窗口大小就可以在短期之内,一瞬间上升的非常大,那么这个拥塞窗口就没有意义了,所以只要通信过程在一直正常进行着,我们就可以在指数增长的一定程度就不要让他指数增长了,而是让他由指数变成线性增长,这个从指数到线性增长的过程,就叫做指数到线性的一个临界值,也就是线性增长的阈值。
窗口大小即便是线性增长,它也在不断的增长,增长的过程是不断的以动态的方式在尝试网络发生拥塞的阈值问题。也就是网络是动态的,它的拥塞窗口大小是不一定的,它用指数级增长进行前期探测,中期恢复,后期用来探测下一次的窗口大小有多大。然后一旦发生拥塞,此时我们就立马重新开始慢启动。
比如刚开始拥塞窗口大小24,我一次可向网络里发24个报文,一旦我发现有很多个报文丢了,我立马进行慢启动,把发送的24立马降到1,然后重新开始指数增长,在我重新开始指数增长时,我在24这个点,发送网络拥塞的同时也探测到了当前次网络拥塞的阈值问题,发到24网络就发生问题了。然后我们重新调整指数到线性增长的阈值,这个新的阈值就成为网络里拥塞窗口的一半(指数增长到线性增长它是在一半处进行切换的)。所以当我们发生网络拥塞,我立马在进行慢启动,指数级前期探测,中期恢复,然后到了旧的阈值的一半时切换成线性增长,在继续探测当前次新的网络拥塞时它的一个对应阈值情况,一旦再次拥塞。继续回复到最开始,再次执行以上流程。不断进行重复。
网络发生拥塞,在主机看来是必然的,因为我一直在指数增长,而我这个必然是故意为之的,因为网络是变化的,它什么时候拥塞时是不可预测的,所以你只能通过不断的去尝试检测出当前次的拥塞,用当前的拥塞来指导接下来的行为。所以对我们来讲就是一旦发生拥塞就回到慢启动,指数增长,快速恢复,恢复之后正常通信,通信时一旦发生拥塞在循环。这就是网络发生数据的真实情况。
我们最终的结论:所谓的拥塞窗口是被尝试出来的,是不断的经过指数增长,线性增长尝试出来的,然后一旦发生拥塞,此时我们就执行慢启动。这个过程就叫做拥塞控制。实际上这个拥塞控制就是一个策略(就是用两个临界值约束我们的发送行为的是由TCP自己控制的)。
那网络的拥塞窗口变来变去的是不是会造成网络的数据量一会升,一会降?
不用担心,正常通信的时候,传输轮次是可以非常多的,当你增长到一定程度的时候,拥塞窗口不断增大,可是你这个主机发送数据的总量不是只看拥塞窗口的,还有对方的接收能力,当对方的接接收能力比较稳定,你发送数据量以对方接收能力做处理的话,此时网络状况也就不会出现丢包问题,只要不出现丢包问题,网络就可以一直放数据,拥塞窗口大小也会一直在增长。另外网络发送拥塞时随时随地都有可能发生的。在TCP看来,如果不发生网络拥塞的话,拥塞窗口大小也可以不用变化。这个拥塞窗口就是被探测出来的结果,因为网络是变化的。
延迟应答
如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.- 假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
- 如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
那么所有的包都可以延迟应答么?
肯定也不是;比如我这个报文的超时时间特别短,那么这个延迟就可能出问题,不是所有的报文都可以延迟应答的。比如,我处理数据的速度本来就慢,上层取数据的时间非常慢,那么延迟应答的作用就不明显,如果上层取数据特别快,那么延迟应答的效率就特别高。
假设今天适用于延迟应答,延迟应答有哪些策略呢?
具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms;
- 数量限制: 每隔N个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
eg:每两个报文给对方一次ACK

捎带应答
本来我给你发个消息,你要立马给我ACK,可是我在给你ACK的时候只是一个裸的报文 (也就是TCP报头,没有数据),实际上我也可以给你ACK的同时,给这个报文携带上数据,也就是你想给我发数据,我也想给你发数据。 我给你发数据的时候我把我的ACK位置为1表示对你报文的确认,同时我这个报文还携带了有效数据,这就叫做捎带应答。捎带应答实际上就已经是我们TCP最真实的通信场景了。意思就是说我们可不仅仅是发一个你给我应答,发一个你给我应答;后来我们升级成了一次发很多,你给我应答;现在我们又知道了,你一次给我发很多,我给你每个报文或者是延迟应答的报文进行确认,确认的同时,我也给你的确认报文里面可以在携带所谓的有效数据。所以我们一般在TCP的通信场景里面,TCP的所有报文是既有可能对某台主机的数据只做确认,又有可能既有确认又携带上数据。 正常的通信场景下,主机A和B大部分情况下是既有ACK又携带数据,除非是单向的,主机A只给主机B发消息,那么主机B就只能ACK,没有数据,或者是在某些特殊情况下不携带数据,比如说握手和挥手的时候,此时就是纯的ACK,否则大部分情况下都会携带ACK和数据。这就是为什么很多网络教材中会说几乎所有报文的ACK都被置1了,因为你给我发报文的时候同时也是上一个报文的确认。 类比生活着理解捎带应答 比如说:我问你吃了吗,我首先确认的是,我这句话你听到了。你说“嗯”。然后你可能也想同步的跟我说话“那你吃了吗”,所以我们就可以把“嗯”和“那你吃了吗”压缩成一句话,就是“吃了吗”,“嗯,那你吃了吗”, 此时对我们来讲,当我收到“嗯,那你吃了吗”的时候,我识别到“嗯”,我就认为这是我的ACK,“那你吃了吗”就是你问我的。所以我给你发的消息就是既有确认,又有我给你发的消息。
重新认识3次握手
3次握手实际上应该是4次握手。因为主机A向主机B发送SYN的时候,主机B应该做的其实是ACK,这个意思就是说,主机A问主机B,你能不能给我建立一下连接呢?主机B说好的。因为TCP是全双工的,所以主机B也要给主机A发SYN,主机A给给B发ACK,意思就是说主机B问主机A我能不能和你建立连接呢,主机A说好的。所以3次握手本质上是4次握手和4次挥手一样是为了让双方完成共识的。 我们看见的是3次握手实际上就是因为主机B将ACK和SYN捎带应答了。一次用一个报文表达了两个含义。
面向字节流
什么叫做字节流?
所谓的文件流本质上就是数据流或者字节流。
什么叫做流呢?
创建一个TCP的socket, 同时在内核中创建一个 发送缓冲区 和一个 接收缓冲区; 调用write时, 数据会先写入发送缓冲区中;- 如果发送的字节数太长, 会被拆分成多个TCP的数据包发出;
- 如果发送的字节数太短, 就会先在缓冲区里等待, 等到缓冲区长度差不多了, 或者其他合适的时机发送出去;
- 接收数据的时候, 数据也是从网卡驱动程序到达内核的接收缓冲区;
- 然后应用程序可以调用read从接收缓冲区拿数据;
- 另一方面, TCP的一个连接, 既有发送缓冲区, 也有接收缓冲区, 那么对于这一个连接, 既可以读数据, 也可以写数据. 这个概念叫做 全双工
- 写100个字节数据时, 可以调用一次write写100个字节, 也可以调用100次write, 每次写一个字节;
- 读100个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以一次read 100个字节, 也可以一次read一个字节, 重复100次;
字节流说白了就是数据之间不像UDP,报文和报文之间必须有明显的格式,发了一个报文对方必须收完整的报文,就如同生活中的寄信。而流呢意思就是数据本身并不需要边界,你要写就往里面扔。你要读就直接向里面拿。
比如:家里都有水龙头,你可以去拿水杯接水,也可以去拿水桶接水,可以拿脸盆去接,你完全是按照你的要求去从水管里面把水拿出来,但是你知不知道这个水是怎么来的呢?这个水是水电站的工作人员一桶一桶给你打上来的,还是电机抽上来的,早上抽的,还是晚上抽的,这水在抽的时候是10ml抽,还是10L抽....你完全不关心,你只需要知道水龙头一拧开就有水(数据),你需要多少水(数据)你就拿多少水(数据)。这个数据拿多少,怎么拿完全由上层决定。这个就叫做字节流。
回忆http
http请求是以行位单位陈列的,但是这仅仅是你在应用层这么认为,一旦自己发送的时候到了TCP的缓冲区里,实际上是把http请求拷贝到发送缓冲区里面了,当你在把这些数据拷贝到发送缓冲区里面的时候,你调用send/write,内核有没有把数据发出去呢?
答案是不一定,有可能你调用send/write ,你一直在拷贝,可是网络发生了拥塞,它并不发,所以你把数据拷贝下来,此时这个时候你的http请求全部是以字节流的形式在TCP的发送缓冲区里面存在。接下来TCP发送的时候,TCP并不会说这个是请求行,这个是第一个属性...TCP连管都不管,只要现在能发500个字节了,就把前500个字节发出去,这500个可能是第一行,可能是前3行,可能是前3行+第4行的部分内容...总之TCP完全不关心你的协议是按行发还是怎么样,只关心我能发多少字节,我就是按字节发。此时对于TCP来讲,这个缓冲区就叫做字节流。同样的接收方在收到这个数据时,也不会认为这是http协议,你发过来的不完整,我不收了,而是发送方发多少我就收多少,之后接受缓冲区里的数据是按照什么特定方式被读取就是由应用层决定。在TCP双方就如同流水一般直接把数据从一端倒到另外一端。至于上层想要拿杯子接受,桶接收,都是应用层的事。反正TCP只要保证,应用层只要读我就有数据,你打开水龙头我就有数据,这就可以了,这就叫做字节流。
为什么打开文件叫做文件流?
OS不知道你这个文件是什么,文件里的内容保存的是视频,还是音频,还是代码...OS完全不关心,这个文件里有什么是你关心的,所以你打开一个.txt就喜欢用记事本打开,打开一个视频永远是播放器打开,因为只有用户知道这个文件是干啥的,在OS看来我就认为这个文件里全部放的都是字节流,也就是OS对文件内容不做任何解释,我只关心你要读几个字节,我给你读上来就行。至于你应用层想怎么解释这些个字节,由你的应用层去定。所以曾经读写文件都叫做打开流,因为这是OS的视角。用户的视角就叫做打开配置文件,打开源代码。
粘包问题
我们发送给对方http的时候呢,在接受缓冲区里可能有很多报文,报文和报文都挨着,按照正常的协议请求,你把content-length读到,正文读了,下一次读就是下一个报文的开始。可是如果content-length填错了呢,此时上层要么多读,要么少读,一定会导致这个报文要么一部分被丢了,要么一部分被别人读走了。这就叫做粘包问题。所以单纯的TCP的存在是会存在粘包问题的,所以TCP要不要解决这个问题呢?
答案是TCP根本没有能力去解决这个问题,因为TCP是面向字节流的,解决粘包问题是应用层要解决的,应用层要定制协议,然后根据协议从TCP当中将数据进行取走。
我们以http为例,如果我们要读取这一个数据,我们就不能简单粗暴的去做如下操作:

此时我们就简单粗暴的把一次读取到的内容全部当成一个完整请求,这是不正确的。今天我们读的时候就可以换成这种方式:

这样的话就能正常把一个数据读上来了,虽然这样还有问题,但是就能说明粘包问题了。报头读完在根据content-length读取正文,一个报文就读完了,下次在继续重复这样的操作就能解决粘包问题了,能解决就是因为应用层协议给我们规定好了。
所以协议不仅仅规定每个字段是什么含义,它还要能规定我们双方通信时如何正确读取的问题,所以解决粘包问题,就是TCP的报文我们约定好,采用定长字段,比如我每次给你发报文都发1024个字节,这样的话就不会存在粘包问题了。还有就是特殊字符就能区分一个报文是否结束,假设我给你发的所有文字都以空行作为分隔符,所以你读的时候就按行读,读取到一行就是我要给你说的话。当然也可以像http一样做描述字段,比如先发4字节就代表了后面的长度,然后长度表明是100字节,我就给你发100字节,最后先读4字节,在根据4字节决定你下来要读多少,这就叫做协议。
所以协议不仅仅像http这般告诉我们每个字段的含义,还有一个隐形的协议就是协议的报文也是存在格式的,协议所有报文的格式都是为了方便读取,在今天看来是为了避免数据粘包问题。
因为TCP是面向字节流的,所以它的报文和报文之间是没有边界的,数据一旦放进缓冲区里大家就揉在一起了,同一个东西在不同的视角看待方式是不一样的,所以因为TCP是字节流的,所以TCP收到数据之后,数据本身的解释权不由TCP解释,TCP只是个发数据的,有数据就发数据,报文里面是什么东西不是TCP该关心的,所以粘包问题是由应用层解决的。HTTP协议报文的请求格式就是为了方便对方读取,也就是为了解决报文和报文之间的粘包问题。
生活中例子:比如你妈蒸包子,刚蒸出来包子就是粘在一起的,如果刚出炉直接上手拿一个包子,就有可能这个包子就带着其他包子上来了,要么这个包子就拿到了一半,甚至你只拿了个皮。这就是粘包。所以一般爸爸妈妈的做法是,蒸出来之后先不拿,而是把包子进行分开,包子和包子之间分开,包子和底之间分开,分开之后在晾一下你在吃。此时,把包子和包子分开就叫做分离包子和包子的边界。从而让你下一次拿的时候,不会因为一个包子而影响另外一个包子,这就叫做解决粘包问题。
TCP异常情况
对我们来讲,如果此时我们曾经创建好的连接如果出现了问题该怎么办呢?
比如进程终止了,曾经建立好的连接会怎么样呢?
所谓的连接,双方通信在应用层就是文件。PS: linux和windows版的套接字编程只有3行代码不一样,无非就是头文件包含,引入socket库,还有打开一个对应的套接字资源这三步不一样,其他的几乎全部一样,因为大家用的都是TCP协议,所以OS的接口也肯定是一样的(这可不是由OS决定的,是由TCP/IP协议去统一规定的)。所以你想写一个linux和windows通信的程序成本也很低。
在应用层连接就是文件描述符就是文件,所以如果我已经建立好连接,突然连接终止了,甚至这个终止是被我kill掉的,或者是自己挂掉的,那么进程终止就会释放文件描述符,和正常关闭没什么区别。文件的生命周期是随进程的,意思就是你打开一个文件,如果你的进程突然异常或者正常崩溃了,其中你的文件描述符自动就关闭了,所以你不用担心文件描述符被关闭的问题,网络也是一样。网络通信的时候打开的是文件,也是以文件的方式来进行操作的,所以一旦进程终止了,实际上OS会自动回收这个进程打开的文件资源,文件描述符也会自动关,这是文件。文件的生命周期是随进程的,在网络里实际上也是类似的,所以一旦你的进程出现了终止或者崩溃,OS被关掉,在底层对应的就是它会自动4次挥手。所以进程一旦终止,底层会自动进行4次挥手,比如说:客户端连上服务器,然后直接把服务器给退出,此时连接还在,但是服务器没了,所以服务器的连接状态由listen直接就变成CLOSE_WAIT,如果进程终止底层没有进行4次挥手,怎么可能进入CLOSE_WAIT呢。连接一旦建立好,进程终止,这个连接在底层OS自动4次挥手,这也是通信细节。
如果我在电脑上建立好大量的连接,突然我的机器直接重启了会怎么样呢?
当你的电脑进行重启时,如果有些进程是打开的,你就会发现windows就会提醒你,这个文件正要被关闭,请问是否要进行保存,你点击是,就给你保存了,然后进行关机。所以一个进程要关机时,要把用户进程先关掉。所以当你重启前电脑上建立着大量的连接,TCP协议在你机器底层就会先进行各种4次挥手,4次挥手把连接断开之后,然后在完成正常的关机动作。
如果机器掉电或者网络断开了会怎么样呢?
这个时候对端没有办法知道你的网络状态,因为这种情况属于OS直接挂掉了,就是一瞬间的事,4次挥手是要花很长时间的,一瞬间就挂掉了,它连发送断开连接的请求都没时间。你就没办法和对方正常通信了,交互没有了,随以对方也就不可能知道了,所以此时你突然掉电或者网络断开,对方是不可能知道你的信息的,对方不可能知道你的信息,客户端该咋样咋样,服务端就只能超时一段时间,就比如这个连接怎么挂上我长时间不给我反馈呢?它还会定期问一问你还在不在。只要客户端确认就认为你还在。再比如我是个服务你是个连接,连接早没了,一旦服务端询问客户端,客户端就发现你怎么还给我发消息,我们的连接不是早就关闭了吗?此时客户端就可以给服务器发送RST报文,服务器立马就意识到连接造没了,此时就把连接RST,就是把连接释放了。
RST标志位就是用来处理这些特殊情况,像进程终止,网线断开,机器掉电这种情况你压根就不知道,包括路由器出问题了...所以网络里一定要存在对连接重置的一个标志位就是RST。
eg:如我们玩一些在线对战游戏,我不想让官方扣我的信誉积分,我就不采取逃跑的方式,而是采用拔网线的方式。把网线一拔,系统就会判断掉线了,你的客户端就不会给服务器发任何数据。 所以网络出问题,服务器是不知道你出现什么问题,所以你不能扣我分,这个是不可抗拒的因素。如果你不想打游戏直接强制退出,你用的就是客户端退出,就是客户端在给服务器发消息,服务器就可以收集你退出的行为,它就知道你是逃跑的。但如果拔了网线,连接断开的数据都发不过去,所以正常情况下你自己的退出信息也发不出去。所以当你不想玩游戏了,你直接一拔网线,然后在退出客户端,一般服务器不怎么强的服务就判定你是网线掉了,也就不扣你的分了。
另外, 应用层的某些协议, 也有一些这样的检测机制. 例如HTTP长连接中, 也会定期检测对方的状态. 例如QQ, 在QQ断线之后, 也会定期尝试重新连接.TCP小结
为什么TCP这么复杂? 因为要保证可靠性, 同时又尽可能的提高性能.可靠性:
- 校验和
- 序列号(按序到达)
- 确认应答
- 超时重发
- 连接管理
- 流量控制
- 拥塞控制
- 滑动窗口
- 快速重传
- 延迟应答
- 捎带应答
- 定时器(超时重传定时器, 保活定时器, TIME_WAIT定时器等)
基于TCP应用层协议
- HTTP
- HTTPS
- SSH
- Telnet
- FTP
- SMTP
当然, 也包括你自己写TCP程序时自定义的应用层协议
TCP/UDP对比
TCP和UDP在传输领域就是两个极端,要么非常可靠,要么就不关心可靠性。一旦两种技术比较极端就意味着它的特点非常的明显,世界上没有绝对好和绝对坏的事情。特征明显更容易被人选中。
- TCP用于可靠传输的情况, 应用于文件传输, 重要状态更新等场景;比如请求http协议,请求网页,请求上传下载数据,包括ssh登录linux,因为这些数据一个也不能丢。就比如你用linux命令(如果是UDP),你输入ls,对方收到了l,完全就是糟糕的用户体验。
- UDP用于对高速传输和实时性要求较高的通信领域, 例如, 早期的QQ, 视频传输(直播)等. 另外UDP可以用于广播;比如直播:udp把报文发送到服务端,服务端收到之后,就把直播者的图形,画面,声音统一广播给大家,就相当于把直播者的声音,图形数据打上udp报文,然后把报文不断的经过直播软件的服务端,直播平台的服务端收到直播者的报文,然后把报文做一个转发,每个想看直播的人都得登录直播软件的客户端,这就是看直播的人拿着自己的客户端和直播软件通信,直播者自己的客户端和直播软件通信,直播者的客户端是上传端,观看直播的客户端是下载端,所以此时就可以不断的进行直播了。再比如看视频画质选择自动就是UDP。
看直播延迟是怎么做到的呢?
直播者的数据是直接上传到了直播软件的平台中,观看直播的人看到的直播内容是直播软件把直播者曾经上传的数据给推送过去,延迟就是推送的晚一些,推送的晚一些还要推送,就是它把直播者可能有3~5秒的数据可能缓存了起来,缓存一下再推送给大家,这就是有延迟的一个原因。
为什么要这么干呢?
如果今天它上传上去的数据直接就立马推给你,对服务端的配置要求是特别高的,因为实时性要求就高了,你可以简单的理解成,它必须把数据上传上来的同时,也必须立马把数据发送出去,而且也没有办法对直播者说的内容有相关方面的侦测,比如说的话可能是一些违法违纪的内容,缓存过后就可以有充足的时间对直播者说的内容做进行文本识别。而且带一个缓存可以让直播平台的容错率更高,比如:如果今天不缓存,我给你发送的消息必须全部都得立马转过来,如果今天在直播平台的人直播的人太多,那么这个平台就忙不过来了,但是如果今天有缓存,我只负责把数据上传上去,然后我不着急给你推送,我就可以给每个人维护一点缓存数据,这样的话,平台就可以更从容一些,直播平台压力比较大就可以慢慢的推送数据,直播平台压力比较小就可以快一点推送数据,这也就是每次看直播它的延迟情况都是不一样的。
网络通信都不允许丢包吗?
并不是所有的网络通信都不允许丢包的,以直播为例,选择UDP,哪里网络不好了就动态调整,发送数据量,就可以做到比较高效稳定。所以如果在用户角度,我如果用TCP,我这里是高清的,你必须也收到高清的,如果网络状况有差别,别人观看正常,你观看就十分卡顿,这样的产品体验反而不好,UDP就是你网络好看到的就是高清的,网络不好看到的模糊点。虽然会有观看体验的起伏,但是不会卡顿,这就是UDP。 归根结底, TCP和UDP都是程序员的工具, 什么时机用, 具体怎么用, 还是要根据具体的需求场景去判定.用UDP实现可靠传输
参考TCP的可靠性机制, 在应用层实现类似的逻辑;我想使用UDP实现可靠性一定是结合场景去谈的,要不然我直接用TCP可以了,我只是想实现一个轻量化的,可以引入部分的TCP策略。 比如说:QQ聊天,用UDP实现可靠性,我们用UDP就是存在丢包问题,实际上我们只需要保证数据能进行确认应答,能够进行按序到达,能够进行重传就可以了。又不是大文本,大内容就是一些很小的报文。 例如: 引入序列号, 保证数据顺序; 引入确认应答, 确保对端收到了数据; 引入超时重传, 如果隔一段时间没有应答, 就重发数据;TCP 相关实验
理解 listen 的第二个参数
Sock.hpp
#pragma once#include
#include
#include
#include
#include
#include
#include
#includeusing namespace std;
class Sock
{
public:static int Socket(){int sock = socket(AF_INET, SOCK_STREAM, 0);if (sock < 0){cerr << "socket error" << endl;exit(2); //直接终止进程}int opt = 1;setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)); return sock;}static void Bind(int sock,uint16_t port){struct sockaddr_in local;local.sin_family = AF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;if (bind(sock, (struct sockaddr *)&local, sizeof(local)) < 0){cerr<<"bind error!"<= 0){return fd;}return -1;}static void Connect(int sock, std::string ip, uint16_t port){struct sockaddr_in server;memset(&server, 0, sizeof(server));server.sin_family = AF_INET;server.sin_port = htons(port);server.sin_addr.s_addr = inet_addr(ip.c_str());if (connect(sock, (struct sockaddr*)&server, sizeof(server)) == 0){cout << "Connect Success!" << endl;}else{cout << "Connect Failed!" << endl;exit(5);}}
};
之前我们的listen第二个参数一直是5,现在我们将5改成1。

Http.cc
#include"Sock.hpp"
#include
#include
#include
#include
#includevoid Usage(std::string proc)
{std::cout << "Usage: " << proc << "port" << std::endl;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(1);}uint16_t port = atoi(argv[1]);int listen_sock = Sock::Socket();Sock::Bind(listen_sock, port);Sock::Listen(listen_sock); //只允许别人连我,我不获取它for ( ; ; ){sleep(1);}
}
(一)启动服务
(二)建立第1个连接
(三)建立第2个连接
(四)建立第3个连接
(五)建立第4个连接,从此次开始就不会在有新的连接





上层不进行accept,底层是可以把连接建立好的,一旦把连接建立好,上层accept就可以直接把连接取走,底层给我建立好连接,让我去accept的个数是受限制的,不是所有连我的连接都可能会ESTABLISHED建立成功;
因为我们的套接字代码没有accept,所有底层建立好若干个ESTABLISHED再来的就叫做SYN_RECV(这个状态是只要客户端连上我,给我发了SYN,我的状态就叫做SYN_RECV,我也会维持这个状态),意思就是说它当前并不认为3次握手完成了,而是不在继续进行3次握手了,相当于我们服务端因为某种原因而限制了我们只能建立2个已经3次握手成功的连接。一旦太多了,服务器就不让你连了,而是只让你维持一个SYN_RECV状态,3次握手没有完成,也不给你完成。其中,这里我们限制底层在任何一个时刻最多能够进行建立连接成功的个数就叫做listen的第二个参数。
listen的第二个参数+1,描述的就是在TCP层建立正常连接的个数。注意:这个建立正常连接的个数,不是说只能在服务器端维护几个连接。你在服务器端可以accept随便拿。但是只要一个连接已将被建立好且没有被拿走,此时它的个数就由listen的第二个参数进行维护。所以我们在底层维护好的这一个能够被上层随时读走的这个一个东西我们就称为全连接队列(accpetd队列)(用来保存处于established状态,但是应用层没有调用accept取走的请求)而全连接队列的长度会受到 listen 第二个参数的影响.
全连接队列满了的时候, 就无法继续让当前连接的状态进入 established 状态了. 这个队列的长度通过上述实验可知, 是 listen 的第二个参数 + 1.为什么要进行+1呢?
因为这个队列的长度它最少是个1,如果是0的话你就不用进行维护了,listen的第二个参数又是一个整数,如果用户传0,我们就可以通过+1的方式至少保证它是1。
别人在连接的时候你可以通过这1次至少可以让服务冗余出一个被上层读的一个连接。
但我也可以让这个参数限制为至少是1,但是这样的话你得让用户知道,而且listen的第二个参数是会受TCP协议影响的,默认与你的设置有关,也有其他策略保证队列长度。
我们还能发现如果在有新的连接来,它不是ESTABLISHED,而是SYN_RECV也就是客户端只给我发了个SYN,服务端收到SYN后不给客户端应答了,暂时把他吊着,一旦上层连接被取走,一旦全连接空了,我在把他完成3次握手,连接建立好,在放进全连接队列里面。也就说还有一个半链接队列(用来保存处于SYN_SENT和SYN_RECV状态的请求),说人话就是这个半连接队列用来维护一些处于3次握手过程之中的一些连接。对我们来讲只有你握手成功了,你才有可能进入全连接队列。即便是你3次握手成功了,它也不一定会把你的建立成功的连接放到你的全连接队列里。这个半连接队列一旦握手成功,它内部还有一些安全策略,重点是为了主要能够保证我们的连接是安全和健康的。
半连接队列是如何移到全连接队列的?
半连接队列在进行握手的时候会有一些随机数策略保证3次握手来自同一个客户端请求,或者来自同一个客户端的合法请求,只有当你安全认证通过或者安全认证策略通过,这个时候你建立好的连接才会放到全连接队列里。
那我作为一个服务器,有人不攻击我的全连接队列,而是攻击我的半连接队列怎么办?
因为SYN洪水,我只给你发SYN的话,其中大量的连接此时都处于半连接状态,当然你是半连接队列,你是有长度的,这个半连接队列的长度完全是由OS去进行设置的(这个算法很复杂,主要是为了考虑安全性的问题),全连接队列长度由listen第二个参数指定。比如:对于半连接队列,我今天给你发SYN,服务端就处于SYN_RECV状态,此后我客户端就不给服务端发任何ACK了,即便服务端给客户端发SYN+ACK,我客户端也不应答,就相当于半连接来的请求就在你这个半连接队列上挂着,挂着之后,我发送大量的SYN之后,最后这个半连接队列就会被打满,然后你的服务端最后在发SYN+ACK,客户端也不响应你,最后这个半连接队列就被客户端占着,这个客户端也不走,服务端你只能是超时把它给关掉,可是你一关掉,又一个客户端立马就连你了,依次循序,始终占着你的半连接队列,就会导致正常客户半连接队列连不上,那么全连接队列也就进不来。所以恶意分子照样可以通过攻击我的半连接队列来攻击我的TCP请求。
类比生活:就好比我是一个餐厅老板,我的竞争对手雇了一群大爷大妈来我的餐厅,他们也不吃饭,就是坐在那,我一赶他走就躺下了,正常来的客人,来了也没地方坐,所以他们就占着我的资源,也不应答我,所以就起到了攻击我的效果。
TCP针对这种攻击也有自己的策略,在这个半连接队列里还有一个队列,你们必须先连接那个队列,只有那个连接队列审核通过了,你们才能连接半连接队列。其实在握手期间,服务器还有一大套的算法比如用生成随机数的方式进行验证,意识到你是正常客户端时候才会把你放到来接队列里。
为什么要维护队列?为什么这个队列不能太长?为什么这个队列不能没有?
我们今天谈论的是全连接队列。
我们以海底捞为例,海底捞里面会有很多人在吃饭,在海底捞门口有一些对应的过道,过道里面陆陆续续也会有新的人进来想去海底捞里吃饭,比如说你和你的朋友过去了,工作人员看到你过来了就会和你说,先生您好,要过来吃饭吗?你说,是的。服务员就告诉你,不好意思,目前店里面已经坐满了,如果你要吃饭,就得等一等,可是等待的时候不能让人家站着,如果让客人站在等的话,人家不可能一等就等半个小时,客人直接就走了,所以一般海底捞门口就会在自己的门口摆上很多桌椅,对应的工作人员就会给你和你的朋友一个吃饭的号码,让你和你的朋友去休息区等。
假设海底捞门口就没有桌椅,当你和你朋友到的时候,服务员告诉你们要进行等待,可是你看到都没一个进行休息等待的地方,所以大概率就都走了,虽然陆陆续续来了很多人想在这吃放,但是因为都要站着等,所以很多人就都走了。其中恰好有1~2桌客人吃完饭了,恰好目前又没有新的客人来,所以就导致海底捞里面的桌椅被空上了10~20分钟。假设每桌平均消费500,这样的场景每天被复现了5次,复现了5张桌子,出现了20分钟的空档期,假设平均20分钟一张桌子能赚100块,那么这样的话,每天就少挣5次,就是500块,如果这个店有1000家分布全国,每一个店少赚500块,1000个店1天就少赚50万...仅仅是这一个小细节没有做到位,里面客人吃完饭走了导致里面的桌子没有被充分利用,进而导致海底捞这个企业每年可能少赚很多钱。所以老板就规定必须让门口摆上桌椅板凳,设置休息区,此时客人排队的概率就大大增加了。
为什么要维护门口的桌椅板凳让客人可以等待?
此时当有客人离桌的时候,服务员就可以立马让在外面等的客人立马填充进来,就可以保证海底捞里面所有的就餐桌椅始终是被100%利用的,这样的话也就不会造成海底捞内部各个桌椅资源的浪费。
作为海底捞的员工,给客人发放取餐号码的时候就是在给你们排队谁先谁后,让你们去等就是让客人坐在休息区去等,有人愿意等,同样有人也不愿意等。所以门口的桌椅板凳(其实就是队列)最大的意义是当海底捞内部满了的时候,我门一旦有人离开就可以立马把在外部等待的客人接进来。这样做就可以保证海底捞内部始终是资源被100%利用的!这就是队列存在的意义。如果这个队列被坐满了再来客人呢,此时你只能让这批客人流失了,没有办法。
那么队列又这样的好处的话,我为什么不把这个队列搞的多一些,就相当于我把门口的桌椅板凳摆上非常多,这样可以是可以,但是一旦队列太长也就丧失了队列的意义,队列太长的话你得考虑客户的耐心,一旦客户发现有成百上千的人在进行排对,轮到他的时候都到了半夜1:00,这个客人肯定不吃了,所以在排队的话,门口的队列太长是没有意义的。而且桌椅板凳都要钱,再者为什么老板不把海底捞服务的范围扩大,而是要扩大休息区呢。
所以,这个队列不能没有就是因为如果没有队列就会有种风险,当客人离桌时,这个资源不能立马被使用。
这个队列不能太长是因为维护队列是要有成本的,如果你把队列维护的过长,那么对应尾部若干的等待的客户是没有意义的,因为等待的时间太久了,客户体验非常不好,这部分客户最终肯定会流失。与其把队列维护的很长,倒不如把维护队列的成本砍掉,嫁接到服务上,让服务能够提供更多的桌椅板凳。
这个海底捞就相当于是我们自己写的网络服务器提供某种网络服务,一张张桌椅板凳就是文件描述符或者是内存资源,然后这个在门口叫号的服务员就是listen套接字,在海底捞门口排队的队列就相当于是全连接队列。当有新连接到了的时候为什么要维护全连接,这个全连接不能没有就是因为有可能上层的服务太忙了,已经将服务打满了,来不及接收新的客户,我们只能让客户暂时在我们的底层先将队列维护好处于ESTABLISHED状态,当上层调用accept的时候就是把这个客户唤入到我们的服务内部。所以这个队列必须有,如果没有就可能导致内部服务资源没有被充分利用。又因为维护队列是有成本的,维护长队列当然可以,但是客户一旦连接上你长时间没反应他觉得太慢了所以就直接把把网页或者连接关闭了此时你维护也没有意义,倒不如你维护一个短队列,把不维护长队列的资源节省出来供服务去使用,这样就可以让服务以较高的效率给用户提供服务。所以我们维护的全连接队列是一个短队列。