最近阅读的论文总览
自留记录论文阅读,希望能了解我方向的邻域前沿吧
粗读,持续更新
第一篇
ATTEND TO WHO YOU ARE: SUPERVISING SELF-ATTENTION FOR KEYPOINT DETECTION AND INSTANCE-AWARE ASSOCIATION
翻译:https://editor.csdn.net/md?not_checkout=1&spm=1001.2014.3001.5352&articleId=129070593
无代码
摘要:
本文提出了一种利用Transformer解决关键点检测和实例关联问题的新方法。对于自底向上(Bottom up)的多人姿态估计模型,需要检测关键点并学习关键点之间的关联信息。我们认为,Transformer可以完全解决这些问题。具体来说,vision Transformer中的自注意度量任何一对位置之间的依赖关系,这可以为关键点分组提供关联信息。然而,朴素注意模式仍然没有被主观控制,因此不能保证关键点总是注意到它们所属的实例。为了解决这一问题,我们提出了一种监督多人关键点检测和实例关联的自我注意方法。通过使用**实例掩码(instance mask)**来监督自注意,使其具有实例感知性,我们可以根据成对的注意分数将检测到的关键点分配给相应的实例,而无需使用预定义的偏移向量字段或像基于CNN的自底向上模型那样的嵌入。该方法的另一个优点是,可以直接从监督注意矩阵中获得任意人数的实例分割结果,从而简化了像素分配流程。通过对COCO多人关键点检测任务和人实例分割任务的实验,验证了该方法的有效性和简单性,为特定目的的自我注意行为控制提供了一种很有前景的方法。
本文采用自底向下的方法,自底向上的方法需要首先检测所有的身体关节,然后将它们分组到人体实例中。
文中,我们探讨是否我们可以利用实例语义线索,来将检测到的关键点分组到单独的实例中。我们的主要直觉是,当模型预测特定关键点的位置时,它可能知道该关键点所属的人类实例区域,这意味着模型将相关关节隐含地关联在一起。例如,当一个肘关节被识别时,模型可能会在邻近的手腕或肩膀上识别出它的强空间依赖性,但在其他人的关节上识别出弱空间依赖性。因此,如果我们可以在模型中读出这些学习和编码的信息,检测到的关键点可以被正确地分组到实例中,而不需要人类预定义的联想信号的帮助。

提到2个模式
朴素自我注意模式和监督自我注意模式:关节点分组提供关联信息。
我们认为,基于自我注意的Transformer满足这一要求,因为它可以在任何一对位置之间提供特定于图像的成对相似性,而不受距离限制,并且产生的注意模式显示了与对象相关的语义。因此,我们尝试利用自我注意机制进行多人姿态估计。但是,我们没有采用以单人区域作为输入的自顶向下策略,而是向Transformer提供包含多人的高分辨率输入图像,并期望它输出编码多人关键点位置的热图。初步结果表明,
1)Transformer输出的热图也能准确响应多个候选位置的多人关键点;
2)检测到的关键点位置之间的注意得分在同一个体内较高,而在不同个体间较低。
基于这些发现,我们引入了一种基于注意力的解析算法来将检测到的关键点分组到不同的人实例中。
不幸的是,naive的自我注意力并不总是表现出令人满意的特性。在许多情况下,一个被检测到的关键点也可能与那些属于不同的人实例的关键点具有相对较高的注意力得分。
解决办法:
利用一个损失函数,通过每个人实例的掩码来显式地监督每个人实例的注意区域。
模型

模型体系结构由三个部分组成:一个常规ResNet、一个常规Transformer编码器和几个转置的卷积层。两种类型的损失函数被用来监督模型训练。模型的最终输出由groundtruth关键点热图监督。直接的自我注意层之一由实例掩码稀疏地监督。特别地,我们根据每个人实例的可见关键点位置对所选注意层的注意矩阵行进行采样,将其重塑为类似于2d的maps,然后使用每个实例的掩模来监督average map。在该图中,为了简单起见,我们只显示每个实例的几个关键点。
网络架构参照Transpose设计
naive self-attention 我们从热图中获取关键点位置,并进一步可视化这些位置的关注区域。如图1的例子所示,使用朴素的自注意矩阵作为关联参考。
第二篇
【论文阅读笔记】(2021 ICCV)Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
写在前面(中文版自己总结)
之前的 AR(Action Recognition) 有两种做法:
(1)end-to-end:就是普通的 AR,输入 RGB frames,输出动作的类别。
(2)pose based:基于骨架点做的 AR
其中,end-to-end 学习到的 representation 容易 bias 到 some visual patterns,eg:basketball,rather than the action itself;
pose based 的问题就是他需要有个前提:pose label should be accurate 这就要求 pose estimation algorithm 非常 robust,或者 requires expensive human annotation work
这篇文章的做法就是利用 end-to-end 的思想,希望输入是 RGB frames,输出是动作类别。
但巧妙的是,它用一个 student encoder + decoder 去 match teacher(a pose estimator pretrained on a generic dataset)的 output feature,让 student encoder 去 focus 在一些利于进行 pose estimation 的 action representation,从而约束网络尽量少 bias 到 action-irrelated visual patterns 上。
此外,当 teacher 的 confidence 不高的时候,还可以利用一些 visual patterns 进行 AR。
但是。。。弱弱问一句,文章里提到的 weakly-supervised 是不是有点不合适?
Contributions
-
A weakly-supervised method, VPD, to adapt pose features to new video domains, which significantly improves performance on downstream tasks like action recognition, retrieval, and detection in scenarios where 2D pose estimation is unreliable.
-
State-of-the-art accuracy in few-shot, fine-grained action understanding tasks using VPD features, for a variety of sports. On action recognition, VPD features perform well with as few as 8 examples per class and remain competitive or state-of-the-art even as the training data is increased.
-
A new dataset (figure skating) and extensions to three datasets of real-world sports video, to include tracking of the performers, in order to facilitate future research on fine-grained sports action understanding.
引言
现有的姿势估计器往往只使用简单动作的视频数据进行训练,其中缺乏细粒度运动的标签标注。因此,直接将这类估计器应用在具有挑战性的体育视频时,模型会在遇到复杂模糊、遮挡和较快节奏的情况时,预测失败,而且往往出现在那些对行为决策至关重要的几帧中,这会严重影响后续行为识别的结果。下图展示了一些预测失败的例子。

基于上述分析,本文提出的VPD方法设计主要遵循以下三点:
-
VPD仍然与端到端的监督学习方法一样,可以充分挖掘原始视频中的视觉模式(包括但不限于运动员的姿势),并在姿态估计失败时继续工作。
-
在模型的蒸馏学习阶段,只有当教师网络作出较高置信度的姿态预测时,模型才进行蒸馏约束,这样做可以避免过度拟合与运动员动作无关的视觉模式。
-
弱监督的训练设定允许我们对模型加入额外的约束。例如不仅要求学生网络预测实时的运动姿态,还需要预测出当前姿态的运动梯度,这有助于学生网络对一些运动的时序规则进行建模,捕获其随着时间推移而形成的视觉相似性特征。
方法
我们的策略是将现有的、现成的姿势检测器–老师–的不准确的姿势估计,在通用的姿势数据集上进行训练,提炼成一个–学生–网络,专门为特定的目标运动领域的视频生成鲁棒的姿势描述符。学生把围绕运动员裁剪的RGB像素和光流作为输入。它产生一个描述符,我们从该描述符中回归到教师发出的运动员姿势。我们在一个大型的、未经剪裁的、没有标签的目标领域视频语料库上运行这个提炼过程,使用稀疏的高置信度的教师输出作为学生的弱监督。由于教师已经被训练过,VPD不需要在目标视频领域进行新的姿势注释。同样,也不需要下游的特定应用标签(例如用于识别的动作标签)来学习姿势特征。

教师网络
(1) 首先使用一个现成的姿势估计器[45],从第t帧的RGB像素xt中估计2D关节位置。我们将其称为2D-VPD,因为教师生成了2D关节位置。
(2) 我们的第二个教师变体将二维关节位置进一步处理为视图不变的姿势描述符,以pt的形式发出。我们的实现使用VIPE⋆来生成这个描述符。VIPE⋆是对Pr-VIPE[44]概念的重新实现,它被扩展为在额外的合成三维姿势数据[32, 38, 63]上进行训练以获得更好的泛化。我们将这一变化称为VI-VPD,因为教师生成了一个视图不变的姿态表示。
学生特征提取器
我们设计了一个学生特征提取器,对运动员的当前姿势pt和姿势变化率∆pt := pt - pt-1的信息进行编码。该学生是一个神经网络F,它消耗一个彩色视频帧xt∈R3hw,围绕着运动员进行裁剪,以及它的光流jt∈R2hw,来自前一帧。h和w是裁剪的空间尺寸,t表示帧索引。
学生产生一个描述符F(xt,jt)∈Rd,其维度与教师的输出相同。我们将F实现为一个标准的ResNet-34[18],有5个输入通道,我们将输入作物的尺寸调整为128×128。
在蒸馏过程中,F发出的特征通过一个辅助解码器D,该解码器预测当前姿势pt和时间导数Δpt。利用视频的时间性,∆pt提供了一个额外的监督信号,迫使我们的描述器除了捕捉当前姿势外还捕捉运动。D被实现为一个全连接的网络,我们使用以下目标来训练组合学生路径D◦F。
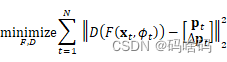
由于在推理过程中只需要F来产生描述符,我们在训练结束时丢弃D。
数据选择。我们从教师的弱监督集合中排除姿势置信度低的帧(具体而言,平均估计联合得分)。默认情况下,阈值为0.5,尽管网球比赛中使用了0.7。
实验结果
本文在四个具有代表性的细粒度体育视频数据集上进行了实验,分别是Firue skating、Tennis、Floor exercise和Diving48。四个数据集中都包含一定数量的快速运动和模糊运动(例如翻转或俯冲)的视频帧,但是这些帧对于识别当前运动行为的类别往往起到关键作用,因此有效的估计和捕获这些帧的时序信息对于下游任务至关重要。
作者首先进行了最关键的细粒度行为识别实验,实验选择了三个baseline:
-
直接使用教师网络对测试数据提取特征,随后使用相同的下游行为识别模型和数据增强手段。
-
使用基于骨架(Skeleton-based)的行为识别方法。
-
使用传统的端到端的行为识别方法。
为了模拟现实场景中标注数据较少,但未标记和目标域数据较多的情形,作者设计了few-shot的实验环境,实验效果如下图所示:

其中2D-VPD和VI-VPD分别对应上文提到的两种教师姿态估计网络的变体,从中也可以看到,在FSJump6和Tennis7数据集上,本文方法已经可以超过其对应的教师网络。随着支持样本数量 k 的增加,本文方法展现出了相比传统方法更好的性能。
为了进一步探索蒸馏学习对该任务的改进来源,作者设计了三种形式的消融实验:
-
分析蒸馏方法的输入。
-
仅使用视频的关键运动片段进行蒸馏。
-
在完全无标注的大规模视频上进行蒸馏。
下表展示了实验结果:

表(a)在FX35和Diving48数据集上的结果表明,VPD的蒸馏效果在仅有RGB作为输入时已经非常明显,当加入光流时,可以进一步提升小样本数据的识别性能。但是仅使用关键运动片段进行蒸馏的效果却很差,结果如表(b)所示,可能是因为缺乏了丰富的运动上下文信息,这也侧面印证了使用更多的视频蒸馏可以有效提高特征的质量。
总结
本文提出的VPD方法以一种明确的蒸馏形式从现有姿态估计网络中获取知识,提高了学生网络在标签受限和运动模糊等场景中的姿态估计能力,VPD学习得到的特征也可以有效提高目标视频域中细粒度行为理解任务的性能。虽然VPD提取的特征可以在数据受限场景中提高模型的精度,但是其在小样本和半监督任务上的性能仍有很大的提升空间。
第三篇
非精读BERT-b站有讲解视频(跟着李沐学AI)
(大佬好厉害,讲的比直接看论文容易懂得多)
写在前面
-
在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真正被Mask的那些tokens?
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一:
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
3)10%的时候是原来的token(保持不变,个人认为是作为2)所对应的负类)。如,my dog is hairy——>my dog is hairy -
在实现损失函数的时候,怎么确保没有被 Mask 的函数不参与到损失计算中去;
label_weights就像一个过滤器,将未mask的字的loss过滤掉了。(建议看源码,我没有看代码) -
BERT的三个Embedding为什么直接相加?
https://www.zhihu.com/question/374835153 -
BERT的优缺点分别是什么?
在本篇论文的结论中最大贡献是双向性
选了选双向性带来的不好是什么?做一个选择会得到一些,也会失去一些。
缺点是:与GPT(Improving Language Understanding by Generative Pre-Training)比,BERT用的是编码器,GPT用的是解码器。BERT做机器翻译、文本的摘要(生成类的任务)不好做。
但分类问题在NLP中更常见。
完整解决问题的思路:在一个很大的数据集上训练好一个很宽很深的模型,可以用在很多小的问题上,通过微调来全面提升小数据的性能(在计算机视觉领域用了很多年),模型越大,效果越好(很简单很暴力)。
BERT使用的数据量级很大(BERTbase是1亿,BERTlarge是3亿{BERT}_{base}是1亿,{BERT}_{large}是3亿BERTbase是1亿,BERTlarge是3亿) -
你知道有哪些针对BERT的缺点做优化的模型?
https://zhuanlan.zhihu.com/p/347846720
未看,想看可以转到这里 -
BERT怎么用在生成模型中?
不知道,咋用?
贡献:
- 我们演示了双向预训练对语言表示的重要性。与Radford等人(2018)使用单向语言模型进行预训练不同,BERT使用MLM来实现预训练的深度双向表示。这也与Peters等人(2018a)形成了对比,后者使用了独立训练的 left-to-right 和 right-to-left的LMs的浅层连接。
- 我们展示了预先训练的表征减少了对许多精心设计的任务特定架构的需求。BERT 是第一个基于微调的表征模型,它在大型句子级和标记级任务上实现了最先进的性能,优于许多特定于任务的架构。
BERT模型
由Transformer推叠而成,关于Transformer看《Attention Is All You Need》或我之前的文章。
BERT分为两个任务:

pre-traning:在预训练过程中,该模型在不同的预训练任务上对未标记的数据进行训练。
BERT使用两个无监督的任务对BERT进行预训练。这个步骤如上图的左侧所示。
-
MLM(Masked Language Model):我们简单地随机屏蔽一些百分比的输入标记,然后预测这些掩蔽标记。在我们所有的实验中,我们随机屏蔽了每个序列中15%的所有WordPiece标记。我们只预测被掩蔽的单词,而不是重建整个输入。
-
NSP(Next Sentence Prediction):一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
fine-tuning:为了进行微调,首先使用预先训练好的参数初始化BERT模型,并使用从下游任务中获得的标记数据对所有参数进行微调。如上图右侧表示。
对于不同的下游任务,BERT结构都可能有轻微变化
BERT的输入:
分别是对应的token,分割和位置 embeddings,三者相加。

1.2 BERT的输出
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

BERT的输出
C为分类token([CLS])对应最后一个Transformer的输出, 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
参考
知乎
上一篇:C#基础教程14 结构体
下一篇:ALSA学习(3)——声卡的创建