计算机网络【王道】
文章目录
- 第一章 计算机网络体系结构
- 计算机网络概述
- 计算机网络的概念
- 计算机网络的组成
- 计算机网络的功能
- 计算机网络的分类
- 计算机网络的性能指标
- 计算机网络体系结构与参考模型
- 计算机网络分层结构
- 计算机网络协议、接口、服务的概念
- ISO/OSI 参考模型和 TCP/IP模型
- 第二章物理层
- 基本概念
- 数据通信相关术语
- 三种通信方式
- 两种数据传输方式
- 码元&波特&速率&带宽
- 信号失真
- 奈氏准则
- 香农定理
- 区别
- 编码&调制
- 基带信号&宽带信号
- 编码和调制
- 四种编码调制方法
- 数字数据调制为模拟信号
- 模拟数据编码为数字信号
- 模拟数据调制为模拟信号
- 传输介质
- 导向性传输介质
- 非导向性传输介质
- 物理层设备
- 中继器
- 集线器
- 第三章
- 基本概念
- 封装成帧&透明传输
- 封装成帧
- 透明传输
- 组帧
- 差错控制
- 检错编码
- 纠错编码
- 流量控制
- 停止等待协议
- 详解停等协议
- GBN后退N帧协议
- SR协议
- 介质访问控制
- 静态划分信道四方法
- 频分多路复用FDM
- 时分多路复用TDM(静态)
- 改进的时分复用-统计时分复用STDM(动态)
- 波分多路复用WDM
- 码分多路复用CDM(重点)
- 动态分配信道
- 轮询访问介质访问控制
- ALOHA协议
- CSMA协议
- CSMA/CD协议
- CSMA/CA协议
- 局域网基本概念&体系结构
- 以太网
- 无线局域网
- 广域网
- PPP协议
- HDLC协议
- PPP协议 VS HDLC协议
- 链路层设备
- 网桥
- 网桥分类
- 第四章 网络层
- 网络层功能概述
- 数据交换方式
- 电路交换
- 报文交换
- 分组交换
- 数据报方式,虚电路方式
- 数据报(因特网在用)
- 虚电路
- 数据报VS虚电路
- IP数据报协议
- TCP/IP协议栈
- IP数据报格式
- IP地址的分类
- 介绍一下IP地址的结构
- 分类
- 特殊的IP地址
- 私有IP地址
- 网络地址转换NAT
- 子网划分
- 子网分组的转发
- 无分类编址CIDR
- 构成超网
- 地址解析协议 ARP
- 动态主机配置协议 DHCP
- 网际控制报文协议 ICMP
- ICMP差错报告报文
- ICMP询问报文
- IPv6
- 路由算法
- 分层次的路由选择协议
- 路由信息协议RIP
- RIP协议报文字段
- 优缺点
- 开放最短路径优先 OSPF 协议
- 链路状态路由算法
- OSPF的区域
- OSPF分组
- 边界网关协议 BGP
- 三种协议比较
- IP组播
- IP组播地址
- 硬件组播
- 网际组管理协议IGMP
- 组播路由选择协议
- 移动IP
- 网络层设备
- 路由器
- 第五章 传输层
- 阐述层概述
- TCP & UDP
- 传输层的寻址与端口
- UDP协议
- UDP首部格式
- 用伪首部进行UDP校验
- TCP协议
- TCP协议的特点
- TCP报文段首部格式
- TCP连接管理
- TCP的连接建立
- SYN洪泛攻击
- TCP连接释放
- TCP可靠传输
- TCP流量控制
- TCP拥塞控制
- 慢开始和拥塞避免
- 快重传和快恢复
- 第六章
是之前看网课做的笔记
第一章 计算机网络体系结构
计算机网络概述
计算机网络的概念
计算机网络就是一些互联的,自治的计算机系统的集合
- 广义观点:只要能实现远程信息处理的系统
- 资源共享的观点:以能够相互共享资源的方式互联起来的自治计算机系统的集合
- 目的:资源共享
- 组成单元:分布在不同地理位置的多台独立的“自治计算机”
- 统一规则:网络协议
- 用户透明性观点:用户使用网络就像使用一台单一的超级计算机,无须了解网络的存在、资源的位置信息。
计算机网络的组成
-
从组成部分看:硬件,软件,协议。
- 硬件:主机(端系统),通信链路(双绞线,光纤),交换设备(路由器,交换机),通信网卡(网卡)
- 软件:资源共享软件和用户工具(网络操作系统,邮件收发程序…)
- 协议:规定网络传输数据的规范
-
从工作方式看

- 边缘部分:主机,端系统。
- 核心部分:网络,路由器。
-
从功能上看
- 通信子网:数据 传输,交换,控制,存储,实现通信
- 各种传输介质
- 通信设备
- 网络协议
- 资源子网:实现资源共享的设备及软件的集合
- 通信子网:数据 传输,交换,控制,存储,实现通信
计算机网络的功能
- 数据通信
- 资源共享
- 分布式处理
- 提高可靠性
- 负载均衡
计算机网络的分类
-
按分布范围分类
- 广域网WAN:10km~9000km,长距离通信,交换技术
- 城域网MAN:5km~50km。多采用以太网
- 局域网LAN:10m~9km。广播技术
- 个人区域网PAN:10m。
-
按传输技术分类
- 广播式网络:共享公共通信信道。
- 点对点网络:一对一进行通信,判断方式是否使用分组存储转发和路由选择机制。
-
按拓扑结构分类

- 总线形
- 星形网络
- 环形网络
- 网状网络,常用于广域网
-
按使用者分类
- 公用网
- 专用网
-
按交换技术分类
- 电路交换技术:源结点和目的结点建立通路传输数据
- 三阶段:建立连接,传输数据,断开连接
- 优点:直接传送,延时小
- 缺点:线路利用率低
- 报文交换技术:加上辅助信息,封装成报文。传到相邻结点,再到下一个结点
- 优点:充分利用线路容量,可以实现差错控制
- 缺点:增大了资源开销;缓冲区难以管理
- 分组交换技术:数据分块,存储-转发
- 具有报文优点,同时易缓冲管理
- 用于现在的主流网络
- 时延问题,不能实时
- 电路交换技术:源结点和目的结点建立通路传输数据
-
按传输介质分类
- 有线:双绞线,同轴电缆
- 无线:蓝牙,微波,无线
计算机网络的性能指标
-
带宽Bandwidth,Hz:原本是某个信号具有的频带宽度,最高频率与最低频率之差。单位是Hz。计网中,带宽用来表示单位时间中网络从一点到另一点所通过的最高数据率,单位”比特每秒“,同最高数据传输速率b/s。带宽的1Mb/s就是可以往链路发送1Mb的数据量。(在计算机网络中带宽用来表示网络中某通道传送数据的能力,网络带宽指在单位时间内网络中的某信道所能通过的“最高数据率”,单位也是bit/s。)
-
时延Delay:数据从网络(链路)的一端到另一端所需的时间。单位s。
-
发送时延(传输时延):发送分组到链路上(传输到链路的过程),第一比特到最后一比特时间
发送时延=分组长度信道宽度(发送速率,实际发送速率大多达不到带宽)发送时延= \cfrac{分组长度}{信道宽度(发送速率,实际发送速率大多达不到带宽)} 发送时延=信道宽度(发送速率,实际发送速率大多达不到带宽)分组长度 -
传播时延:一个比特从一端到另一端时间,取决于电磁波传播速度和链路长度。(比特流在信道上传输显示的效果就是电磁波传播的速率)
传播时延=信道宽度电磁波的传播速率传播时延=\cfrac{信道宽度}{电磁波的传播速率} 传播时延=电磁波的传播速率信道宽度
区分:发送时延是发生在主机上的,传播时延是发生在主机外的。 -
排队时延:等待输出/入链路可用的时间。
-
处理时延:存储转发的处理时间,比如检错,找出口。
-
-
时延带宽积:第一个比特到终点,发送端发送了多少比特。(某端链路现在有多少比特)。单位为bt。
时延带宽积=传播时延(一个比特从一端到另一端时间)∗信道带宽(发送可达到的最高速率)时延带宽积=传播时延(一个比特从一端到另一端时间)*信道带宽(发送可达到的最高速率) 时延带宽积=传播时延(一个比特从一端到另一端时间)∗信道带宽(发送可达到的最高速率)
-
往返时延RTT:发送方发送数据到发送方收到接收方的确认(接收方收到数据后立刻发送确认)总共经历的时延。
RTT包括:往返传播时延=传播时延*2,末端处理时间(接收方可能对数据的处理)。只是信道上所用的时间,不包括传输时间。
-
吞吐量:单位时间通过某个网络(或信道,接口)的数据量。单位b/s,kb/s… 吞吐量受网络的带宽或者额定速率的限制。
-
速率(数据率,数据传输率,比特率):比特是计算机数据量的一个单位,连接在计算机网络上的主机在数字信道上传送数据位数的速率。b/s(比特/秒,B是字节单位,b是比特单位)
-
信道利用率
信道利用率=有数据通过时间(有+无)数据通过时间信道利用率=\cfrac{有数据通过时间}{(有+无)数据通过时间} 信道利用率=(有+无)数据通过时间有数据通过时间 -
网络利用率:信道利用率加权平均值。
-
吞吐量是实际单位时间传输的数据量,带宽100Mb/s,一条链路的速率是20MB/s,另一条是10Mb/s,那么吞吐量就是30Mb/s。速率是实际的速率,带宽是理想条件下的能达到的最高的速率。
计算机网络体系结构与参考模型
计算机网络分层结构
进行分层
每层的报文都有两部分

上一层的PDU作为下一层的SDU

层次结构含义
- 第n层的实体不仅要使用第n-1层的服务来实现自身定义的功能,还要向第n+1层提供本层的服务,该服务是第n层及其下面各层提供的服务总和。
- 最低层只提供服务,是整个层次结构的基础;中间各层既是下一层的服务使用者,又是上一层的服务提供者;最高层面向用户提供服务。
- 上一层只能通过相邻层间的接口使用下一层的服务,而不能调用其他层的服务;下一层所提供服务的实现细节对上一层透明。(上层数据包含在下层数据里)
- 两台主机通信时,对等层在逻辑上有一条直接信道,表现为不经过下层就把信息传送到对方。
传输单元
- 应用层:报文
- 传输层:报文段
- 网络层:IP数据报,分组(父子关系)
- 链路层:帧
- 物理层:比特流
计算机网络协议、接口、服务的概念
分层结构:
-
实体:第n层中的活动元素称为n层实体,同一层的叫做对等实体。
-
协议:为进行网络中对等实体数据交换为建立的规则,标准或约定。包括语法,语义,同步
- 语法:传输数据的格式,数据如何分割(遵循规则,怎么讲)。
- 语义:规定每一段所要完成的功能(讲什么)
- 同步:各种操作的条件、时序关系,操作顺序。
- 完整协议
- 线路管理:建立释放连接
- 差错控制
- 数据转换
-
接口:同一个结点内相邻两层间交换信息的连接点,上层使用下层服务的入口。通过服务访问点SAP进行交互。
-
服务
-
本层为上一层提供服务,使用下一层服务
-
OSI服务原语

- 请求
- 指示
- 响应
- 证实
-
-
说明

- 协议是水平的(主机和主机之间某个层次通过协议水平传输),服务是垂直的(上层服务使用下层服务)
- 本层用户只能看见服务而看不见协议
-
服务类型
- 面向连接服务和无连接服务
- 面向连接服务:连接建立,数据传输,连接释放.(TCP)
- 无连接服务:报文分组传送到链路上,不可靠服务(IP、UDP)
- 可靠服务和不可靠服务
- 可靠服务:能纠错,检错,应答
- 不可靠服务:用户来纠错
- 有应答服务和无应答服务
- 有应答服务:给出肯定或否定回到
- 无应答服务:不自动回答
- 面向连接服务和无连接服务
ISO/OSI 参考模型和 TCP/IP模型
计算机网络分层结构有两种:
-
7层的OSI参考模型(法定标准)。
-
4层TCP/IP参考模型(事实标准)。
-
总结1,2得到一个五层体系模型。

-
OSI参考模型(口令:物链网输会示用/物联网淑惠试用,下面三层是通信子网(数据通信),上面三层是资源子网(数据处理))
- 物理层:在物理媒介上实现比特流的透明传输,传送单位比特
- 数据链路层
- 任务:将网络层传输来的IP数据报组装成帧
- 定义接口特性,传输模式(单工(单向),半双工(双向但同一时间只能一个人用传输信道),双工),传输速率,比特同步,比特编码。
- 主要协议:Rj45,802.3
- 功能:成帧(定义帧的开始和结束),差错控制,流量控制(发送方发送速度和接收方接收速度之间进行协调),控制对信道的访问。
- 如SDLC,HDLC,PPP,SRP,帧中继
- 任务:将网络层传输来的IP数据报组装成帧
- 网络层:IP层,传输单位数据报
- 任务:把网络层的协议数据单元从源端到目的端,进行通信,点到点
- 关键问题:对分组进行路由选择,实现流量控制,拥塞控制,差错控制,网际互连等功能
- 如IP,IPX,ICMP,IGMP,ARP,RARP,OSPF
- 传输层:传输报文段TCP或者用户数据端UDP
- 实现两个进程通信
- 功能:提供端到端的传输服务,提供可靠/不可靠传输,差错控制,流量控制,复用分用等功能(可差流用 )。(上面四层是端到端,下面三层是点到点)
- 传输单位是报文段或用户数据段。
- 复用:多个应用层进程的数据可用同时使用运输层的服务。分用:运输层把收到的信息分别交给应用层相应的进程。
- 如TCP,UDP
- 会话层:向表现层实体/用户进程提供建立连接并在连接上有序的传输数据。这就是会话,也是建立同步SYN。
- 管理主机间的会话进程,包括建立,管理,终止进程会话。
- 使用校验点可使会话在通信失效的时候从校验点继续回复通信,实现数据的同步。
- 表示层
- 处理两个通信系统交换信息的表示方式,对语法和语义进行处理。数据结构。
- 如数据格式转换,数据加密解密,数据的压缩和恢复。
- 应用层(所有能和用户交互产生网络流量的程序,是否需要联网可用作为判定标准),传输单位报文。
- 用户和网络的界面
- 如FTP(文件传输),SMTP(电子邮件),HTTP(万维网)
-
TCP/IP模型

- 网络接口层
- 同1物理层和2数据链路层
- 网际层(主机-主机)
- 同网络层
- 当前IPv4,下一版本IPv6
- 传输层
- 传输控制协议TCP
- 用户数据报协议UDP
- 应用层
- 网络接口层
-
五层参考模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jnksGEfw-1663595426069)(C:\Users\mio\AppData\Roaming\Typora\typora-user-images\image-20220919205508140.png)]
-
对比

第二章物理层

基本概念
- 物理层考虑的是怎样在连接各种计算机的传输媒体上传输数据比特流。
- 物理层为数据链路层屏蔽了各种传输媒体的差异,是数据链路层只需要考虑如何完成本层协议和服务,不必考虑传播媒介。
数据通信相关术语
通信的目的是传送信息。
-
数据:传送信息的实体,通常是有意义的符号序列。
-
信号:数据的电气/电磁的表现,是数据在传输过程中的存在形式。
- 数字信号:代表消息的参数取值是离散的。
- 模拟信号:代表消息的参数取值是连续的。

-
信源:产生和发送数据的源头。
-
信宿:接收数据的终点。
-
信道:信号的传输媒介。一般用来表示向某一个方向传送信息的介质。
-
传输信号:模拟信道(传送模拟信号)/ 数字信道(传送数字信号)
-
传输介质:无线信道 / 有线信道
三种通信方式
- 单工通信:只有一个方向的通信而没有反方向的交互,仅需要一条信道。
- 半双工通信:通信的双方都可以发送或接收数据,但任何一方都不能同时发送和接收,需要两条信道。
- 全双工通信:通信双方可以同时发送和接收信息,需要两条信道。
两种数据传输方式
- 串行传输:速度慢,费用低,适合远距离
- 并行传输:速度快,费用高,适合近距离(常用于计算机内部数据传输)
*
码元&波特&速率&带宽
-
码元是一个固定时长的信号波形(数字脉冲,信号符号),代表不同离散数值的基本波形,是数字通信的计量单位,这个时长内的信号称为k进制码元,而该时长称为码元宽度。当码元的离散状态有M个时(M大于2),此时码元为M进制码元。
1码元可以携带多个比特的信息量。例如,在使用二进制编码时,只有两种不同的码元,一种代表0状态,另一种代表1状态。
例子:4进制码元 -> 码元的离散状态有4个 -> 4种高低不同的信号波形 -> 00、01、10、11(4进制码元用两个比特) -
速率也叫数据率,是指数据的传输速率,表示单位时间内传输的数据量。可以用码元传输速率和信息传输速率表示。
-
先声明,传输是刚上机,传播是信道传送。
-
码元传输速率(1s可以传输多少个码元):别名码元速率、调制速率、符号速率等,它表示单位时间内数字通信系统所传输的码元个数(也可称为脉冲个数或信号变化的次数),单位是波特(1Baud = 1码元/s)。1波特表示数字通信系统每秒传输一个码元。码元可以是多进制的。码元速率与进制数无关。(波特)
Rb=RB×log2N(RB传码率,Rb传信率,N是码元数)Rb=RB×log_{2}N(RB传码率,Rb传信率,N是码元数)Rb=RB×log2N(RB传码率,Rb传信率,N是码元数)
- 信息传输速率(传信率)(1秒传输多少个比特):别名信息速率、比特率等,表示单位时间内数字通信系统传输的二进制码元个数(即比特数),单位是比特/秒(b/s) 。系统传输的是比特率,所以通常传输速率比较的是信息传输速率。
关系:若一个码元携带n bit的信息量,则M Baud的码元传输速率所对应的信息传输速率为M x n bit/s。
带宽:表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”,常用来表示网络的通信线路所能传输数据的能力。单位是b/s。带宽又叫频宽,是指在固定的的时间可传输的资料数量。带宽是指网络可通过的最高数据率,即每秒多少比特b/s。频宽也可以以每秒钟的周期性变动重复次数的计量单位赫兹(Hz)来表示。所以HZ和b/s,都可以表示带宽。
信号失真
影响失真程度的因素:
- 码元传输速率
- 信号传输距离
- 噪声干扰
- 传输媒体质量
信道带宽的信道能通过的最高频率和最低频率之差。
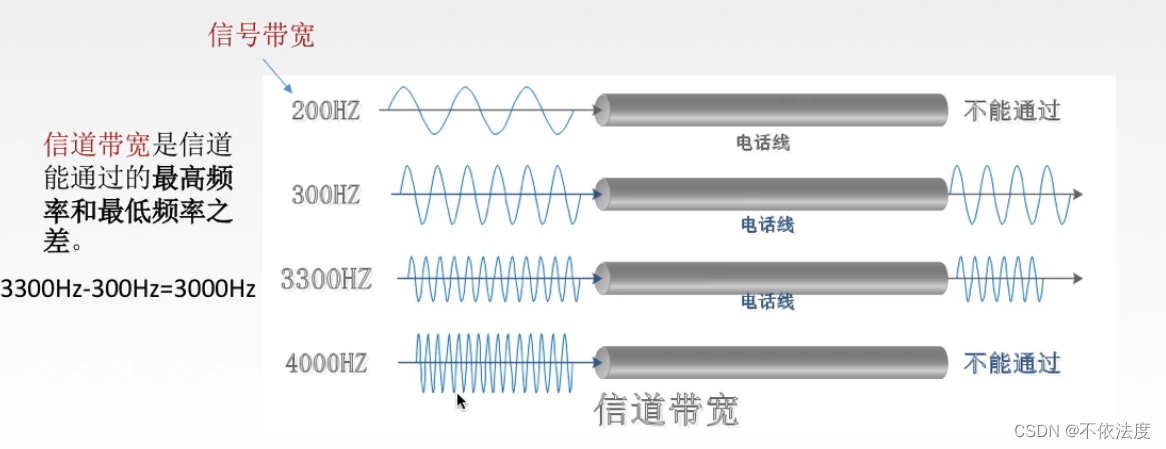
码间串扰:接收端收到的信号波形失去了码元之间清晰界限的现象,所以4000Hz不能通过。
奈氏准则
在理想低通(无噪声,带宽受限)条件下,为了避免码间串扰,极限码元传输速率为 2W Baud,W 是信道带宽,单位是 Hz。(只有在这奈氏准则和香农定理中带宽才用Hz,一般都是用b/s)

- 在任何信道中,码元传输的速率是有上限的。若传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的完全正确识别成为不可能。
- 信道的频带越宽(即能通过的信号高频分量越多),就可以用更高的速率进行码元的有效传输。
- 奈氏准则给出了码元传输速率的限制,但并没有对信息传输速率给出限制。
- 由于码元的传输速率受奈氏准则的制约,所以要提高数据的传输速率,就必须设法使每个码元能携带更多比特的信息量,这就需要采用多元制的调制方法
香农定理
在奈氏准则的基础上解决有噪声的传输输入速率的上限问题。噪声的影响主要看信噪比,常记为S/N。
信噪比=信号的平均功率噪声的平均功率信噪比=\cfrac{信号的平均功率}{噪声的平均功率} 信噪比=噪声的平均功率信号的平均功率
如果题目给出信噪比没有给单位就当作S/N直接用,如果给的单位是分贝dB,先算出S/N。
信噪比(dB)=10log10(S/N)信噪比(dB)=10log_{10}(S/N) 信噪比(dB)=10log10(S/N)
香农定理:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。

- 信道的带宽或信道的信噪比越大,则信息的极限传输速率就越高。
- 对一定的传输带宽和一定的信噪比,信息传输速率的上限就确定了。
- 只要信息的传输速率低于信道的极限传输速率,就一定能够找到某种方法来是实现无差错的传输。
- 香农定理得出的为极限信息传输速率,实际信道能达到的传输速率要比它低不少。
- 从香农定理可以看出,若信道带宽 W 或信噪比 S/N 没有上限(不可能),那么信道的极限信息传输速率也就没有上限。
区别
如果题目既可以用奈氏准则也可以用香农定理,计算结果值取小的作为极限传输速率。

编码&调制
基带信号&宽带信号
信道:信号的传输媒介。一般用来表示向某一个方向传送信息的介质,因此一条通信线路往往包含一条发送信道和一条接收信道。
- 传输信号:模拟信道(传送模拟信号-连续不断的)/ 数字信道(传送数字信号0101)
- 传输介质:无线信道 / 有线信道
分类:
- 基带信号:将数字信号1和0直接用两种不同的电压表示,再送到数字信道上去传输(基带传输)。来自信源的信号,如计算机输出的代表各种文字或图像文件的数据信号都属于基带信号。基带信号就是发出的直接表达了要传输的信息的信号。比如声波!
- 宽带信号:将基带信号进行调制后形成的频分复用模拟信号,再传送到模拟信道上去传输(宽带传输)。把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输。(比如广播电台广播员说话声音小,就会调高频率再传输,这样传输过程带来的损耗不影响最后信号的解析)
区分一下几个信号:
- 数字信号:离散信号,一般就是二进制数字信号。
- 模拟信号:连续函数,类似正余弦波。
- 基带信号:不经调制的数字信号直接传输(基带信号无法在普通介质上进行远距离传输,所以会对基带信号进行调制,减小带宽)
- 宽带信号:基带信号经过调制后的模拟信号。
应用:
- 在传输距离较近时,计算机网络采用基带传输方式,一般发生在计算机内部(近距离衰减小,从而信号内容不易发生变化)。
- 在传输距离较远时,计算机网络采用宽带传输方式(远距离衰减小,即使信号变化大也能最后过滤出来基带信号)。
编码和调制
- 编码:数据转成数字信号
- 调制:数据转成模拟信号
数字数据 —— 数字信号:数字发送器(编码)
数字数据 —— 模拟信号:调制器(调制)
模拟数据 —— 数字信号:PCM编码器(编码),如音频数字化。
模拟数据 —— 模拟信号:放大器调制器(调制),如电话。


四种编码调制方法
数字数据编码为数字信号
- 非归零编码【NRZ not return zero】
- 高1低0。编码容易实现,但没有检错功能,且无法判断一个码元的开始和结束(需要告知周期),以至于收发双方难以保持同步。例如全0或全1,是一条水平线 。
- 曼彻斯特编码
- 将一个码元分成两个相等的间隔,前一个间隔为低电平后一个间隔为高电平表示码元1;码元0则正好相反。也可以采用相反的规定。通过电平的高低转换来表示“0”或“1”,每一位的中间有一个跳变的动作,这个动作既作时钟信号,又作数据信号,但因为每一个码元都被调成两个电平,所以数据传输速率(b/s)只有调制速率(单位时间内的变化,码元速率)的1/2,所占的频带宽度是原始的基带宽度的两倍。(一个时钟周期内,一个比特,两个码元)
- 差分曼彻斯特编码
- 同1异0。常用于局域网传输,其规则是:若码元为1,则前半个码元的电平与上一个码元的后半个码元的电平相同,若为0,则相反。该编码的特点是,在每个码元的中间,都有一次电平的跳转,可以实现自同步,且抗干扰性强于曼彻斯特编码。
- 归零编码【RZ】
- 信号电平在一个码元之内都要恢复到零,比如前半段是1后半段是0,前半段是0后半段还是0,低电平频率过高,占用信道。
- 反向不归零编码【NRZI】
- 下一个信号为0表示电平需要反转,下一个信号为0电平保持不变。
- 4B/5B编码
- 比特流中插入额外的比特以打破一连串的0或1,就是用5个比特来编码4个比特的数据,之后再传给接收方,因此称为4B/5B。** **。

- 比特流中插入额外的比特以打破一连串的0或1,就是用5个比特来编码4个比特的数据,之后再传给接收方,因此称为4B/5B。** **。
数字数据调制为模拟信号
数字数据调制技术在发送端将数字信号转换为模拟信号,而在接收端将模拟信号还原为数字信号,分别对应于调制解调器的调制和解调过程。

调相(QAM)正交调幅调制
模拟数据编码为数字信号
计算机内部处理的是二进制数据,处理的都是数字音频,所以需要将模拟音频通过采样、量化转换成有限个数字表示的离散序列(即实现音频数字化)。
最典型的例子就是对音频信号进行编码的脉码调制(PCM),在计算机应用中,能够达到最高保真水平的就是PCM编码,被广泛用于素材保存及音乐欣赏,CD、DVD以及我们常见的WAV文件中均有应用,它主要包括三步:抽样、量化、编码
- 抽样:(按照周期离散取点)对模拟信号周期性扫描,把时间上连续的信号变成时间上离散的信号。为了使所得的离散信号能无失真地代表被抽样地模拟数据,要使用采样定期进行采样。f采样频率 ≥ 2f信号【最高】频率,。
量化:(按照分级标准将采样值取整)把抽样取得的电平幅值按照一定的分级标度转化为对应的数字值,并取整数,这就把连续的电平幅值转换为离散的数字量。
编码:把量化的结果转换为与之对应的二进制编码。
模拟数据调制为模拟信号
为了实现传输的有效性,可能需要较好的频率。这种调制方式还可以使用频分复用技术,充分利用带宽资源。在电话机和本地交换机所传输的信号是采用模拟信号传输模拟数据的方式;模拟的声音数据是加载到模拟的载波信号中传播的。
传输介质
传输介质也称传输媒体/传输媒介,它就是数据传输系统中在发送设备和接收设备之间的物理通路。
传输介质并不是物理层。传输媒体在物理层的下面,因为物理层是体系结构的第一层,因此有时称传输媒体为0层。在传输介质中传输的是信号,但传输介质并不知道所传输的信号代表什么意思。但物理层规定了电气特性,因此能够识别所传送的比特流。(传输介质只管传输不管是什么信号,物理层要能够识别传输的信号)
传输介质分类:
- 导向性传输介质:电磁波被导向沿着固体媒介(铜线/光纤)传播。如 双绞线、同轴电缆、光纤
- 非导向性传输介质:自由空间,介质可以是空气、真空、海水等。如 无线电波、微波、红外线和激光
导向性传输介质
举例:
-
双绞线
双绞线是古老、又最常用的传输介质,它由两根采用一定规则并排绞合的、相互绝缘的铜导线组成。绞合可以减少对相邻导线的电磁干扰。为了进一步提高抗电磁干扰能力,可在双绞线的外面加上一个由金属丝编织成的屏蔽层,这就是屏蔽双绞线(STP),无屏蔽层的双绞线就称为非屏蔽双绞线(UTP)。

双绞线价格便宜,是最常用的传输介质之一,在局域网与传统电话网中普遍使用。模拟传输和数字传输都可以使用双绞线,其通信距离一般为几公里到数十公里。距离太远时,对于模拟传输,要用放大器放大衰减的信号;对于数字传输,要用中继器将失真的信号整形。 -
同轴电缆
同轴电缆由导体铜质芯线、绝缘层、网状编制屏蔽层和塑料外层构成。按特性抗阻数值的不同,通常将同轴电缆分为两类:50 Ω 同轴电缆和 75 Ω 同轴电缆。其中 50 Ω 同轴电缆主要用于传送基带数字信号,又称为基带同轴电缆,它在局域网中得到广泛应用;75 Ω 同轴电缆主要用于传送宽带信号,又称为宽带同轴电缆,它主要用于有线电视系统。- 同轴电缆VS双绞线
由于外导体屏蔽层的作用,同轴电缆抗干扰特性比双绞线好,被广泛用于传输较高速率的数据,其传输距离更远,但价格较双绞线贵。
- 同轴电缆VS双绞线
-
光纤
光纤通信就是利用光导纤维传递光脉冲来进行通信。有光脉冲表示1,无光脉冲表示0。而可见光的频率大约是 10^8MHz,因此光纤通信系统的带宽远远大于目前其他各种传输介质的带宽。光纤在发送端有光源,可以采用发光二极管或半导体激光器,它们在电脉冲作用下能产生出光脉冲;在接收端用光电二极管做成光检测器,在检测到光脉冲时可还原出电脉冲。光纤主要由纤芯(实心的! )和包层构成,光波通过纤芯进行传导,包层较纤芯有较低的折射率。当光线从高折射率的介质射向低折射率的介质时,其折射角将大于入射角。因此,如果入射角足够大,就会出现全反射,即光线碰到包层时候就会折射回纤芯、这个过程不断重复,光也就沿着光纤传输下去。- 特点:
传输损耗小,中继距离长,对远距离传输特别经济。
抗雷电和电磁干扰性能好。
无串音干扰,保密性好,也不易被窃听或截取数据。
体积小,重量轻。

- 特点:

非导向性传输介质

物理层设备
中继器
诞生原因:由于存在损耗,在线路上传输的信号功率会逐渐衰减,衰减到一定程度时将造成信号失真,因此会导致接收错误。
中继器的功能:对信号进行再生和还原,对衰减的信号进行放大,保持与原数据相同,以增加信号传输的距离,延长网络的长度。
中继器:再生数字信号
放大器:再生模拟信号
中继器的两端:两端的网络部分是网段,而不是子网,适用于完全相同的两类网络的互连,且两个网络速率要相同。
中继器只将任何电缆段上的数据发送到另一段电缆上,它仅作用于信号的电气部分,并不管数据中是否有错误或不适于网段的数据。
两端可连相同媒体,也可连不同媒体。
中继器两端的网段一定要是同一个协议。(中继器不会存储转发)
5-4-3规则: 网络标准中都对信号的延迟范围作了具体的规定,因而中继器只能在规定的范围内进行,否则会网络故障。
5个网段,4个中继器,3个计算机

集线器
又称为多口中继器
集线器的功能:对信号进行再生放大转发,对衰减的信号进行放大,接着转发到其他所有(除输入端口外)处于工作状态的端口上,以增加信号传输的距离,延长网络的长度。不具备信号的定向传送能力,是一个共享式设备。
星型拓扑结构
集线器不能分割冲突域。
第三章

基本概念
结点:主机、路由器
链路:网络中两个结点之间的物理通道,链路的传输介质主要有双绞线、光纤和微波。分为有线链路、无线链路。
数据链路:网络中两个结点之间的逻辑通道,把实现控制数据传输协议的硬件和软件加到链路上就构成数据链路。
帧:链路层的协议数据单元,封装网络层数据报。
数据链路层负责通过一条链路从一个结点向另一个物理链路直接相连的相邻结点传送数据报。
(把网络层交付给它的数据报安全、无差错地传给相邻结点)
数据链路层的功能概述
数据链路层在物理层提供服务的基础上向网络层提供服务,其最基本的服务是将源自网络层的数据可靠地传输到相邻结点的目标网络层。其主要作用是加强物理层传输原始比特流的功能,将物理层提供的可能出错的物理连接改造成为逻辑上无差错的数据链路,使之对网络层标表现为一条无差错的链路。
- 功能一:为网络层提供服务。无确认无连接服务,有确认无连接服务,有确认面向连接服务。
- 功能二:链路管理,即连接的建立、维持、释放(用于面对连接的服务)。
- 功能三:组帧。
- 功能四:流量控制(限制发送方)。
- 功能五:差错控制(帧错/位错)。
封装成帧&透明传输
封装成帧
封装成帧就是在一段数据的前后部分添加首部和尾部,这样就构成了一个帧。接收端在收到物理层上交的比特流后,就能根据首部和尾部的标记,从收到的比特流中识别帧的开始和结束。
首部和尾部包含许多的控制信息,她们的一个重要作用:帧定界(确定帧的界限)
帧同步:接收方应当能从接收到的二进制比特流中区分出帧的起始和终止。

透明传输
透明传输是指不管所传数据是什么样的比特组合,都应当能够在链路上传送。因此,链路层就“看不见”有什么妨碍数据传输的东西。
当所传数据中的比特组合恰巧与某一个控制信息完全一样时, 就必须采取适当的措施,使收方不会将这样的数据误认为是某种控制信息。这样才能保证数据链路层的传输是透明的。
组帧
组帧的四种方式:
- 字符计数法
- 字符(节)填充法
- 零比特填充法
- 违规编码法
字符计数法
- 帧首部使用一个计数字段(第一个字节,八位)来标明帧内字符数。目的结点的数据链路层收到字节计数值时,就知道后面跟随的字节数,从而确定帧结束位置。
- 问题:如果计数字段出错,即失去了帧边界划分的依据。

字符填充法
-
用特定字符来定界一帧的开始与结束。
-
控制字符SOH(Start of header)放在帧的最前面,表示帧的首部开始,控制字符EOT(End of transmission)表示帧的结束。为了使信息位中出现的特殊字符不被误判为帧的首尾定界符,可在特殊字符前面填充一个转义字符(ESC)来加以区分,以实现数据的透明传输。
-
当传送的帧是由文本文件组成时(文本文件的字符都是从键盘上输入的,都是ASCII码)。不管从键盘上输入什么字符都可以放在帧里传过去,即透明传输。
-
当传送的帧是由非ASCII码的文本文件组成时(二进制代码的程序或图像等)。就要采用字符填充方法实现透明传输。

零比特填充法
- 零比特填充法使用一个特定的比特模式,即01111110来标志一帧的开始和结束。
- 为了不使信息位出现的比特流01111110被误判为帧的首尾标志,发送方的数据链路层在信息位中遇到5个连续的”1“时,将自动在其后插入一个”0“(不管后面是不是0);
- 而接收方做该过程的逆操作,即每收到5个连续的”1“时,自动删除后面紧跟的”0“,以恢复原信息。

违规编码法 - 在物理层进行比特编码时,通常采用违规编码法。
- 曼彻斯特编码将数据比特”1“编码成”高-低“电平对,将数据比特”0“编码成”低-高“电平对,而”高-高“电平对和”低-低“电平对在数据比特中是违规的。可以借用这些违规编码序列来定界帧的起始和终止。
总结
- 由于字节计数法中Count字段的脆弱性(其值若有差错将导致灾难性后果)及字符填充实现上的复杂性和不兼容性,目前普遍使用的帧同步法是比特填充和违规编码法。
差错控制
差错由来
传输中的差错都是噪声引起的。
- 全局性:由于线路本身电气特性所产生的随机噪声(热噪声),是信道固有的,随机存在的。
- 解决方法:提高信噪比来减少或避免干扰。(通过传感器)
- 局部性:外界特定的短暂原因所造成的冲击噪声,是产生差错的主要原因。
- 解决方法:通常利用编码技术来解决。
差错
- 位错:比特位出错,1变成0,0变成1
- 帧错:丢失、重复、失序
为什么要在数据链路层进行差错控制?
- 因为错误可以尽早发现,不会让一个错误的数据报发送了很长时间到达目的地之后才被发现,从而导致网络资源的浪费。(比如一个数据从出发点到目的地要经过十几个路由器,数据在到达第一个路由器的数据链路层时会被检验出错而被丢弃,就不用再经过后面十几个路由器的传输的)
差错控制(比特错,帧错传输层讲解)
- 检错编码
- 奇偶校验码
- 循环冗余码CRC
- 纠错编码
- 海明码
编码VS编码
- 数据链路层编码和物理层的数据编码与调制不同。物理层编码针对的是单个比特,解决传输过程中比特的同步等问题,如曼彻斯特编码。而数据链路层的编码针对的是一组比特,它通过冗余码的技术实现一组二进制比特串在传输过程判断是否出现了差错。
什么是冗余编码
- 在数据发送之前,先按某种关系附加上一定的冗余位,构成一个符合某一规则的码字后再发送当要发送的有效数据变化时,相应的冗余位也随之变化,使码字遵从不变的规则。接收端根据收到码字是否仍符合原规则,从而判断是否出错。
检错编码
- 奇偶校验码
- 奇偶校验码是奇校验码和偶校验码的统称,是一种最基本的校验码。它由n-1位信息元和1位校验码组成。
- 如果是奇校验码,那么在附加一个校验元后,码长位n的码字中”1“的个数为奇数。
如果是偶校验码,那么在附加一个校验元后,码长位n的码字中”1“的个数为偶数。 - 奇偶校验码的检错能力只有百分之五十,比如奇检验码只能检测奇数位出错的情况,但并不知道哪些位出错,也不能检验偶数位出错的情况。
- 如下题:奇校验,添加一个校验位后为11100101,出现错误只能出现奇数个不一样的,因此出错后还是奇数个1则无法检测(偶数个位出错),答案是D!

- CRC循环冗余码
- 接收端检错过程,把收到的每一个帧都除以同样的除数,然后检查得到的余数R。如果余数为0,这个帧就没有差错,接受。如果余数为不为0,判定这个帧有差错(无法确定到位),丢弃。
- FCS帧检验序列(冗余码)的生成以及接收端CRC检验都是由硬件实现,处理很迅速,因此不会延误数据的传输。
- 在数据链路层仅仅使用循环冗余检验CRC差错检测技术,只能做到对帧的无差错接收,即“凡是接收端数据链路层接受的帧,我们都能以非常接近于1的概率认为这些帧在传输过程中没有产生差错“。
接收端丢弃的帧虽然曾收到了,但是最终还是因为有差错被丢弃,“凡是接收端数据链路层接收的帧均无差错”。
链路层使用CRC检验,能够实现无比特差错的传输,但这还不是可靠(不出错)传输。(可靠传输:数据链路层发送端发送什么,接收端就收到什么。)
- 发送端最终发送的数据 = 要发送的数据 + 帧检验序列FCS,FCS就是冗余码,根据多项式的阶对要发送的数据加0后与多项式相除(相同为0,不同为1),余数就是冗余码。比如下面这题:要发送的数据是1101 0110 11,多项式10011是四阶,所以在要发送的数据后面加4个0,即1101 0110 1100 00,对1101 0110 1100 00除多项式10011得到的余数1110就是FCS。
生成多项式的最高次幂即为循环冗余码的位数,下面这道题冗余码是四位。

纠错编码
海明码:发现双比特错,纠正单比特错。
检验步骤:
-
确定校验码位数 r:根据海明不等式
2r≥k+r+12^r≥k+r+12r≥k+r+1-
r 为冗余信息位
-
k 为信息位
-
把1移到左边可能会更好理解海明不等式。 2r - 1 ≥ k + r 。r个冗余信息位的组合有 2r 种,选择 2r 中其中一种用于表示数据的正确性,其余的 2r - 1 种用于表示编码中哪一位产生错误。总共有 k + r 位,错误的定位要把这 k + r 位都涵盖,所以是错误位的可能大于等于错误位。(全0的话就是没有错误,不用定位)
-
以数据码 101101为例:数据的位数 k = 6,满足不等式的最小 r 为 4。也就是 D = 101101 的海明码应该有 6 + 4 = 10 位,其中原数据 6 位,校验码 4 位。
-
-
确定校验码和数据的位置
假设这 4 位校验码分别为 P1,P2,P3,P4,依次放在2的几次方的;数据从左到右为 D1,D2,……,D6(按序把空填满)。

-
求出校验位的值/海明码
将校验码和所以他能检验的位进行异或计算,是的最终结果为0。
P1 ⊕ D1(1) ⊕ D2(0) ⊕ D4(1) ⊕ D5(0) = 0 → P1 = 0
1 ⊕ 0 = 1,1 ⊕ 1 = 0,0 ⊕ 0 = 0,所以要想P1 ⊕ 0为0,P1得为0.
P2 ⊕ D1 ⊕ D3 ⊕ D4 ⊕ D6 = 0 → P2 = 0
P3 ⊕ D2 ⊕ D3 ⊕ D4 = 0 → P3 = 0
P4 ⊕ D5 ⊕ D6 = 0 → P4 = 1
故101101的海明码为 0010011101

-
检错并纠错
假设第五位出错,因此接收到的数据位是 0010111101。令每一位校验码和所有能被该校验码检验的数据位的数据值进行位异或运算。
P1 ⊕ D1 ⊕ D2 ⊕ D4 ⊕ D5 = 1
P2 ⊕ D1 ⊕ D3 ⊕ D4 ⊕ D6 = 0
P3 ⊕ D2 ⊕ D3 ⊕ D4 = 1
P4 ⊕ D5 ⊕ D6 = 0
从P4往P1写,二进制序列位0101,恰好对应十进制5,这样就找到了出错的位置,即出错位是第5位。 -
关于怎么通过海明码定的位我简单说一下我的理解:P1对应的0001,参与检验数据位最后一位是1的数据,比如3:0011,5:0101,7:0111,9:1001,P1和数据位为3,5,7,9的D1,D2,D4,D5进行异或运算结果为1也就是说出错数据的数据位最后一位为1;P2的数据位0010,参与检验数据位倒数第二位为1的,也就是数据位为0110,0110,0111,1011的数据,即D1,D3,D4,D6,检验结果无误,也就是说出错数据的数据位倒数第二位不为1,为0;同理让P3,P4参与检验。最后得出出错数据的数据位最后一位和倒数第三位为1,也就是0101,就是第五位数据。
流量控制
介绍:
- 流量控制:控制发送速率,使接收方有足够的缓冲空间来接收每一个帧。
- 作用:较高的发送速度和较低的接收能力的不匹配,会造成传输出错,因此需要流量控制。
区分数据链路层和传输层的流量控制手段:
- 数据链路层的流量控制是点对点的(相邻两个结点),而传输层的流量控制是端到端的(发送和接收双方的服务器)。
- 数据链路层流量控制手段:接收方收不下就不回复确认。
- 传输层流量控制手段:接收方给发送方一个窗口公告。
流量控制的方法:
- 停止等待协议:发送窗口大小 = 1,接收窗口大小 = 1
- 滑动窗口协议
- 后退 N 帧协议(GBN):发送窗口大小 > 1,接收窗口大小 = 1
- 选择重传协议(SR):发送窗口大小 > 1,接收窗口大小 > 1
- 滑动窗口解决
- 流量控制(收不下就不给确认,想发也发不了)
- 可靠传输(发送方自动重传)
可靠传输:发送端发啥,接收端收啥。
停止等待协议
为什么要有停等协议?
- 因为在链路上出了比特出差错外,底层的信道还会出现丢包问题。
- 丢包:物理线路故障,设备故障,病毒攻击,路由信息错误等原因,会导致数据包的丢失。
- 这里的数据包就是一个数据,在不同层次有不同的名字;在链路层是帧,在网络层是数据报/分组,在传输层是报文段。
“停止-等待”就是每发送完一个分组就停止发送,等待对方确认,在收到确认后再发送下一个分组。
无差错接收与可靠传输的区别
-
无差错接收是指凡是接收的帧(不包括丢弃的帧),我们都能以非常接近于1的概率认为这些帧在传输过程中没有产生差错。也就是说:凡是接收端数据链路层接受的帧都没有传输差错(有差错的帧就丢弃而不接受)。
-
要做到可靠传输(即发送什么就收到什么)就必须加上确认和重传机制。
详解停等协议
每发送完一个帧就停止发送,等待对方的确认,在收到确认后再发送下一个帧。每次只允许发送一帧,然后就陷入等待接收方确认信息的过程中,因而传输效率很低。(一个发送周期大部分时间都在传播路上,发送时间占比很小)
应用情况:
-
无差错情况

-
有差错
-
数据帧丢失或检测到帧出错(传过去没成功)
- 解决办法:发送帧的同时保留帧的副本,设立定时器,一旦超过时间限制还没收到确认帧,发送方就将副本重新发送,接收方接收后返回确认帧(丢失)。(数据帧和确认帧需要编号)如果是帧出错就把接收到的帧丢弃,等待发送方重新发送。

- 解决办法:发送帧的同时保留帧的副本,设立定时器,一旦超过时间限制还没收到确认帧,发送方就将副本重新发送,接收方接收后返回确认帧(丢失)。(数据帧和确认帧需要编号)如果是帧出错就把接收到的帧丢弃,等待发送方重新发送。
-
ACK(确认帧)丢失(返回确认没成功)
- 解决办法:设立定时器, 一旦超时,发送方重新发送副本,接收方接收到新的帧因为和之前发送的重复,把第二次发送来的重复的帧丢弃,然后像发送方返回确认。

- 解决办法:设立定时器, 一旦超时,发送方重新发送副本,接收方接收到新的帧因为和之前发送的重复,把第二次发送来的重复的帧丢弃,然后像发送方返回确认。
-
ACK迟到(返回确认,但是迟到超过时间限定)
- 解决办法:也是计时器,超过实现没收到确认,发送方重新发送,然后出现了重复帧,丢掉重复帧。(注意,这里确认帧是迟到,不是丢失,也就是说最终这个确认帧会返回给发送方的)发送方在进行下一个帧的发送是时候收到了之前迟到的确认帧,发送方不对迟到的确认帧处理,直接丢掉。

- 解决办法:也是计时器,超过实现没收到确认,发送方重新发送,然后出现了重复帧,丢掉重复帧。(注意,这里确认帧是迟到,不是丢失,也就是说最终这个确认帧会返回给发送方的)发送方在进行下一个帧的发送是时候收到了之前迟到的确认帧,发送方不对迟到的确认帧处理,直接丢掉。
-
性能分析
- T0是发送方发送第一个比特到最后一个比特所用时间,也就是发送时延。TA同理。RTT是传播时延。

- 信道利用率:发送时延占整个发送周期的比率。(下面这道题没说确认帧的发送时延,记为0)

停止等待协议弊端
- 停等协议发送方每发送一个帧就处于等待状态,等到接收方回复一个确认帧,发送方才会发送新的帧。因此大部分时间都是在等待,真正发送数据的时间很少,极大地浪费了资源。
- 为了解决这个问题,可以采用流水线技术,一次发送多个帧,但同时在其他方面需要改进:
- 必须增加序号范围;
- 发送方需要缓存多个分组,为帧丢失重传备用。
针对这种解决方案,就推出了GBN和SR。
GBN后退N帧协议
- 发送窗口:发送方维持一组连续的允许发送的帧的序号。
- 接收窗口:接收方维持一组连续的允许接收帧的序号。
发送方必须响应的三件事
-
上层的调用
- 上层要发送数据时,发送方先检查发送窗口是否已满,如果未满,则产生一个帧并将其发送;如果窗口已满,发送方只需将数据返回给上层,暗示上层窗口已满。上层等一会再发送。(实际实现中发送方可以缓存这些数据,窗口不满的时候再发送帧)
-
收到了一个ACK
- GBN协议中,对n号帧的确认采用累积确认的方式,ACK n 标明接收方已经收到n号帧和它之前的全部帧。
-
超时事件
- 如果出现超时,发送方重传所有已发送但未被确认的帧(最近接收的确认帧为n,也就是发送n后的所有帧)。
接收方要做的事
- 如果正确收到n号帧,并且按序,那么接收方为n帧发送一个ACK n,表示对n帧确认接收,并将该帧中的数据部分交付给上层。
- 如果接收到的帧并非按序,也就不是本应该下一个接收的帧,就全部丢弃,并为最近按序接收的帧重新发送ACK。接收方无需缓存任何失序帧,只需要维护一个信息:expectedseqnum(下一个按序接收的帧序号)。
运行中的GBN

滑动窗口长度限制
- 若采用n个比特对帧编号,那么发送窗口的尺寸Wt应满足:
1≤Wt≤2n−11≤W_t≤2^n-11≤Wt≤2n−1 - 因为发送窗口尺寸过大,就会使得接收方无法区分新帧和旧帧。
- 举个例子,当n为2,也就是用2个比特对帧编号,帧编号为0,1,2,3。那么发送窗口最大为3,如果发送窗口是4,那么窗口内可以同时放置帧标号为0,1,2,3的帧数据,假设这四个帧都送达(** **)但是返回的确认帧都丢失。没有收到确认帧超时后发送方就会把已经发送的旧的0,1,2,3帧重新发一遍,接收方没办法判断重新发来的0,1,2,3帧是重复的,会以为的新一组帧。
GBN协议重点总结
- 累积确认(偶尔捎带确认,比如发送2帧的确认帧捎带1帧的确认帧,怎么判断内,如果接收方已经接收到n帧的确认帧,那么n即n前面的帧是都被接收的)
- 接收方只按顺序接收帧,不按序的帧无情丢弃
- 确认序列号最大的、按序到达的帧
- 发送窗口最大为2n - 1(n是用于编码的比特数),接收窗口大小为 1
GBN协议性能分析
- 因连续发送数据帧而提高了信道利用率
- 在重传时必须把原来已经正确传送的数据帧重传,是传送效率降低。
- 比等停协议好但是不如SR
SR协议
发送方必须响应的三件事
-
上层的调用
- 从上层收到数据后,SR发送方检查下一个可用于该帧的序号,如果序号位于发送窗口内,则发送数据帧;否则就像GBN一样,要么将数据缓存,要么返回给上层之后再传输。
-
收到了一个ACK(接收方返回的确认帧)
- 如果收到ACK,假如该帧序号在窗口内,则SR发送方将那个被确认的帧标记为已接收。如果该帧序号是窗口的下界(最左边第一个窗口对应的序号),则窗口向前移动到具有最小序号的未确认帧处。如果窗口移动了并且有序号在窗口内的未发送帧,则发送这些帧。
-
超时事件
- 每个帧都有自己的定时器,一个超时事件发生后只重传一个帧。
SR接收方要做的事
-
对于接收窗口内序号的帧来者不拒
- SR接收方将确认一个正确接收的帧而不管其是否按序。失序的帧将被缓存,并返回给发送方一个该帧的确认帧,直到所有帧(即序号更小的帧)皆被收到为止,这时才可以将一批帧按序交付给上层,然后向前移动滑动窗口。
-
如果收到了窗口序号外(小于窗口下界(指的是当前滑动窗口相邻的上一个滑动窗口))的帧(说明上一次返回的ACK丢失了),就返回一个ACK。
-
其他情况,就忽略该帧。
运行中的SR

滑动窗口长度
-
发送窗口最好等于接收窗口。(大了会溢出,小了没意义)
-
窗口大小范围[1,2(n-1) ]
WTmax=WRmax=2(n−1)W_{Tmax}=W_{Rmax}=2^{(n-1)}WTmax=WRmax=2(n−1)-
n是编码的比特位
-
简单解释就是让接收窗口再移动一轮也不会出现这一轮编号内的数,举个例子:假设n是2,那么编号就0,1,2,3,第一轮接收窗口接收0,1,第二轮窗口接收2,3,如果窗口大于21,比如3,那么第一轮窗口接收的是0,1,2,第二轮窗口接收的是3,0,1,如果第一轮的0,1,2都接收但都丢失了,移动窗口到第二轮了,但是第一轮的0,1,2接收确认帧超时后会重新发送0,1,2。这里的0是旧的,上一轮的0,和新一轮窗口的0就会冲突。
-
直接考虑最坏的情况,发送窗口只有接收到确认帧才会移动,接收窗口收到帧就会移动,最坏的情况就是发送窗口在第一轮发送窗口,接收窗口在第二轮窗口。不等式式子:
n+n≤2nn+n≤2^{n}n+n≤2n -
大于2(n-1)时,会产生无法区分新旧帧的问题!

-
SR协议重点总结
- 对数据帧逐一确认,收一个确认一个
- 只重传出错帧
- 接收方有缓存
- 滑动窗口长度
介质访问控制
大纲

传输数据两种链路
- 点对点链路:两个相邻节点通过一个链路相连,没有第三者。
- 应用:PPP协议,常用于广域网。
- 广播式链路:所有主机共享通信介质。
- 应用:早期的总线以太网、无线局域网,常用于局域网。
- 典型拓扑结构:总线型、星型(逻辑总线型)
介质访问控制
- 采取一定的措施,使得两对节点之间的通信不会发生互相干扰的情况。
介质访问控制划分
-
静态划分信道:信道划分介质访问控制
- 频分多路复用FDM(frequency)
- 时分多路复用TDM(time)
- 波分多路复用WDF(wave)
- 码分多路复用CDF(code)
-
动态分配信道
- 轮询访问介质访问控制:令牌传递协议
- 随机访问介质访问控制
- ALOHA协议
- CSMA协议
- CSMA/CD协议
- CSMA/CA协议
先介绍一下几种介质访问控制(各协议详细后面会有说明)
信道划分介质访问控制(MAC Multiple Access Control )协议,基于多路复用技术划分资源。
- 网络负载重:共享信道效率高,且公平(很多人使用网络,网络负载重,对信道按照时间或者空间,频率进行划分可以充分利用信道)
- 网络负载轻:共享信道效率低(很少人使用,网络负载轻,对信道进行划分会有大量资源处于空闲状态被浪费)
随机访问MAC协议:唯一会产生冲突
用户根据意愿随机发送信息,发送信息时可独占信道带宽。
- 网络负载重:产生冲突开销(很多人在发送信息很容易冲突,冲突就导致发送的信息全部失效,需要重新发送)
- 网络负载轻:共享信道效率高,单个结点可利用信道全部带宽(不容易冲突,发送的信息不容易要重发)
轮询访问MAC协议/轮流协议/轮转访问MAC协议
既不产生冲突,又要发送时占全部带宽。
补充一下:这三种介质访问控制方式只有随机访问MAC协议会发生冲突!
信道划分介质访问控制
- 将使用介质的每个设备与来自同一信道上的其他设备的通信隔离开,把时域和频域合理地分配给网络上的设备。
- 信道划分的实质就是通过分时、分频、分码等方法把原来的一条广播信道,逻辑上分为几条用于两个结点之间通信的互不干扰的子信道,实际上就是把广播信道转变为点对点信道。
多路复用技术
- 将多个信号组合在一条物理信道上进行传输,使得多个计算机或终端设备共享信道资源,提高信道利用率。
- 采用多路复用技术可以把多个输入通道的信息整合到一个复用通道中,在接收端把收到的信息分离出来并传送到对应的输出通道。

静态划分信道四方法
频分多路复用FDM
用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。频分复用的所有用户在同样的时间占用不同带宽(频率带宽) 资源。

时分多路复用TDM(静态)
将时间划分为一段段等长的时分复用帧(TDM帧)。每一个时分复用的用户在每一个TDM帧中占用固定序号的时隙,所有用户轮流占用信道。

TDM帧是在物理层传送的比特流所划分的帧,标志一个周期。
改进的时分复用-统计时分复用STDM(动态)

波分多路复用WDM
利用光的频分多路复用,在一根光纤中传输多种不同波长的光信号,由于波长(频率)不同,所以各路光信号互不干扰,最后再用波长分解复用器将各路波长分解出来。

码分多路复用CDM(重点)
和CDM区分:码分多址(CDMA系统)[Code Division Multiple Access] 是码分复用的一种方式。
实现
- 1个比特分为多个码片/芯片(chip),每个站点被指定一个唯一的 m 位的芯片序列。(扩频技术:把原始信号的频带宽度扩宽,以达到提供该信号在信道传输的信噪比,达到抗干扰的功能)
- 发送1时站点发送芯片序列,发送0时发送芯片序列反码(通常把0写成-1)。
- 如何不打架:多个站点同时发送数据的时候,要求各个站点的芯片序列相互正交。
- 如何合并:各路数据在信道中被线性相加。
- 如何分离:合并的数据和源站规格化内积。
- 先来个学习前提 —— 规格化内积
规格化内积,计算方法就是S和T对应的码片序列每项相乘的和除以序列长。
规格化内积为0是正交

- A的芯片序列(1对应的序列集)是(1,−1,−1,+1,+1,+1,+1,−1)(1,-1,-1,+1,+1,+1,+1,-1)(1,−1,−1,+1,+1,+1,+1,−1)
- B的芯片序列是(−1,+1,−1,+1,−1,+1,+1,+1)(-1,+1,-1,+1,-1,+1,+1,+1)(−1,+1,−1,+1,−1,+1,+1,+1)
- 相互正交就是a0×b0+a1×b1+...+an−1×bn−1a_0×b_0 + a_1×b_1 + ... + a_{n-1}×b_{n-1}a0×b0+a1×b1+...+an−1×bn−1,即(−1)+(−1)+1+1+(−1)+1+1+(−1)8=0\cfrac{(-1) +(-1) + 1 + 1 +(-1)+ 1 + 1 +(-1)} { 8} = 08(−1)+(−1)+1+1+(−1)+1+1+(−1)=0,规格化内积为0即为正交,互不干扰。
- 获取传输数据,各个位对应处理,比如A的第二位0,B的第二位1
- 合并:(a0+b0,a1+b1,...,an−1+bn−1)(a_0+b_0 , a_1+b_1 , ... , a_{n-1}+b_{n-1})(a0+b0,a1+b1,...,an−1+bn−1),即(−1,+1,+1,−1,−1,−1,−1,+1)(-1,+1,+1,-1,-1,-1,-1,+1)(−1,+1,+1,−1,−1,−1,−1,+1)与(−1,+1,−1,+1,−1,+1,+1,+1)(-1,+1,-1,+1,-1,+1,+1,+1)(−1,+1,−1,+1,−1,+1,+1,+1)合并(线性相加)就是(−2,2,0,0,−2,0,0,2)(-2,2,0,0,-2,0,0,2)(−2,2,0,0,−2,0,0,2)
- 分离:比如我们要获取A的传输数据,就是把(−2,2,0,0,−2,0,0,2)(-2,2,0,0,-2,0,0,2)(−2,2,0,0,−2,0,0,2)和A的芯片序列(源站)进行规格化内积,即(1,−1,−1,+1,+1,+1,+1,−1)×(−2,2,0,0,−2,0,0,2)8=(−2−2+0+0−2+0+0−2)8=−1\cfrac{(1,-1,-1,+1,+1,+1,+1,-1)×(-2,2,0,0,-2,0,0,2)}{8} \\= \cfrac{(-2 - 2 + 0 + 0 - 2 + 0 + 0 - 2)}{8}\\ = -18(1,−1,−1,+1,+1,+1,+1,−1)×(−2,2,0,0,−2,0,0,2)=8(−2−2+0+0−2+0+0−2)=−1
即A传输来的数据为0(在CDM中用-1表示0)。
动态分配信道
- 先区分一下静态和动态划分信道
- 静态划分信道是在用户通信前固定分配给用户 。
- 动态划分信道就是动态媒体接入控制/多点接入,随机或轮询访问介质访问控制(随机~:所有用户可随机发送信息。发送信息时占全部带宽),信道并非在用户通信时固定分配给用户。
- 因为随机访问,也会容易导致不协调,引发冲突。
轮询访问介质访问控制
轮询访问
- 轮询协议
- 令牌传递协议
轮询协议
主节点轮流 “邀请” 从属结点发送数据。(就是从1-n个节点顺序询问是否发送数据,n节点访问结束后循环从1节点开始)
优缺点
- 优点:不会发生冲突,每次只能允许一台主机发送数据,该主机占用全部带宽。
- 缺点
- 轮询开销:询问的过程就是发送一个较短的数据帧,如果从属结点较多,就会多次轮询,产生较大的开销
- 等待延迟:对于靠后的主机,会有等待延迟。后面的主机需要等待前面的主机轮询结束
- 单点故障:处理管理的节点宕机了被管理的节点全都使用不了
令牌传递协议
主要用在令牌环局域网中。

令牌:一个特殊格式的MAC控制帧,不包含任何信息。控制信道的使用,确保同一时刻只有一个结点独占信道。(令牌环网无碰撞)
运行原理:
- 在一个逻辑上是环状的网络中,存在一个由几个bit组成的令牌在网络中不端循环;
当它循环到某个主机时发现他要传输数据,那么令牌就将自己的标志位置1并由令牌和数据组成一个数据帧发送给目的主机;但是如果这个主机发送的数据过多时,在规定时间片到达后就把令牌交给下一个主机发送数据;这样一直循环直到数据发送完成。
优缺点
- 优点:不会发生冲突,同一时刻只有一个结点独占信道,每个结点都可以在一定的时间内(令牌持有时间)获得发送数据的权利,并不
是无限制地持有令牌。 - 缺点
- 令牌开销
- 等待延迟
- 单点故障
应用于令牌环网(物理星型拓扑,逻辑环形拓扑)。
采用令牌传送方式的网络常用于负载较重、通信量较大的网络中。
ALOHA协议
ALOHA协议
- 纯ALOHA协议
- 时隙ALOHA协议
纯ALOHA协议
协议思想:当网络中的任何一个站点需要发送数据时,可以不监听信道,不按时间槽发送,2.随机重发。1.想发就发。
- 随机发送,不按照固定时间槽
- 如果在一段时间内未收到确认(类似超时重发),那么该站点就认为传输过程中发生了冲突,就等待一个随机长的时间再重新发送。直至发送成功。
检测冲突
- 如果发生冲突,接收方在就会检测出差错,然后不予确认,发送方在一定时间内收不到确认就判断发生冲突。
解决冲突
- 超时后等一随机时间再重传。
时隙ALOHA协议
协议思想:把时间分成若干个相同的时间片,所有用户在时间片开始时刻同步接入网络信道,若发生冲突,则必须等到下一个时间片开始时刻再发送。
作用就是控制想发就发的随意性,减少冲突的发生。
两者比较
- 纯ALOHA比时隙ALOHA吞吐量更低,效率更低。
- 纯ALOHA想发就发,时隙ALOHA只有在时间片段开始时才能发。
CSMA协议
载波监听多路访问协议CSMA(carrier sense multiple access)
- CS:载波监听,每个站在发送数据之前要检测一下总线上是否有其他计算机在发送数据。
- 当几个站同时在总线上发送数据时,总线上的信号电压摆动值将会增大( 互相叠加)。当一个站检测到的信号电压摆动值超过一定门限值时, 就认为总线上至少有两个站同时在发送数据,表明产生了碰撞,即发生了冲突。
- MA:多点接入,表示许多计算机以多点接入的方式连接在一根总线上。
执行过程
- 协议思想:发送帧之前,监听信道。
- 监听结果
- 信道空闲:发送完整帧
- 信道忙:推迟发送
- 是否立即发送和推迟多久如何处理
- 1-坚持CSMA
- 非坚持CSMA
- p-坚持CSMA(是对空闲的处理,空闲的时候不是直接发送数据)
1-坚持CSMA
坚持指的是对于监听信道忙之后的坚持。
思想:如果一个主机要发送信息,那么它先监听信道。
- 空闲则直接传输,不必等待。
- 忙则一直监听,直到空闲马上传输。
如果有冲突,则等待一个随机长的时间再监听(区别ALOHA是等待一个随机长时间发送数据帧,没有监听),重复上述过程。
优缺点
- 优点:只要媒体空闲,站点就马上发送,避免了媒体利用率的损失。
- 缺点:假如有两个或两个以上的站点有数据要发送(多个站点在监听等待发送),冲突就不可避免。
非坚持CSMA
非坚持指的是对于监听信道忙之后就不继续监听。
思想:如果一个主机要发送信息,那么它先监听信道。
- 空闲则直接传输,不必等待。
- 忙则等待一个随机的时间之后再监听
优缺点
- 优点:采用随机的重发延迟时间可以减少冲突发生的可能性(坚持是坚持监听,可能导致一个时间多个节点在监听,非坚持因为有个随机时间后再监听,会把时间叉开,减少冲突可能性)。
- 缺点:可能存在大家都在延迟等待过程中,使得媒体仍可能处于空闲状态,媒体使用率低。
p-坚持CSMA
p-坚持指的是对于监听信道空闲的处理。
p-坚持CSMA思想:如果一个主机要发送消息,那么它先监听信道。
- 空闲则以p概率直接传输,不必等待;概率1-p等待到下一个时间槽再传输。(空闲可能发送可能等待下一个时间槽)
- 忙则一直监听,直到空闲以p概率发送。
优缺点
- 优点:既能像非坚持算法那样减少冲突,又能像1-坚持算法那样减少媒体空闲时间。
- 缺点:发生冲突后还是要坚持把数据帧发送完,造成了浪费。
三种CSMA协议对比

CSMA/CD协议
载波监听/多路访问/碰撞检测 CSMA/CD(carrier sense multiple access with collision detection):从属于CSMA协议,也是先监听信道再发送数据,不同在发送数据的时候依旧监听,一旦发现冲突就停止对数据的发送,减少浪费。
- CS:载波监听,每个站在发送数据之前以及发送数据时要检测一下总线上是否有其他计算机在发送数据。
- MA:多点接入,表示许多计算机以多点接入的方式连接在一根总线上。 应用于总线型网络。
- CD:碰撞检测(冲突检测):“边发送边监听”,适配器边发送数据边检测信道上信号电压的变化情况,以便判断自己在发送数据时其他站是否也在发送数据。一旦发生冲突就停止数据的传输。应用于半双工网络(不允许双方同时发送信息)。
传播时延对载波监听的影响→冲突
- 因为电磁波在总线上总是以有限速率传播的,A向B和BxiangA发送信息(假设),A先发送数据,当A传输的数据还没有到达B(传播时延),B检测信道是空闲(没有信号进行B站点/主机),所以B可能发送数据。一旦发送数据在信道上就产生冲突和碰撞。

- A发送的信号和B发送的信号相碰叠加导致信号不一致,两端根据接收到的数据帧采用差错控制发现发生碰撞,停发。
- 只要经过 2τ(τ是单程段到端的传播时延) 时间还没有检测到碰撞,就能肯定这次发送不会发生碰撞。这种情况发生在A端先发送数据,B端刚发送数据就发生碰撞(A发送的数据快到达B)。
- 至多检测时间2τ,最少τ。
确定碰撞后的重传时机
- 截断二进制指数规避算法
- 确定基本退避时间为争用期2τ(传播时延)。
- 定义参数k,它等于当前重传次数,但k不超过10,即k=min[重传次数,10]k=min[重传次数,10]k=min[重传次数,10]。当重传次数不超过10时,k等于重传次数;当重传次数大于10时,k就不再增大而一直等于10。(k不是重传次数,是在重传次数和10中取最小值)
- 从离散的整数集合[0,1,(2k)−1][0, 1, (2^k) - 1][0,1,(2k)−1]中随机取出一个数r进行重传,重传所需要退避的时间是r倍的基本退避时间,即2r×τ2r×τ2r×τ。
- 当重传达16次仍不能成功,说明网络太拥挤,认为此帧永远无法正确发出,抛弃此帧并向高层报告出错。

- 若连续多次发生冲突,就表明可能有较多的站参与争用信道。使用此算法可使重传需要推迟的平均时间随重传次数的增大而增大,因而减小发生碰撞的概率,有利于整个系统的稳定
最小帧长问题
- 如果发送了一个很小的帧发生了碰撞,但是由于帧太短,帧发送完毕之后才能检测到发生了碰撞,已经没有办法停止发送。因此定义了最小帧长,希望在检测到碰撞的时候,帧还没发送结束。
- 帧的传输时延至少要两倍于信号在总线中的传播时延。
最小帧长=总线传播时延×数据传输速率×2最小帧长=总线传播时延×数据传输速率×2最小帧长=总线传播时延×数据传输速率×2

以太网规定最短帧长为64B,凡是长度小于64B的都是由于冲突而异常终止的无效帧。
CSMA/CA协议
载波监听多路访问/碰撞避免 CSMA/CA (carrier sense multiple access with collision avoidance)
为什么要有CA协议?
- CD协议对于无线局域网来说,无法做到360度全面碰撞检测
- 隐蔽站问题:当A和C都检测不到信号,认为信道空闲时,同时向终端B发送数据帧,就会导致冲突。
工作方法
- 发送数据前,先检测信道是否空闲。
- 是否发送
- 空闲则发出 RTS(request to send),RTS 包括发射端的地址、接收端的地址、下一份数据将持续发送的时间等信息;
- 信道忙则等待。
- 接收端收到 RTS 后,将响应 CTS(clear to send),即允许发送端发送数据。
- 发送端收到 CTS 后,开始发送数据帧(同时预约信道:发送方告知其他站点自己要传多久数据,其他站点传来的RTS均不接受)。
- 接收端收到数据帧后,将用 CRC 来检验数据是否正确,正确则响应 ACK 帧。
- 发送方收到 ACK 就可以进行下一个数据帧的发送,若没有则一直重传至规定重发次数(次数不重要)为止(也是采用二进制指数规避算法来确定随机的推迟时间)。
区别CSMA/CD 与 CSMA/CA
-
相同点:
- CSMA/CD 与 CSMA/CA 机制都从属于 CSMA的思路,其核心是 先听再发,接入信道之前必须要进行监听。当发现信道空闲时,才能进行接入。
-
不同点:
- 传输介质不同:CSMA/CD 用于总线式以太网【有线】,而CSMA/CA 用于无线局域网【无线】。
- 载波检测方式不同:因传输介质不同,CSMA/CD 与 CSMA/CA 的检测方式也不同。CSMA/CD通过电缆中电压的变化来检测,当数据发生碰撞时,电缆中的电压就会随着发生变化;而CSMA/CA 采用能量检测(ED)、载波检测(CS)和能量载波混合检测三种检测信道空闲的方式。
- CSMA/CD 检测冲突,CSMA/CA 避免冲突,二者出现冲突后都会进行有上限的重传。
局域网基本概念&体系结构
局域网
局域网 (Local Area Network):简称LAN,是指在某一区域内多台计算机互联成的计算机组,使用广播信道。
- 特点1:覆盖的地理范围较小,只在一个相对独立的局部范围内联,如一座或集中的建筑群内。
- 特点2:使用专门铺设的传输介质(双绞线、同轴电缆)进行联网,数据传输速率高(10Mb/s~10Gb/s)。
- 特点3:通信延迟时间短,误码率低,可靠性较高。
- 特点4:各站为平等关系,共享传输信道。
- 特点5:多采用分布式控制和广播式通信,能进行广播和组播。
决定局域网的主要要素为:网络拓扑结构,传输介质与介质访问控制方法。
局域网拓扑结构

介质访问控制方法
- CSMA/CD:常用于总线型局域网,也用于树型网络
- 令牌总线:常用于总线型局域网,也用于树型网络
- 它是把总线型或树型网络中的各个工作站按一定顺序如按接口地址大小排列形成一个逻辑环。只有令牌持有者才能控制总线,才有发送信息的权力。(逻辑上环形,物理上总线型)
- 令牌环:用于环形局域网,如令牌环网(逻辑上环形,物理上星形)。
局域网传输介质
- 有线局域网:双绞线、同轴电缆、光纤
- 无线局域网:电磁波
局域网分类
- 以太网:以太网是应用最为广泛的局域网,包括标准以太网(10Mbps) 、快速以太网( 100Mbps)、千兆以太网( 1000 Mbps)和10G以太网,它们都符合EE802.3系列标准规范。逻辑拓扑总线型,物理拓扑是星型或拓展星型。使用CSMA/CD。
- 令牌环网:物理上采用了星形拓扑结构,逻辑上是环形拓扑结构。已是“明日黄花”。
- FDDI网(Flber Distrlbuted Data Interface):光纤分布式数据接口,物理上采用了双环拓扑结构,逻辑上是环形拓扑结构。IEEE802.8。
- ATM网(Asynchronous Transfer Mode):较新型的单元交换技术,使用53字节固定长度的单元进行交换。
- 无线局域网(Wireless Local Area Network; WLAN):采用IEEE 802.11标准。
IEEE 802标准
- IEEE802系列标准是IEEE802LAN/MAN标准委员会制定的局域网、城域网技术标准(1980年2月成立)。其中最广泛使用的有以太网、令牌环、无线局域网等。这一系列标准中的每一个子标准都由委员会中的一个专门工作组负责。

MAC子层和LLC子层
IEEE 802标准所描述的局域网参考模型只对应OSI参考模型的数据链路层与物理层,它将数据链路层划分为逻辑链路层LLC子层和介质访问控制MAC子层。

- LLC负责识别网络层协议,然后对它们进行封装。LLC报头告诉数据链路层一旦帧被接收到时,应当对数据包做何处理。为网络层提供服务:无确认无连接、面向连接、带确认无连接、高速传送。
- MAC子层的主要功能包括数据帧的封装/卸装,帧的寻址和识别,帧的接收与发送,链路的管理,帧的差错控制等。MAC子层的存在屏蔽了不同物理链路种类的差异性。
以太网
以太网(Ethernet)指的是由Xerox公司创建并由Xerox、Intel和DEC公司联合开发的基带总线局域网规范,是当今现有局域网采用的最通用的通信协议标准。以太网络使用CSMA/CD(载波监听多点接入/冲突检测)技术。
局域网 + CSMA/CD → 以太网
以太网在局域网各种技术中占统治性地位:
- 造价低廉(以太网网卡不到100块);
- 是应用最广泛的局域网技术;
- 比令牌网、ATM网便宜,简单;
- 满足网络速率要求:10Mb/s~10Gb/s。
以太网两个标准(满足以下两个标准之一的可以被称为以太网)
- DIX Ethernet V2:第一个局域网产品(以太网)规约。
- IEEE 802.3:IEEE 802委员会802.3工作组指定的第一个IEEE的以太网标准(两者区别在于帧格式有一丢丢差别)
以太网提供无连接、不可靠的服务
- 无连接:发送方和接收方之间无 ”握手过程“ 。(不用事先建立连接)
- 不可靠:不对发送方的数据帧编号,接收方不向发送方进行确认,差错帧直接丢弃,差错纠正由高层(传输层)负责。
- 以太网只实现无差错接收,不实现可靠传输(发来的都接收)。
以太网传输介质的发展
- 粗同轴电缆 → 细同轴电缆 → 双绞线+集线器
以太网拓扑结构的发展
- 总线型→星型
- 虽然结构上是星型,但是在逻辑上仍是一个总线网。各站共享逻辑上的总线,使用的还是CSMA/CD协议。
- 现今,逻辑上总线型,物理上星型。(早先物理逻辑都是总线型)
以太网拓扑:逻辑上总线型,物理上星型。
非常常见的一种以太网:10BASE-T以太网
- 10BASE-T是传送基带信号(BASE)的双绞线以太网,T表示采用双绞线,现10BASE-T采用的是无屏蔽双绞线(UTP),传输速率是10Mb/s。
- 物理上采用星型拓扑,逻辑上总线型,每段双绞线最长为100m。
- 采用曼彻斯特编码。
- 采用CSMA/CD介质访问控制。(会产生冲突和碰撞)
适配器与MAC地址
- 计算机与外界有局域网的连接是通过通信适配器的。
- 在局域网中,硬件地址又称为物理地址,或MAC地址。MAC地址:每个适配器有一个全球唯一的48位二进制地址,前24位代表厂家(由IEEE规定),后24位厂家自己指定。常用6个十六进制数表示。02-60-8c-e4-b1-21
以太网MAC帧

- 最常用的MAC帧是以太网V2的格式。
- DIX Ethernet V2与IEEE 802.3的区别:
- 第三个字段是长度/类型(两个字节)
- 当长度/类型字段值小于0x0600时,数据字段必须装入LLC子层。
- 数据部分的最小字节(最小帧长)为46,因为CSMA/CD协议最小帧长64B,因此剩下的就是64-6-6-2-4=46B,最长是1500字节(MTU)
- FCS:CRC循环冗余检验的4个字节的帧检验序列
补充:
- 物理层七个字节前导码七个字节的101…用于数据同步,最后一个字节…11用于表示结束。
- 数据链路层加头加尾,有帧开始定界符,为啥没有帧结束定界符?
- 以太网使用曼彻斯特编码,一个比特内都有两个码元,帧结束时候电压就不会变了,轻松确认帧结束位置,往前4B进而得到数据结束位置!
- 每两个帧发送都会有一个间隔!间隔中是不会有电压变化的!
高速以太网
速率 ≥ 100Mb/s的以太网称为高速以太网。
-
00BASE-T以太网
- 在双绞线上传送100Mb/s基带信号的星型拓扑以太网,仍使用IEEE802.3的CSMA/CD协议。
- 支持全双工和半双工,可在全双工方式下工作而无冲突。
-
吉比特以太网
- 在光纤或双绞线上传送1Gb/s信号。
- 支持全双工和半双工,可在全双工方式下工作而冲突。
-
10吉比特
- 10吉比特以太网在光纤上传送10Gb/s信号。
无线局域网
IEEE 802.11 是无线局域网通用的标准,它是由IEEE所定义的无线网络通信的标准。
无线局域网和WIFI的区别 ?
- 无线局域网的覆盖范围比WIFI大得多;
- WIFI是802.11b和802.11g所定义的标准,满足这两个标准属于WIFI。
802.11的MAC帧头格式

例如:A,B两个设备和分别对应的两个基站AP1,AP2。A是发送设备,B是接送设备,A最近的基站是AP1,B最近的基站是AP2
- 接收端:实际通行中实现接收数据的基站的mac地址,则接收端就是mac(AP2)。
- 发送端:实际通行中实现发送数据的基站的mac地址,发送端就是mac(AP1)
- 目的地址mac(B)
- 源地址mac(A)
802.11的MAC帧头格式
- MAC头部长度为24(30-6[SA])或30字节,主要用于工作站与基站之间传递数据,由于数据的发送和接收方式不同,所以数据帧也会分类。

- 四个地址的介绍
-
Address 1字段代表帧接收端的地址(RA)
-
Address 2字段代表帧发送端的地址(TA)。接收端和发送端就是负责将无线电波解码为802.11帧的工作站,比如我们家里的无线路由器,手机WIFI等。发送端不一定是来源地,来源地是指产生帧中网络层协议封包的工作站。接收端不一定是目的地,目的地是指负责处理帧中网络层封包的工作站。接收端可以只是中间目的地,而帧只有达到目的地,才会由上层的协议加以处理。
-
Address 3字段则是供接入点与分布式系统过滤之用,不过该字段的用法取决于所使用的网络类型。
-
Address4只有在桥接模式时才会使用
-
- IBSS(Independent Basic Service Set)独立基本服务集,就是一个服务集内的移动站点不通过基站的直接通信。
- 目的地址和源地址的之间通信,不通过基站。
- BSSID是接入点AP唯一的MAC地址,区别于SSID(服务集标识符,比如WIFI的名字)。BSSID是地址,SSID是无线局域网的名。
- To AP:服务集内移动站向基站的通信。
- 移动站可以认为是手机,基站就是电信塔。
- 发往基站,那么接收端的BSSID就是基站的地址,发送端的SA是源地址。
- From AP:就是服务集内基站向移动站的通信。
- 由基站发出,那么发送端的BSSID就是基站,也就是基站地址 。接收端是移动站就是目的地址DA。
- WDS就是不同服务集内的两个移动站之间的通信(漫游),就是上面那个案例,MAC头部长度为30字节。
- 四个地址的介绍
无线局域网的分类
- 有固定基础设施无线局域网
- 无固定基础设施无线局域网的自组织网络
有固定基础设施无线局域网

无固定基础设施无线局域网的自组织网络

广域网
介绍:广域网(WAN,Wide Area Network),通常跨越很大的物理范围,所覆盖的范围从几十公里到几千公里,它能连接多个城市或国家,或横跨几个洲并能提供远距离通信,形成国际性的远程网络。
广域网的通信子网主要使用分组交换技术。广域网的通信子网可以利用公用分组交换网、卫星通信网和无线分组交换网,它将分布在不同地区的局域网计算机系统互连起来,达到资源共享的目的。如因特网(Internet)是世界上范围最大的广域网。

- 设备区别:
- 节点交换机:单个网络中转发分组
- 路由器:多个网络之间的转发分组
- 广域网VS局域网
- 广域网覆盖物理层、链路层一直到网络层,而局域网只覆盖物理层和链路层。
- 局域网通常采用多点接入技术,而广域网采用点对点连接。
- 广域网强调资源共享,而局域网强调数据传输。
- 广域网的传输速率比局域网高,但是传播延迟更长。广域网一般不提及传播时延。
PPP协议
点对点协议PPP(Point-to-Point Protocol)是使用串行线路通信的面向字节的协议,该协议应用在直接连接两个结点的链路上。只支持全双工链路。设计的目的主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种共同的解决方案。是目前使用最广泛的数据链路层协议。
PPP协议应满足的要求
- 简单:对于链路层的帧,无需纠错,只保证无差错接收(通过硬件进行CRC校验),无需序号(不可靠传输),无需流量控制。
- 封装成帧:帧头帧尾加入帧定界符
- 透明传输:与帧定界符一样比特组合的数据应该如何处理:异步线路用字节填充,同步线路用比特填充。
- PPP是面向字节的,当信息字段出现和标志字段一致的比特组合时,PPP有两种不同的处理方法:若用在异步线路(默认),则采用字节填充法;若用在同步线路,则采用比特填充法。
- 兼容多种网络层协议:封装的IP数据报可以采用多种协议。
- 满足多种类型链路:串行/并行,同步/异步,电/光…
- 差错检测:错就丢弃。
- 检测连接状态:检测链路是否正常工作。
- 最大传送单元:数据部分最大长度MTU不超过1500字节。
- 网络层地址协商:知道通信双方的网络层地址。
- 数据压缩协商:PPP协议发送数据的时候需要把数据进行压缩。
PPP协议无需满足的要求
- 无需纠错,仅需检错。只保证无差错接收(通过硬件进行CRC校验)
- 无需流量控制
- 无需编号,它是不可靠的传输协议,因此也不使用序号和确认机制。
- 不支持多点线路,只需要满足点对点的连接。PPP的两端可以运行不同的网络层协议,但仍然可以使用同一个PPP进行通信。
PPP协议的三个组成部分
- 一个将IP数据报封装到串行链路的方法(同步串行/异步串行):IP数据报在PPP帧中就是其信息部分,这个信息部分的长度受最大传送单元(MTU)的限制。
- 链路控制协议(LCP):一种扩展链路控制协议,用于建立、配置、测试和管理数据链路。[建立链路的连接,建立物理连接](身份验证)
- 网络控制协议(NCP):PPP协议允许同时采用多种网络层协议,每个不同的网络层协议要用一个相应的NCP来配置,为网络层协议建立和配置逻辑连接。[建立逻辑连接]
PPP协议状态图

PPP协议的帧格式
(以字节为单位的)

HDLC协议
高级数据链路控制(HDLC,High-Level Data Link Control),是一个在同步网上传输数据、面向比特的数据链路层协议,它是由国际标准化组织(ISO)根据IBM公司的SDLC(Synchronous Data Link Control)协议扩展开发而成的。
特点:
- 数据报文可透明传输,通过零比特填充法实现。
- PPP还可以实现字节填充(比如插入转义字符),HDLC只能实现零比特填充。
- 和PPP一样都是全双工通信。
- 所有帧采用CRC检测,对信息帧进行顺序编号,可防止漏收或重复,传输可靠性高。
HDLC的站
- 主站的主要功能是发送命令(包括数据信息)帧、接收响应帧、并负责对整个链路的控制系统的初启、流程的控制、差错检测或恢复等。
- 从站的主要功能是接收由主站发来的命令帧,向主站发送响应帧,并且配合主站参与差错恢复链路控制。
- 复合站的主要功能是既能发送,又能接收命令帧和响应帧,并且负责整个链路的控制。
三种数据操作方式:
- 正常响应方式(NRM)
- 正常响应方式(NRM)适用于不平衡链路结构,即用于点-点和点-多点的链路结构中,特别是点-多点链路。在这种操作方式,传输过程由主站启动,从站只有收到主允许,才能向主站发送响应。
- 异步响应方式(ARM)
- 异步响应方式(ARM)也适用于不平衡链路结构。它与NRM不同的是:在ARM方式中,从站可以不必得到主站的允许就可以开始数据传输。显然它的传输效率比NRM有所提高。
- 异步平衡方式(ABM)
- 异步平衡方式(ABM)适用于平衡链路结构。允许任何节点来启动传输的操作方式。为了提高链路传输效率,节点之间在两个方向上都需要的较高的信息传输量。每个站既可作为主站又可作为从站,每个站都是复合站,不管哪个复合站均可在任意时间发送命令帧,并且不需要收到对方复合站发出的命令帧就可以发送响应帧。
HDLC的帧格式

- 5 “1” 1 “0”:零比特填充是指每连续出现5个1时就在后面加入一个0
- 标志字段:这是一个8位序列,标记帧的开始和结束。 标志的位模式是01111110。也可以作为帧与帧之间的填充字符。
- 地址字段:包含接收者的地址。 如果该帧是由主站发送的,则它包含从站的地址。 如果它是复合站发送的,就是接收站的地址。 地址字段可以从1个字节到几个字节。
- 信息帧第一位为 0,用来传输数据信息,或使用捎带技术对数据进行确认 。
- 监督帧 10,用于流量控制和差错控制,执行对信息帧的确认、请求重发和请求暂停发送等功能。
- 无编号帧 11,用于提供对链路的建立、拆除等多种控制功能。
- 控制字段:用于构成各种命令及响应,以便对链路进行监控。长度1或2字节。
- 信息字段:承载来自网络层的数据。它的长度有FCS字段或通讯节点的缓存容量来决定。使用较多的上限是1000-2000比特;下限是0(S帧)。
- 帧校验字段:这是一个2字节或4字节的帧检查序列,用于对两个标志字段之间的内容进行错误检测。使用的是标准代码CRC(循环冗余代码)。
PPP协议 VS HDLC协议
相同
- HDLC、PPP只支持全双工链路。
- 都可以实现透明传输。不过PPP是0比特填充和字节填充都可以实现,HDCL只有0比特[ 5 “1” 1 ”0“]填充。
- 都可以实现差错检测(CRC循环冗余检验),但不纠正差错。
区别

链路层设备
设备和集线器之间距离最大100m,否则会严重失帧!

在物理层拓展以太网:
- 可以采用光纤的方式进行扩展。光纤解调器将电信号转换成光信号再在光线上传输。
- 用集线器将多台主机连接起来,多个集线器再被主干集线器连接,这样从属于不同集线器的主机就可以连接。(物理上星型,逻辑上总线型)
- 不过这种方法冲突域发生冲突概率太高了,通信效率降低。

- 为了解决这个问题,减小冲突但仍就扩大以太网的范围:在链路层拓展以太网。用到了网桥和交换机。两个或多个以太网通过网桥连接后,就成为一个覆盖范围更大的以太网,而原来的每个以太网就称为一个网段。网桥工作在链路层的MAC子层,可以使以太网各网段成为隔离开的碰撞域。
- 不过这种方法冲突域发生冲突概率太高了,通信效率降低。
网桥
- 网桥根据MAC帧的目的地址对帧进行转发和过滤。当网桥收到一个帧时,并不向所有接口转发此帧,而是先检查此帧的目的MAC地址,然后再确定将该帧转发到哪一个接口,或者是把它丢弃(即过滤)。(和集线器主要的区别就是集线器会从所有的端口转发出去,网桥会考虑应不应该从这个口转发,应该从哪个口转发)

- 网段
- 每一个以太网就是一个冲突域,也被称为网段。一般指一个计算机网络中使用同一物理层设备(传输介质√√√、中继器、集线器等)能够直接通讯的那一部分。
- 每一个以太网就是一个冲突域,也被称为网段。一般指一个计算机网络中使用同一物理层设备(传输介质√√√、中继器、集线器等)能够直接通讯的那一部分。
- 网桥优点
- 过滤通信量,增大吞吐量。
- 如果把网桥换成工作在物理层的转发器,那么就没有这种过滤通信量的功能。
- 带宽是指能够有效通过该信道的信号的最大频带宽度。所有如果每一个网段的传输速率(/带宽)是10bit/s,那么三个合起来最大的吞吐量就是30bit/s。(ab通信时c和d,e和f可以同时通信)
- 扩大了物理范围。
- 提高了可靠性。
- 网桥可以把网段隔离开。由于各网段相对独立,彼此不干扰,但不同网段的主机又可以交流通信 。因此一个网段的故障不会影响到另一个网段的运行。
- 可互连不同物理层、不同MAC子层和不同速率的以太网。
- 过滤通信量,增大吞吐量。
网桥分类
透明网桥
”透明“ 指以太网上的站点并不知道所发送的帧将经过哪几个网桥,是一种即插即用设备 —— 实现通过"自学习"算法(帧传输过程中要经过网桥接口,来自地址A的帧经过网桥时查看转发表,如果发现转发表没有记录,就记下该地址通过网桥时的接口(根据源MAC地址),也就是数据经过网桥要找到地址A需要经过哪个接口,这样以后经过网桥要传给地址A的数据就知道往网桥的1号接口走就能到达目的地址)。
通过自学习来构建转发表。每一个通过网桥的数据都会被记录下网桥收到数据时数据对应的地址和网桥自己的接口,通过许许多多的数据包构造的缓存,网桥就可以知道哪个数据包在哪个接口,以后如果要穿数据包就知道要往哪个接口发送数据包了。

- 初始转发表都是空。
- A发送数据,送往目的地址B。数据往左右两边走,所以A左边的G和B都能接收到(虽然B已经接收到了,但是A还会继续向右走,因为透明网桥中以太网上的站点不知道所发送的帧将经过哪几个网桥,只能通过自学习算法逐步填充转发表,通过转发表告知目的地址应该走哪个接口,但是初始转发表为空,没有记录目的地址B应该走哪个接口)。
- A经过1号网桥,发现转发表中没有记录A地址对应的接口,就在转发表中记录经过1号网桥要到达目的地址A需要走1号端口。同理经过2号网桥也记录经过2号网桥要到达目的地址A需要走1号端口。
- 这时候B要向目的地址A发送数据,B向左边和右边都发送数据,往左边A就接收到了。往右边经过1号网桥,查询转发表中有没有B地址(源地址)的信息,没有就记录。同时!发现目的地址A对应接口是1号端口,不用往右转发了,丢弃帧。(2号网桥的转发表此时不会记录目的地址B对应的接口,因为走不到2号网桥)
- 总结来是,源地址发送数据把能走的路都走。遇到网桥时查询一下源地址对应接口有没有记录,没有就添加记录。然后再查询一下目的地址对应接口有没有,如果有且和源地址在同一个方向就丢弃数据帧(不继续走了),有记录且不在同一个方向就按记录下的接口走,没有记录就都走。数据传输过程中不断填满转发表,即自学习算法。当然转发表一段时间全部清空,再次自学习,不断完善,及时更新。
源路由网桥
在发送帧时,把详细的最佳路由信息(路由最少/时间最短)放在帧的首部中。
方法:源站以广播方式向欲通信的目的站发送一个发现帧。
通过广播方式向目标地址发送广播,此时可能会经过不同路由产生不同的路径,目标地址收到后再将每一条路径都发一个响应帧给网桥,网桥经过对比就知道哪个接口最快。(把走过的最优路线记下,以后就按这个路线走)

多接口网桥:以太网交换机
以太网交换机本质上是一个多端口的网桥,它工作在数据链路层。交换机能经济地将网络分成小的冲突域,为每个工作站提供更高的带宽。
-
交换机通常有十几个端口,每个端口都可以直接连接主机或者连接集线器。
-
交换机同网桥一样,每个端口引出的区域都是一个冲突域。
-
交换机可以独占传输媒体带宽,交换机端口连接的集线器/主机都是独占媒体带宽,不同于集线器带宽被平分。
- 交换机工作原理:现在的数通设备基本都是存储-转发模式。外部接口之间不是直接联通的。数据帧从一个接口进入交换机后会进入内部存储模块,经芯片计算后再从需要的接口发出去。接口物理特性限制了接口最大带宽。现在普通的交换机都是千兆接口,但交换机内部处理芯片能达到几万兆或几十万兆。所有接口速率都满负荷也不会超过内部芯片处理能力。
- 集线器不管有多少个端口,所有端口都共享一条带宽,在同一时刻只能有两个端口传送数据,其他端口只能等待;只能工作在半双工模式下。交换机每个端口都有一条独占的带宽,当两个端口工作时并不影响其他端口的工作,交换机可以工作在半双工模式下也可以工作在全双工模式下。
 (这张图是3个冲突域,一个广播域。如果这里面把交换机换成集线器那么就是1个冲突域)
(这张图是3个冲突域,一个广播域。如果这里面把交换机换成集线器那么就是1个冲突域)
以太网交换机的三种方式:
-
直通式交换机:查完目的地址(6B)就立刻转发。
- 延迟最小,可靠性低,无法支持具有不同速率的端口的交换。所以它导致的转发时延是6b网络传输速率\frac{6b}{网络传输速率}网络传输速率6b
-
存储转发式交换机(主要使用):将帧放入高速缓存,并检查是否正确(先缓存后处理),正确则转发,错误则丢弃。
- 延迟最大,可靠性高,可以支持具有不同速率的端口的交换。
-
无碎片直通转发:类似直通交换,但它会在接受完64个字节之后再转发帧。
- 保证了不会将冲突帧转发出去。
冲突域VS广播域
-
冲突域:在同一个冲突域中的每一个结点都能收到被发送的帧。简单的说就是同一时间内只能有一台设备发送信息的范围。
-
广播域:网络中能接收任一设备发出的广播帧的所有设备的集合。简单的说如果站点发出一个广播信号,所有能接收到这个信号的设备的范围称为一个广播域。(接收信号的范围,广播的范围)

判断冲突域和广播域
- 冲突域(物理分段):
- 连接在同一导线上的所有工作站的集合,或者说是同一物理网段上所有节点的集合或以太网上竞争同一带宽的节点集合。在OSI模型中,冲突域被看作是第一层的概念,连接同一冲突域的设备有集线器,网线或者其他进行简单复制信号的设备。也就是说,用集线器,网线连接的所有节点可以被认为是在同一个冲突域内,它不会划分冲突域。而第二层设备(网桥,交换机)和第三层设备(路由器)都可以划分冲突域的,当然也可以连接不同的冲突域。
- 广播域:
- 接收同样广播消息的节点的集合。广播域被认为是OSI中的第二层概念,所以像集线器,交换机等第一,第二层设备连接的节点被认为都是在同一个广播域。而路由器,第三层交换机则可以划分广播域,即可以连接不同的广播域。
- 当图中没有路由器时,显然,不能隔离广播域,这是就有一个广播域。
- 当图中有路由器时,看路由器上有几个向外连接的端口就有几个广播域。数冲突域时,先看交换机下连接几台pc和集线器,就有几个冲突域,但要注意的是,路由器和交换机之间也是有冲突域的。也就是说,冲突域来源有(交换机连接的冲突域+路由器连接的交换机)[应该是,暂定]
第四章 网络层
网络层功能概述
主要任务是把分组从源端传到目的端,为分组交换网上的不同主机提供通信服务。网络层传输单位是数据报。
分组&数据报:父与子关系!
数据报是比较长的数据,分组是对数据报的分割。
功能:
- 路由选择与分组转发(选择最佳转发路径)
- 异构网络互联(靠路由器实现不同网络的互连)
- 拥塞控制(区别于流量控制,流量控制是发送方和接收方之间的协调,发送方发送太快,接收方告诉发送方慢点发;而拥塞控制是全局性,整个网络负载太重,导致分组转发速率太慢而大量的分组被丢弃)。所以需要采取一定措施缓解这种拥塞:
- 开环控制:静(网络工作前把产生拥塞的所有因素考虑到,采取预先的控制)
- 闭环控制:动(运行的时候动态调整)
数据交换方式
** **是一个可以把大量主机设备联系在一起的交换设备。
为什么要数据交换

数据交换方式
- 电路交换
- 报文交换
- 分组交换
- 数据报方式
- 虚电路方式
电路交换
例子:电话
在进行数据传输时,两个结点之间必须先建立一条专用(双方独占)的物理通信路径(由通信双方之间的交换设备和链路逐段连接而成),该路径可能经过许多中间结点。这一路径在整个数据传输期间一直被独占,直到通信结束后才被释放。
电路交换的阶段:建立连接、数据传输、释放连接。
电路交换的关键点是,在数据传输的过程中,用户始终占用端到端的固定传输带宽。
电路交换技术的优点:
- 通信时延小。由于通信线路为通信双方用户专用,数据直达,因此传输数据的时延非常小。当传输的数据量较大时,这一优点非常明显。
- 有序传输。双方通信时按发送顺序传送数据,不存在失序问题。
- 没有冲突。不同的通信双方拥有不同的信道,不会出现争用物理信道的问题。
- 适用范围广。电路交换既适用于传输模拟信号,又适用于传输数字信号。
- 实时性强。通信双方之间的物理通路一旦建立,双方就可以随时通信。
- 控制简单。电路交换的交换设备及控制均较简单。
电路交换的缺点:
- 建立连接时间长。电路交换的平均连接建立时间对计算机通信来说太长。
- 线路独占,使用效率低。电路交换连接建立后,物理通路被通信双方独占,即使通信线路空闲,也不能供其他用户使用,因而信道利用率低。
- 灵活性差。只要在通信双方建立的通路中的任何一点出了故障,就必须重新拨号建立新的连接,这对十分紧急和重要的通信是很不利的。
- 无差错控制能力。电路交换时,数据直达,不同类型、不同规格、不同速率的终端很难相互进行通信,也难以在通信过程中进行差错控制。
报文交换
数据交换的单位是报文。报文往下传传到传输层,传输层也可以对他进行一个分段处理,如果报文不大可以不处理。依次往下传给报文加上目标地址、源地址等信息。
报文交换在交换结点采用的是存储转发(先存,等到链路可用再转发)的传输方式。
报文交换的优点:
- 无需建立连接。报文交换不需要为通信双方预先建立一条专用的通信线路,不存在建立连接时延,用户可以随时发送报文。
- 动态分配线路。当发送方把报文交给交换设备时,交换设备先存储整个报文,然后选择一条合适的空闲线路,将报文发送出去。
- 提高线路可靠性。如果某条传输路径发生故障,那么可重新选择另一条路径传输数据,因此提高了传输的可靠性。
- 提高线路利用率。通信双方不是固定占有一整条通信线路,而是在不同的时间一段一段地部分占有这条物理通道,因而大大提高了通信线路的利用率。
- 提供多目标服务。一个报文可以同时发送给多个目的地址,这在电路交换中是很难实现的。
报文交换的缺点:
- 由于数据进入交换结点后要经历存储、转发这一过程,因此会引起存储转发时延。
- 报文交换对报文的大小没有限制,这就要求网络结点需要有较大的缓存空间。
分组交换
同报文交换一样,分组交换也采用存储转发方式,但解决了报文交换中大报文传输的问题。
分组交换限制了每次传送的数据块大小的上限,把大的数据块划分为合理的小数据块,在加上一些必要的控制信息(如源地址、目的地址和编号信息等),构成分组。每个分组为发送单元。

分组交换的优点:
- 无建立连接。不需要为通信双方预先建立一条专用的通信线路,不存在建立连接时延,用户可以随时发送分组。
- 存储转发,动态分配线路。
- 线路利用率高。通信双方不是固定占有一条通信线路,而是在不同的时间一段一段地部分占有这条物理通道,因而大大提高了通信线路的利用率。
- 简化了存储管理(相对于报文交换)。因为分组的长度固定,相应的缓冲区的大小也固定,在交换结点中存储器的管理通常被简化为对缓冲区的管理,相对比较容易。
- 加速传输。分组时逐个传输的,可以使后一个分组的存储操作与前一个分组的转发操作并行,这种流水线方式减少了报文的传输时间。此外,传输一个分组所需的缓冲区比传输一次报文所需的缓冲区小得多,这样因缓冲区不足而等待发送的概率及时间也必然少得多。
- 线路可靠性较高。减少了出错概率和重发数据量。因为分组较短,其出错概率必然减小,所以每次重发的数据量也就大大减少,这样不仅提高了可靠性,也减少了传输时延。
存储转发,动态分配线路
分组交换的缺点:
- 存在存储转发时延。尽管分组交换比报文交换的传输时延少,但相对于电路交换仍存在存储转发时延,而且其结点交换机必须具有更强的处理能力。
- 需要传输额外的信息量。每个小数据块都要加上源地址、目的地址和分组编号等信息。从而构成分组,因此使得传送的信息量增大了 5% ~ 10%,一定程度上降低了通信效率,增加了处理的时间,使控制复杂,时延增加。
- 乱序到达目的主机,需要对分组重排序。当分组交换采用数据报服务时,可能会出现失序、丢失或重复分组,分组达到目的结点时,要对分组按编号进行排序等工作,因此很麻烦。若采用虚电路服务,虽无失序问题,但有呼叫建立、数据传输和虚电路释放三个过程。
例子

传播延迟忽略!
- 第一种报文交换:发送时延10s,第一个交换机发出也要10s,第二个也要10s,第二个交换机到目的站点忽略不计,总共30s。
- 第二种分组交换:10000bit,每个分组10bit,共有1000个分组,由于分组是并行转发方式,因此只需要计算全部分组发送的时间再加上最后一个分组用掉的时延即可,即1000 × 0.01 + 0.01 × 2 = 10.02s
计算题中要注意的几点:
- 单位换算: b还是B(B是Byte字节,b是bit比特,1Byte=8bit),Mbps=106bps,kbps=103bps
- 是否考虑传播延迟(大部分不考虑)
- 时间至少是多少――选择最短路线
- 起始时间(从发送开始到接收完为止/从发送开始到发送完毕 [最后一个bit从原主机中出来了] )
- 是否有分组头部大小的开销
- 报文交换时延更长,分组交换时延可能不是整数
三种交换方式总结
- 电路交换是先建立连接再传输,传输过程中独占信道资源,传输结束释放连接。
- 报文交换和分组交换都采用存储转发,不需要预先建立信道,不是固定占用从原主机到目的主机的通信线路,而是在不同的时间一段一段地部分占有这条物理通道。
- 传送数据量大,且传送时间远大于呼叫时间,选择电路交换。电路交换传输时延最小(不需要存储转发)。
- 从信道利用率看,报文交换和分组交换优于电路交换,其中分组交换时延更小。

数据报方式,虚电路方式
分组交换
- 数据报方式为网络层提供无连接服务。
- 无连接服务:不事先为分组的传输确定传输路径,每个分组独立确定传输路径,不同分组传输路径可能不同。
- 虚电路方式为网络层提供连接服务。
- 连接服务:首先为分组的传输确定传输路径(建立连接),然后沿该路径(连接)传输系列分组,系列分组传输路径相同,传输结束后拆除连接。
数据通过网络的传输过程

- 报文就是要传输的数据。
- 如果报文过大就要对报文进行分割,也就是报文段,也可以不分割。
- 报文段到了网络层要封装上IP地址(源地址,目的地址),这就是IP数据报,如果数据包过大就要分割变成分组。
- 在原来的数据包或者分组上加头加尾(帧检验序列),封装成帧。
- 以比特流的形式转化成信号进行传输。
数据报(因特网在用)
- 无连接,不事先为分组的传输确定传输路径,每个分组独立确定传输路径,不同分组传输路径可能不同。
- 网络尽最大努力交付,传输不保证可靠性,所以可能丢失,为每个分组独立地选择路由,转发的路径可能不同,因而分组不一定按序到达目的结点。
- 每个分组携带源地址和目的地址,发送的分组中要包括发送端和接收端的完整地址,以便可以独立传输。
- 路由器根据分组的目的地址转发分组。,基于路由协议/算法构建转发表;检索转发表;每个分组独立选路。
- 分组在交换结点存储转发时,需要排队等待处理,这会带来一定的时延。通过交换结点的通信量较大或网络发生拥塞时,这种时延会大大增加,交换结点还可根据情况丢弃部分分组。
- 网络具有冗余路径,当某个交换结点或一条链路出现故障时,可相应地更新转发表,寻找另一条路径转发分组,对故障的适应能力强。
- 收发双发不独占某条链路,资源利用率较高。
虚电路
虚电路将数据报方式和电路交换方式结合,以发挥两者优点。
虚电路:一条源主机到目的主机类似于电路的路径(逻辑连接),路径上所有结点都要维持这条虚电路的建立,都维持一张虚电路表,每一项记录了一个打开的虚电路的信息。
通信过程:
- 建立连接(虚电路建立):源主机发送“呼叫请求”分组并收到“呼叫应答”分组后才算建立连接,每个分组携带虚电路号(根据虚电路表知道怎么走)。。
- 数据传输:全双工通信。
- 释放连接(虚电路释放):源主机发送“释放请求”分组以拆除虚电路。
数据报VS虚电路

IP数据报协议
TCP/IP协议栈

IP数据报格式
固定部分都是20B(字节),可变部分可有可无。

很重要! 这个图每行32位也就是4字节,头部占5行也就是20字节。

- 版本:指IP的版本,IPv4 / IPv6
- 首部长度:记录这个数据报的首部有多长,占4位,然后首部长度的单位是4B(字节)。可以表示的最大十进制数是15,最小从5开始(为了保证IP数据包一定满足固定部分的20B,所以从5开始,5×4字节=20字节,也就是固定部分的长度)。以32位为单位,最大值为60B(15x4B)。最常用的首部长度是20B。
- 区分服务:指示期望获得哪种类型的服务。
- 总长度:占16位,首部长度 + 数据部分长度,单位是 1B。数据报的最大长度位 216 - 1 = 65535B。以太网帧的最大传送单元(MTU)位1500B,因此当一个IP数据报封装成帧时,数据报的总长度一定不能超过下面的数据链路层的MTU值,一旦超过就要进行分片。
- 标识:占16位。它时一个计数器,每产生一个数据报就加1,并赋值给标识字段。当一个数据报的长度超过网络的MTU时,必须分片,此时每个数据报片都复制一次标识号,以便能正确重装成原来的数据报。同一数据报的分片使用同一标识。
- 标志:占3位。xxx,最高位无意义,标志字段的最低位 MF,MF = 1 表示后面还有分片,MF = 0 表示最后一个分片或没有分片。标志字段中间的一位时 DF,只有当 DF = 1 时才允许分片。
- 片偏移:占13位。它指出较长的分组在分片后,某片在原分组中的相对位置。片偏移以8个字节为偏移单位,即每个分片的长度一定是8B(64位)的整数倍。(除了最后一个分片,每个分片的长度一定是8B的整数倍)
- 生存时间(TTL):IP分组的保质期,占8位。数据报在网络中可通过的路由器数的最大值,标识分组在网络中的寿命,以确保分组不会永远在网络中循环。经过一个路由器 -1,变成 0 则丢弃。
- 协议:占8位。指出此分组携带的数据部分使用何种协议,即分组的数据部分应交给哪个传输层协议,如TCP、UDP等。其中值为6表示TCP,值为17表示UDP。
- 首部校验和:检验首部的字段,采用的求和,占16位。IP数据报的首部校验和只校验分组的首部,而不校验数据部分。
- 源地址字段:占32位,标识发送方的IP地址。
- 目的地址字段:占32位,标识接收方的IP地址。
- 可选字段:可有可无,0~40B,用来支持排错、测量以及安全等措施。
- 填充:全0,把首部补成4B的整数倍,补全的作用。
总结一下:头部设计到的三个单位
- 总长度单位1B
- 片偏移单位8B
- 首部长度单位4B
口诀:[一种(种 - 总长度)] [八片(片-片偏移)] 的 [首(首部长度)饰]
最大传送单元MTU
- 一个数据链路层数据报能承载的最大数据量称为最大传送单元(MTU)。因为IP数据报被封装在数据链路层数据报中,因此数据链路层的MTU严格地限制着 IP 数据报的长度。以太网的MTU是1500字节。
IP分组经过数据链路层的封装,加头加尾,IP分组形成了数据帧的数据部分,数据部分有个最大要求,就是不能超过MTU这个上限值,以太网中数据部分的最大值就是1500字节,如果传送的数据报长度超过MTU就要进行分片。
数据报分片:当IP数据报的总长度大于链路MTU时,就需要将IP数据报中的数据分装在两个或多个较小的IP数据报中,这些较小的数据报称为片。

如何分片?这里就要用到标识,标志,片偏移。
- 标识:同一数据报采用同一标识,占16位。它时一个计数器,每产生一个数据报就加1,并赋值给标识字段。当一个数据报的长度超过网络的MTU时,必须分片,此时每个数据报片都复制一次标识号,以便能正确重装成原来的数据报。同一数据报的分片使用同一标识。
- 标志:占3位。x_ _,最高位无意义。
- 标志字段中间的一位是 DF(Don’t Fragment),只有当 DF = 0 时才允许分片,DF = 1 时禁止分片。
- 标志字段的最低位 MF(More Fragment),MF = 1 表示后面还有分片,MF = 0 表示最后一个分片/没有分片(没有超过MTU) 。
- 片偏移:占13位。它指出较长的分组在分片后,某片数据部分在原分组中数据部分的相对位置。片偏移以8个字节为偏移单位,即每个分片的长度一定是8B(64位)的整数倍。(除了最后一个分片,每个分片的长度一定是8B的整数倍)
举例:最大MTU为1420B,其中20字节要作为分片的首部(每个分片拥有字节的首部)。所有3800B被分成1400B + 1400B + 1000B。

IP地址的分类
介绍一下IP地址的结构
IPV4地址
- IP地址:全世界唯一的32位/4字节标识符,标识路由器主机的接口。
- IP地址:= {<网络号>,<主机号>}
- 网络号标志主机(或路由器)所连接到的网络。主机号标志着该主机(或路由器)。
- 每个IP地址包括两部分:网络号和主机号。当分配给主机号的二进制位越多,则能标识的主机数就越多,相应地能标识的网络数就越少,反之同理。

如何区分一个IP地址哪部分是网络号,哪部分是主机号:
- 给出一个IP地址,我们可以通过子网掩码确定这个IP地址的网络号和主机号。
- 子网掩码的作用就是将某个IP地址划分成网络地址和主机地址两部分。

截图取自2

路由器可以划分广播域,在子网掩码都是255.255.255.0的基础上,LAN1的网络号是222.1.3.0,LAN3的网络号是222.1.2.0。
路由器的每一个接口都有一个不同网络号的IP地址,所以说路由器可以连接不同的网络的。
绿色区域的三条线是无编号网络(了解即可)。
分类


- A:两个-2都减的一个是1全0,一个全1,第一个可用的是0-0000001
- B:-1减的是全0,因为前两位已经被占用也就是说最小从10-000000 00000001 也就是128.1
- C:-1减的是全0,因为前三位已经被占用也就是说最小从110-00000 00000000 00000001 也就是192.0.1
特殊的IP地址

- 全0就是本网范围内的本机,发送方。
- 0.0.0.x,本网主机号为x的主机,接收方。
- 255.255.255.255,本网所有可以广播的主机,接收方。
- x.x.x.0,网络地址为x.x.x.0,就是一个网络(前面有提到)。
- x.x.x.255,网络地址为x.x.x.0的网络上的所有主机。
- 127是A类网络,永远不会进入网络的,只是给本机发送数据,即环回测试。
私有IP地址
路由器对目的地址是私有IP地址的数据报一律不进行转发。
采用私有IP地址的互联网络称为专用互联网或本地互联网。

网络地址转换NAT
网络地址转换(NAT) 是指通过将专用网络地址(LAN端)转换为公用地址(WLAN端),从而对外隐藏内部管理的IP地址。它使得整个专用网只需要一个全球IP地址就可以与因特网连通,由于专用网本地IP地址是可重用的,所以NAT大大节省了IP地址的消耗。
私有IP地址只用于LAN,不用于WAN连接(因此私有IP地址不能直接用于Internet,必须通过网关利用NAT把私有IP地址转换为Internet中合法的全球IP地址后才能用于Internet),并且允许私有IP地址被LAN重复使用。这有效地解决了IP地址不足的问题。
使用NAT时需要在专用网连接到因特网的路由器上安装NAT软件,NAT路由器至少有一个有效的外部全球地址。使用本地地址的主机和外界通信时,NAT路由器使用NAT转换表将本地地址转换成全球地址,或将全球地址转换成本地地址。NAT转换表中存放着 {本地IP地址:端口} 到{全球IP地址:端口} 的映射。通过{ip地址:端口}这样的映射方式,可让多个私有IP地址映射到同一个全球IP地址。

比如A要向B发送数据,先封装加上目的地址和源地址,A再把数据发送到NAT路由器,在这里根据NAT转换表对源地址进行转换,比如是192.168.0.3:30000就改成172.38.1.5:40001,再发送到B。反向同理,先发送NAT,再由NAT根据转换表发送给A。
子网划分
分类的IP地址的弱点
- IP地址空间的利用率有时很低。
- 给每个物理网络分配一个网络号会使路由表变得太大而网络性能变坏。
- 两级IP地址不够灵活。
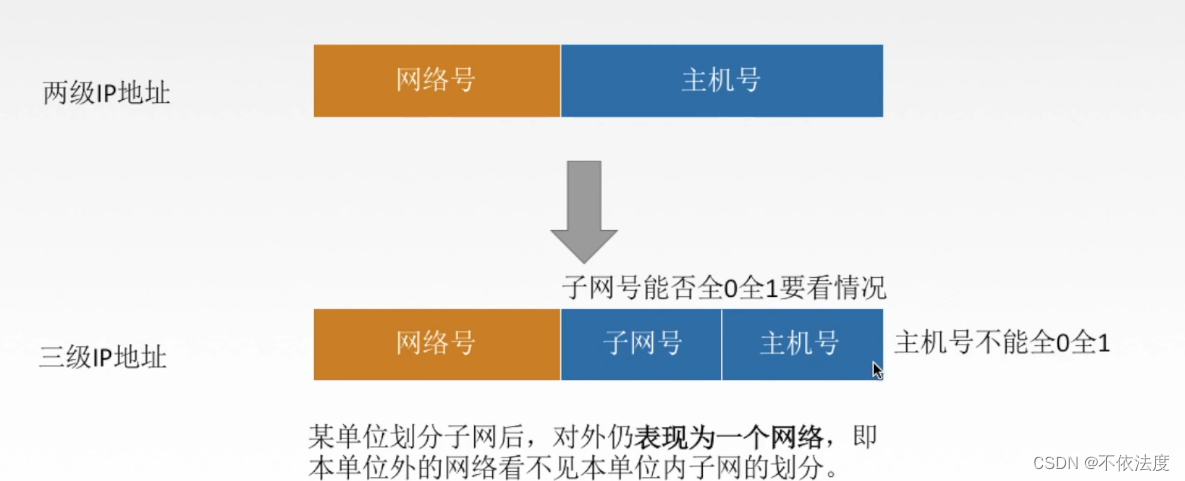
子网划分:在IP地址中增加一个子网号字段,使两级IP地址变成了三级IP地址。
要注意:
- 主机号全0或者全1都是不被允许的,所以至少留下两位主机号。
- 子网号能不能全0,全1看情况。(没说默认 当作不能吧)
- 某单位划分子网后,对外表现为一个网络,即本单位外的网络看不见本单位内子网的划分。
基本思路
- 子网划分纯属一个单位内部的事情。单位对外仍然表现为没有划分子网的网络。
- 从主机号借用若干比特作为子网号,当然主机号也就相应减少了相同比特。 三级IP地址的结构如下:IP地址 = {<网络号>,<子网号>,<主机号>}。
- 凡是从其他网络发送给本单位某台主机的IP数据报,仍然是根据IP数据报的目的网络号,先找到连接到本单位网络上的路由器。然后该路由器在收到IP数据报后,再按目的网络号和子网号找到目的子网。最后把IP数据报直接交付给目的主机。
子网掩码
- 子网掩码是一个与IP地址相对应的、长32bit的二进制串,它由一串1和跟随的一串0组成。
- 其中,1对应于IP地址中的网络号及子网号,而0对应于主机号。
- 计算机只需将IP地址和其对应的子网掩码逐位“与”(逻辑AND运算),就可得出相应子网的网络地址。
例子一

- 72:01001000,192:11000000,141属于B类网络,网络号占2B,剩下是1的是子网号,所以子网号占2位。
根据子网掩码划分IP地址:<11111111 11111111><111><00000 0000000>
网络地址是IP&子网掩码 = 141(10) 14(10) 01000000 00000000 = 141.14.64.0 - 72:01001000,224:11100000,141属于B类网络,网络号占2B,剩下是1的是子网号,所以子网号占3位。
根据子网掩码划分IP地址:<11111111 11111111><111><00000 0000000>
网络地址是IP&子网掩码 = 141(10) 14(10) 01000000 00000000 = 141.14.64.0
例子二

- 发送广播分组即主机号全1。
- 180属于B类网络,网络号占2B,也就是180.80,252 = 11111100,所以子网号是为1的剩下6位,77 = 01001101,子网号就是01001100,所以目的地址是180.80.<010011><11.11111111> = 180.80.79.255。
- 选D。
子网分组的转发
路由表中有:
- 目的网络地址
- 目的网络子网掩码
- 下一跳地址
使用子网掩码时路由器的分组转发算法
- 从数据报的首部提取目的主机的IP地址D。
- 先判断是否为直接交付。对和主机相连的路由器的子网掩码”想与“得出目的网络地址为S,若S就是与此路由器直接相连的某个网络地址,直接交付。否则间接交付,执行步骤3)
- 若路由器中有目的地址为D的特定主机路由,则将分组传给路由表中所指明的下一跳路由器;否则,执行步骤4)。
- 如果路由表中没有特定主机路由,则检测路由表中有无路径,对路由表中的每一行(目的网络地址、子网掩码、下一跳地址)中的子网掩码和D逐位相“与”,其结果为N。若N与该行的目的网络地址匹配,则将分组传送给该行指明的下一跳路由器;否则,执行步骤5)。
- 若路由表中有一个默认路由 0.0.0.0,则将分组传送给路由表中所指明的默认路由器;否则,执行步骤6)。
- 丢弃(有TTL规定最大转发次数),报告转发分组出错。
区分2、4:2是检测与主机直接相连的路由器,4是检测目标网段与主机的路由转发表

无分类编址CIDR
先区分一下定长子网掩码和变长子网掩码
- 定长就是那些A,B,C类

无分类域间路由选择是在变长子网掩码的基础上提出的一种消除传统 A、B、C类网络划分,并且可以在软件的支持下实现超网构造的一种IP地址的划分方法。
- 消除了传统的A类,B类和C类地址以及划分子网的概念。
- 融合子网地址与子网掩码,方便子网划分。
IP地址的无分类两级编址为:IP = {<网络前缀>, <主机号>}
- 斜线记法:IP地址/网络前缀所占比特数。距离192.199.170.82/27,前27位是网络前缀,主机号是五位,也就是最多有25个主机。
- 其中,网络前缀所占比特数对应于网络号的部分,等效于子网掩码中连续1的部分。

只有基于变长子网掩码基础上才有CIDR,24位前缀数对应网络号部分(192是C类网络,也是24位(3B)网络号),所以子网划分只能划分最后8位。这里只是假设如果是定长,子网掩码就是255.255.255.248(11111111.11111111.11111111.11111000)也就是说子网号有五位,所以最大子网数是25,剩下三位作为主机号,但不可全0或全1,所以23-2 = 6.

构成超网
将多个子网聚合成一个较大的子网,叫做构成超网,或路由聚合。
对于这种一个路由连接多个网络,多个网络在路由器转发表中对应的下一跳地址都相同的,就可以合并。
方法:将网络前缀缩短。

CIDR地址块中的地址数一定是2的整数次幂,实际可指派的地址数通常为 2N - 2(去掉全0和全1),N 表示主机号的位数,主机号全0代表网络号,主机号全1为广播地址。
最长前缀匹配
将提供的目的地址和路由转发表每一行的前缀数代表的子网掩码进行“相与”,得到的目的网络和当行的目的网络相同的进入备选,多个备选选前缀数最大的那个。

目的地址是11101100.00010011.11101101.00000101
路由表
R1:目的地址与11111111.0.0.0想与为132.0.0.0,相同,备选。
R2:目的地址与11111111.11100000.0.0想与为132.0.0.0,相同,备选。
R3:目的地址与11111111.11111111.11111100.0想与为132.19.59.0,不相同,pass。
R4:目的地址与0.0.0.0想与为0.0.0.0,相同,备选。(???)
R2前缀数最长,选他。
地址解析协议 ARP
先区分一下IP地址(逻辑地址)与MAC地址(硬件地址,物理地址)
IP地址是网络层使用的地址,它是分层次等级的。硬件地址是数据链路层使用的地址(如MAC地址),它是平面式的。在网络层及网络层之上使用IP地址,IP地址放在IP数据报的首部,而MAC地址放在MAC帧的首部。通过数据封装,把IP数据报分组封装为MAC帧后,数据链路层看不见数据报分组中的IP地址。
在实际网络的链路上传送数据帧时,最终必须使用硬件地址。
而APR协议的作用就是:完成主机或路由器IP地址到MAC地址的映射。(解决下一条走哪的问题),有一个ARP高速缓存,可以看作一个容器,存储的是同一个局域网内部的IP地址与MAC地址的映射。
ARP协议使用了IP地址和MAC地址,属于网络层和链路层的协议,两层协议,但一般将其归为网络层协议,在TCP/IP协议栈中处于网络层IP的最左下角接近链路层的位置!
ARP协议工作原理:
先走一下发送数据的过程:假设主机1要向主机3发送一个文件(一个局域网中)
- 应用层的报文传输到传输层,如果太大会划分成报文段。
- 在网络层逐个对报文段封装,加上源主机IP地址,目的主机IP地址(通过传输层的DNS填入),这样就形成了一个分组/IP数据报。
- 接着对IP数据报加上源MAC地址和目的MAC地址完成封装,如何知道MAC地址就要通过ARP协议了。
- 检查ARP高速缓存,有对应表项则写入MAC帧
- 没有则用目的MAC地址为FF-FF-FF-FF-FF-FF(全1)的帧封装并广播ARP请求分组,同一局域网中所有主机都能收到该请求。目的主机收到请求后就会向源主机单播一个ARP响应分组,源主机收到后将此映射写入ARP缓存(10-20min更新一次)。
- 接着封装再加上真检验序列GCS,形成一个数据帧。
- 数据帧传输到物理层放到链路上传输。

如果不是同一个局域网,比如1号主机向5号主机发送数据:
- 源IP地址是IP1,目的IP地址是IP5,所以到链路层封装要装上源和目的的MAC地址,源目的地址是MAC1,目的MAC地址会先去ARP高速缓存中查找(ARP高速缓存存储的是局域网内IP和MAC的映射,所以肯定没有)
- 这个的判断就是拿源IP所在网络的掩码和目的IP相与发现不是在同一个局域网,所以就去查默认网关的MAC地址,所以先以默认网关的MAC地址作为目的MAC地址
- 怎么获得MAC6的地址:
- 发送一个广播ARP请求分组
- 路由器单薄返回ARP响应分组
- 发送一个广播ARP请求分组
- 下一跳填上MAC6的目的地址就好
- 下一步是MAC7到MAC8,
- 获取目的MAC同上,略
- 下一步是MAC9到MAC5,
- 获取目的MAC同上,略

源IP和目的IP不变,变的都是源和目的MAC地址,一层层找下去!
- 获取目的MAC同上,略
总结ARP协议使用过程:
- 检查ARP告诉缓存,有对应表项则写入MAC帧,没有则用目的MAC地址位FF-FF-FF-F-FF-FF的帧封装并广播ARP请求分组,同一局域网中所有主机都能收到该请求。目的主机收到请求后就会向源主机单播一个ARP响应分组,源主机收到后将此映射写入ARP缓存(10-20min更新一次,每台主机(包括网关)都有一个 ARP缓存表 ,该表中保存这个网络中各个电脑的IP地址和MAC地址的映射关系)
为什么要使用ARP协议:由于在实际网络的链路上传送数据帧时,必须使用MAC地址,所以需要ARP协议帮忙找到下一跳MAC地址。
ARP协议4种典型情况
- 主机A发给本网络上的主机B:用ARP找到主机B的硬件地址;
- 主机A发给另一网络上的主机B:用ARP找到本网络上一个路由器(网关)的硬件地址;
- 路由器发给本网络的主机A:用ARP找到主机A的硬件地址;
- 路由器发给另一网络的主机B:用ARP找到本网络上一个路由器(网关)的硬件地址。
从IP地址到硬件地址的解析是自动进行的,主机的用户并不知道这种地址解析过程。只要主机或路由器和本网络上的另一个已知IP地址的主机或路由器进行通信,ARP就会自动地将这个IP地址解析为数据链路层所需要的硬件地址。

动态主机配置协议 DHCP
主机获取IP地址的方式:
- 静态配置
- 动态配置
动态主机配置协议(Dynamic Host Configuration Protocol)常用于给主机动态地分配IP地址。(比如移动设备:手机,电脑)
动态主机配置协议DHCP是应用层协议,使用客户/服务器方式,客户端和服务端通过广播方式进行交互,基于UDP。
DHCP提供即插即用联网的机制,主机可以从服务器动态获取IP地址、子网掩码、默认网关、DNS服务器名称与iP地址,允许地址重用(一个地址之前被a使用,a不用了释放,b可以用这个地址,参考wifi),支持移动用户加入网络,支持在用地址续租。
DHCP服务器聚合DHCP客户端的交换过程(DHCP工作流程):
-
DHCP客户机(主机)广播”DHCP发现“报文,试图找到网络中的DHCP服务器,以便从DHCP服务器获得一个IP地址。(问网络内所有设备有没有DHCP服务器)
-
DHCP服务器收到”DHCP发现“消息后,向网络中广播”DHCP提供“消息,从尚未出租的IP地址中(包含IP地址和相关配置信息)挑选一个分配给DHCP客户机,先发来的IP地址先用。(回复有DHCP服务器)
-
DHCP客户机选择某台DHCP服务器提供的IP地址的阶段。DHCP客户机收到”DHCP提供“消息,如果接收DHCP服务器所提供的相关参数,那么通过广播”DHCP请求“消息向DHCP服务器请求提供IP地址。(广播是为了通知所有的DHCP服务器,他将选择某台DHCP服务器所提供的IP地址)
-
DHCP服务器广播“DHCP确认”消息,将IP地址正式分配分配给DHCP客户机。
注意点
- DHCP允许网络上配置多台DHCP服务器,当DHCP客户机发出DHCP请求后,有可能收到多个应答消息,这时DHCP客户机通常挑选最先到达的。
- DHCP服务器分配给DHCP客户的IP地址是临时的,因此DHCP客户只能在一段有限时间内使用这个分配到的IP地址。DHCP称这段时间为租用期。租用期的数值应由DHCP服务器自己决定,DHCP客户也可以在自己发送的报文中提出对租用期的要求。
- 采用广播方式进行交互的原因是在DHCP执行初期,客户端不知道服务器端的IP地址,而在执行中间,客户端并未分配IP地址,从而导致两者之间的通信必须采用广播方式。采用UDP而不采用TCP的原因也很明显:TCP需要建立连接,如果连对方的IP地址都不知道,那么更不可能通过双方的套接字建立连接。
网际控制报文协议 ICMP
为了提高IP数据报交付成功的机会,在网络层使用了网际控制报文协议(Internet Control Message Protocol,ICMP)来让主机或路由器报告差错和异常情况。ICMP报文作为IP层数据报的数据,加上数据报的首部,组成IP数据报发送出去。ICMP是IP层协议。
ICMP报文格式

ICMP报文分为 ICMP差错报告报文 和 ICMP询问报文。
ICMP差错报告报文
ICMP差错报告报文用于目标主机或到目标主机路径上的路由器向源主机报告差错和异常情况。共5种类型。
- 终点不可达。当路由器或主机不能交付数据报时,就向源点发送终点不可达报文。(无法到达)
- 源点抑制。当路由器或主机由于拥塞而丢弃数据报时,就向源点发送源点抑制报文,使源点知道应当把数据报的发送速率放慢。(拥塞丢数据,不过这种已经取消)
- 时间超过。当路由器收到生存时间(TTL)为零的数据报时,除丢弃该数据报外,还要向源点发送时间超过报文。当终点在预先规定的时间内不能收到一个数据报的全部数据报片时,就把已收到的数据报片都丢弃,并向源点发送时间超过报文。(TTL = 0)
- 参数问题。当路由器或目的主机收到的数据报的首部中有的字段的值不正确时,就丢弃该数据报,并向源点发送参数问题报文。(首部字段有问题)
- 改变路由(重定向)。路由器把改变路由报文发送给主机,让主机知道下次应将数据报发送给另外的路由器(可通过更好的路由)。
ICMP差错报告报文数据字段(ICMP前八个字节是类型)

不应发送ICMP差错报告报文的几种情况:
- 对ICMP差错报告报文不再发送ICMP差错报告报文。
- 对第一个分片的数据报片的所有后续数据报片都不发送ICMP差错报告报文。
- 对具有组播地址(一点到多点,有选择性的,广播也是一点到所有点,但是没有选择性)的数据报都不发送ICMP差错报告报文。
- 对具有特殊地址(如127.0.0.0或0.0.0.0)的数据报不发送ICMP差错报告报文。
ICMP询问报文
有4种类型:
- 回送请求和回答报文:主机或路由器向特定目的主机发出的询问,收到此报文的主机必须给源主机或路由器发送ICMP回送回答报文(比如ping就是)。测试目的站是否可达以及了解其相关状态。
- 时间戳请求和回答报文:请某个主机或路由器回答当前的日期和时间。用来进行时钟同步和测量时间。
- 掩码地址请求和回答报文。(几乎不用)
- 路由器询问和通告报文。(几乎不用)
ICMP的主要应用
- PING:用来测试两台主机之间的连通性。使用了ICMP回送请求和回答报文。工作在应用层。
- Trancerout/Tracert:用来跟踪分组经过的路由。使用了ICMP时间超过差错报告报文。工作在网络层。
IPv6
解决“IP地址耗尽”问题的措施有以下三种:
- 采用无类别编制CIDR,使IP地址的分配更加合理。
- 采用网络地址转换(NAT)方法以节省全球IP地址。
- 采用具有更大地址空间的新版本的IPv6。( 根本上解决)
- 改进首部格式:快速处理/转发数据报和支持QoS
- QOS ( Quality of Service,服务质量)指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制,是用来解决网络延迟和阻塞等问题的一种技术。
IPv6数据报格式

基本首部40B是固定的,数据报需要增加什么功能(不是必要的功能)就在扩展首部(可有可无)那里处理。
- 版本:指明了协议版本,总是6。
- 优先级:区分数据报的类别和优先级。
- “流”是互联网络上从特定源点到特定终点的一系列数据报。所有属于同一个流的数据报都具有同样的流标签。
- 有效载荷长度(扩展首部+数据部分长度)(区分IPv4的首部字段长度和总(首部【包含固定部分和可变部分】+ 数据部分)字段长度)
- 下一个首部:标识下一个扩展首部或上层协议首部。(基本首部的下一个首部指向第一个扩展首部,第一个扩展首部的下一个首部指向第二个扩展首部,…第N-1个扩展首部的下一个首部指向第N个扩展首部)
- 跳数限制:相当于IPv4的TTL。
- 源地址和目的地址都是128位,大大扩展了。
区分IPv6 & IPv4
- IPv6将地址从32位(4B)扩大到128位(16B),更大的地址空间。
- IPv6将IPv4的校验和字段彻底移除,以减少每跳的处理时间。
- IPv6将IPv4的可选字段移出首部,变成了扩展首部,成为灵活的首部格式,路由器通常不对扩展首部进行检查,大大提高了路由器的处理效率。
- IPv6支持即插即用(即自动配置),不需要DHCP协议。
- IPv6首部必须是8B的整数倍,IPv4首部是4B的整数倍(首部长度的单位是4B(字节))。
- IPv6只能在主机处分片,IPv4可以在路由器和主机处分片。返回差错报告报文,这种报文采用ICMPv6:附加报文类型“分组过大”。
- IPv6支持资源的预分配,支持实时视像等要求,保证一定的带宽和时延应用。
- IPv6取消了协议字段,改成下一个首部字段。
- IPv6取消了总长度字段,改用有效载荷长度字段。
- IPv6取消了服务类型字段。
IPv6地址表现形式
- 一般形式冒号十六进制记法:4BF5:AA12:0216:FEBC:BA5F:039A:BE9A:2170
- 压缩形式:4BF5:0000:0000:0000:BA5F:039A:000A:2176→4BF5:0:0:0:BA5F:39A:A:21764BF5:0000:0000:0000:BA5F:039A:000A:2176 → 4BF5:0:0:0:BA5F:39A:A:21764BF5:0000:0000:0000:BA5F:039A:000A:2176→4BF5:0:0:0:BA5F:39A:A:2176。
- 零压缩:一连串连续的0可以被一对冒号取代。FF05:0:0:0:0:0:0:B3箭头FF05::B3FF05:0:0:0:0:0:0:B3 箭头FF05::B3FF05:0:0:0:0:0:0:B3箭头FF05::B3。双冒号表示法在一个地址中仅可出现一次。
IPv6基本地址类型
- 单播:单播就是传统的点对点通信。可做源地址和目的地址。
- 多播:多播是一点对多点的通信,分组被交付到一组计算机的每台计算机。可做目的地址。
- 任播:IPv6增加的一种类型。任播的目的站是一组计算机,但数据报在交付时只交付其中的一台计算机,通常是距离最近的一台计算机。可做目的地址。
IPv6向IPv4过渡的策略
- 双栈协议:在一台设备上同时装有IPv4和IPv6协议栈,那么这台设备既能和IPv4网络通信,又能和IPv6网络通信。如果这台设备是一个路由器,那么在路由器的不同接口上分别配置了IPv4地址和IPv6地址,并很可能分别连接了IPv4网络和IPv6网络;如果这台设备是一台计算机,那么它将同时拥有IPv4地址和IPv6地址,并且具备同时处理这两个协议地址的功能。
- 隧道技术:将整个IPv6数据报封装到 IPv4数据报的数据部分,使得IPv6数据报可以在IPv4网络的隧道中传输。
路由算法
路由算法分类
- 静态路由算法(非自适应路由算法):管理员手动配置路由信息(手工配置怎么走)
- 有点:简便、可靠,在负荷稳定、拓扑变化不大(不会有很多主机退出或者进入,相对稳定)的网络中运行效果很好,广泛用于高度安全性的军事网络和较小的商业网络。
- 缺点:路由更新慢,不适用大型网络。
- 动态路由算法(自适应路由算法):路由器间彼此交换信息,按照路由算法优化出路由表项。
- 优点:路由更新快,适用大型网络,及时响应链路费用或网络拓扑变化。算法
- 缺点复杂,增加网络负担。
动态路由算法再划分
- 全局性 链路状态路由算法 OSPF:所有路由器掌握完整的网络拓扑和链路费用信息。
- 分散性:距离向量路由算法 RIP:路由器只掌握物理相连的邻居及链路费用。
分层次的路由选择协议
为什么使用分层次的路由选择协议
- 因特网规模很大,每个单位为了让自己的路由协议不过于庞大。
- 许多单位不想让外界知道自己的路由选择协议,但还想连入因特网自治系统。
怎么解决:也就是把整个因特网划分成很多个小团体,这种小团体叫做自治系统。
- 自治系统:(Autonomous System,AS):单一技术管理下的一组路由器,这些路由器使用一种AS内部的路由选择协议和共同的度量来确定分组在该AS内的路由,同时还使用一种AS之间的路由选择协议来确定分组在AS之间的选择。
- 内部使用的协议外部不知道,透明的。
- 一个自治系统内的所有网络都由一个行政单位(如一家公司、一所大学、一个政府部门等)管辖,一个自治系统的所有路由器在本自治系统内都必须是连通的。
因特网把路由选择协议划分为两大类:(内部看不到外部,外部看不到内部)
- 内部网关协议IGP:一个AS内使用的RIP、OSPF
- 外部网关协议EGP:AS之间使用的BGP
(这三个协议后面会说 )
路由信息协议RIP
路由信息协议(Routing Information Protocol,RIP)是内部网关协议(IGP)中最先得到广泛应用的协议。
RIP是一种分布式的基于距离向量的路由选择协议,其最大的优点就是简单。要求网络中每一个路由器都维护从它到其他每一个目的网络的唯一最佳记录[记录在路由表里](即一组距离)
- 距离:“跳数”,即从源端口到目的端口所经过的路由器的个数,经过一个路由器跳数+1。特别的,从一路由器到直接连接的网络距离为1(直接交付)。RIP允许一条路由最多只包含15个路由器,因此距离为16表示网络不可达 → RIP适合校的互联网。
RIP协议是应用层协议,使用UDP传送数据!(端口520)。RIP选择的路径不一定是时间最短的,但一定是具有最少路由器的路径。因为它是根据最少跳数进行路径选择的。
RIP规定
- 网络中的每个路由器都要维护从它自身到其他每个目的网络的唯一最佳距离记录(因此这是一组距离,称为距离向量)。
- 距离也称为跳数(Hop Count),规定从一个路由器到直接连接网络的距离(跳数)为1。而每经过一个路由器,距离(跳数)加1。
- RIP认为好的路由就是它通过的路由器的数目少,即优先选择跳数少的路径。
- RIP允许一条路径最多只能包含15个路由器(即最多允许15跳)。因此距离等于16时,它表示网络不可达。可见RIP只适用于小型互联网。距离向量路由可能会出现环路的情况。规定路径上的最高跳数的目的是为了防止数据报不断循环在环路上,减少网络拥塞的可能性。
- RIP默认在任意两个使用RIP的路由器之间每30秒广播一次RIP路由更新信息,以便自动建立并维护路由表(动态维护)。
- 在RIP中不支持子网掩码的RIP广播。所以RIP中每个网络的子网掩码必须相同。但在新的RIP2中,支持变长子网掩码和CIDR。
RIP协议和谁交换?
- 仅和相邻路由器交换信息。(向邻居节点广播整个路由表)
多久交换一次?
- 每30秒交换一次路由信息,然后路由器根据新信息更新路由表。若超过180s没收到邻居路由器的通告,则判定邻居没了,并更新自己路由表。
交换什么?
- 路由器交换的信息是自己的路由表。
距离向量算法
每个路由表项目都有三个关键数据:<目的网络N,距离d,下一跳路由器地址X>。对于每个相邻路由器发送过来的RIP报文,执行如下步骤:
- 对地址为X的相邻路由器发来的RIP报文,先修改此报文中的所有项目:把**“下一跳”字段中的地址都改为X**,并把所有 “距离”字段的值都加1 。
- 对修改后的RIP报文中的每个项目,执行如下步骤:
- 当原来的路由表中没有目的网络N时,把该项目添加到路由表中。
- 当原来的路由表中有目的网络N,且下一跳路由器的地址是X时,用收到的项目替换原路由表中的项目。(以最新为准)[同一个目的同一个下一跳直接更新/取最新的]
- 当原来的路由表中有目的网络N,且下一跳路由器的地址不是X时,如果收到的项目中的距离d小于路由表中的距离,那么就用收到的项目替换原路由表中的项目;否则什么也不做。[同一个目的不同一下一跳取距离最小的,距离相等不管]
- 如果180秒(RIP默认超时时间为180秒)还没有收到相邻路由器的更新路由表,那么把此相邻路由器记为不可达路由器,即把距离设置为16(距离为16表示不可达)。
- 返回。
例子


RIP协议报文字段

优缺点
- RIP优点:实现简单、开销小、收敛过程较快。
- RIP缺点:好消息传得快,坏消息传的慢
上面这两句话什么意思呢?

比如这张图:初始的时候R1路由表记录<1,1,- >(目的地址为网络1,距离1,可以直接交付),R2路由表记录<1,2,R1>(目的地址为网络1,距离2,下一跳路由器为R1)。
但是当:网1出了故障并且R1接受到更新的路由表信息变为<1,16,->,并将路由表信息发送给了R2。但是R1会先接收来自R2的信息<1,3,R2>(这是修改后的了)(原始R2中的是<1,2,R1>),R1就会把路由表信息更新为<1,3,R2>,发送新的路由表信息给R2,R2接受到新路由表信息更新为<1,4,R1>,然后R2又给R1发,R1更新<1,5,R2>,两个路由表来回上述操作,最后直到最短距离变成16才能发现网络1到达不了,出故障了。这就是坏消息传的慢。
路由器之间交换的是路由器中的完整路由表,因此网络规模越大,开销也越大。
网络出现故障时,会出现慢收敛现象(即需要较长的时间才能将此信息传送到所有路由器,上面举的例子),俗称“坏消息传得慢”,使更新过程的收敛时间长。
开放最短路径优先 OSPF 协议
- "开放"表明OSPF协议不是受某一厂商控制,而是公开发表的。
- "最短路径优先"是因为使用了Dijkstra提出的最短路径算法SPF。
- OSPF最主要的特征就是使用分布式的链路状态协议。
特点
-
和谁交换:使用洪泛法向自治系统内所有路由器发送信息,即路由器通过输出端口向所有相邻的路由器发送信息,而每一个相邻路由器又再次将此信息发往其所有的相邻路由器。(广播)最终整个区域内所有路由器都得到了这个信息的一个副本。
----- 而RIP仅向自己相邻的几个路由器发送信息。 -
交换什么:发送的信息就是与本路由器相邻的所有路由器的链路状态(本路由器和哪些路由器相邻,以及该链路的度量/代价 —— 费用、距离、时延、带宽等)。
----- RIP发送的信息是本路由器所知道的全部信息,即整个路由表,路由表内的信息是距离向量,而OSPF的信息是度量/代价(自己定义,可以是费用,距离,时延…)。 -
多久交换:只有当链路状态发生变化时,路由器才向所有路由器洪泛发送此信息。收敛过程快,不会出现“坏消息传得慢”的问题。
----- 而RIP中,路由器之间会定期(30s)交换路由表的信息。
最终,所有路由器都能建立一个链路状态数据库,即全网拓扑图。
区别
- OSPF是网络层协议,不使用UDP或TCP,而直接用IP数据报传送(其IP数据报首部的协议字段为89)。而RIP是应用层协议,使用UDP。
- OSPF支持可变长度的子网划分和CIDR。
链路状态路由算法
- 每个路由器发现它的邻居结点【通过每10s发送HELLO问候分组】,并了解邻居节点的网络地址。
- 设置到它的每个邻居的成本度量metric。
- 构造【DD数据库描述分组】,向邻站给出自己的链路状态数据库中的所有链路状态项目的摘要信息。
- 如果DD分组中的摘要自己都有,则邻站不做处理,出现没有的或者是更新的,则发送【LSR链路状态请求分组】请求自己没有的和比自己更新的信息。
- 收到邻站的LSR分组后,发送【LSu链路状态更新分组】进行更新。
- 更新完毕后,邻站返回一个【LSAck链路状态确认分组】进行确认。
只要一个路由器的链路状态发生变化:
- 泛洪发送【LSu链路状态更新分组】进行更新。
- 更新完毕后,其他站返回一个【LSAck链路状态确认分组】进行确认。
- 使用Dijkstra根据自己的链路状态数据库构造到其他节点间的最短路径。
为了确保链路状态数据库与全网状态保持一致,OSPF规定每隔一段时间(30分钟)就刷新一次数据库中的链路状态。由于一个路由器的链路状态只涉及与相邻路由器的连通状态,因而与整个互联网的规模并无直接关系。当互联网规模很大时,OSPF要比RIP好得多。

OSPF的区域
为使OSPF能够用于规模很大的网络,OSPF将一个自治系统再划分为若干更小的范围,称为区域。
每个区域都有一个32位的区域标识符。
区域也不能太大,在一个区域内的路由器最好不超过200个。

处在上层的域称为主干区域,负责连通其他下层的区域,并且还连接其他自治域。
- 主干区域作用是联通下层区域。
- R3-R7(除了R6)是主干路由器。
- R3,R7既是主干路由器,又是区域边界路由器。
- R6是自治系统边界路由器,连接其他自治系统。
- 下层区域内的路由器叫做区域内部路由器,比如R1,R2…
划分区域的好处是,将利用洪泛法交换链路状态信息的范围局限于每个区域而非整个自治系统,减少了整个网络上的通信量。在一个区域内部的路由器只知道本区域的完整网络拓扑,而不知道其他区域的网络拓扑情况。
OSPF分组

OSPF是网络层协议,不使用UDP或TCP,而直接用IP数据报传送(其IP数据报首部的协议字段为89)。而RIP是应用层协议,使用UDP。
OSPF特点
- 每隔30min,要刷新一次数据库中的链路状态。(确保链路状态数据库与全网状态保持一致)
- 由于一个路由器的链路状态只涉及到与相邻路由器的连通状态,因而与整个互联网的规模并无直接关系。因此当互联网规模很大时,OSPF协议要比距离向量协议RIP好得多。
- OSPF不存在坏消息传的慢的问题,它的收敛速度很快(RIP收到一个路由信息(相邻路由路由表)先要和自己的路由表对照才能确认最短路径,而OSPF直接把手来的所有更新存入数据库,然后使用 Dijkstra算法获取最短路径)。
边界网关协议 BGP
边界网关协议(Border Gateway Protocol,BGP)是不同自治系统的路由器之间交换路由信息的协议,是一种外部网关协议。
- 和谁交换:与其他AS的邻站BGP发言人交换信息。
- 交换什么:交换的网络可达性的信息,即要到达某个网络所要经过的一系列AS。
- 多久交换:发生变化时更新有变化的部分。
BGP所交换的网络可导性的信息就是要到达某一个网络索要经过的一系列的AS(完整的路径,交换的是路径向量 )。 当BGP发言人(边界路由器,可以身兼多值【内部+外部】)互相交换了网络可达性的信息后,各BGP发言人就根据所采用的策略从收到的路由信息中找出到达各AS的较好路由。
每个 BGP发言人除必须运行BGP外,还必须运行该AS所用的内部网关协议,如 OSPF 或RIP。BGP所交换的网络可达性信息就是要到达某个网络(用网络前缀表示)所要经过的一系列AS。
BGP是应用层协议,它是基于TCP的。
BGP协议报文格式

一个BGP发言人与其他自治系统中的BGP发言人要交换路由信息,就要先建立TCP连接,即通过TCP传送,然后在此连接上交换BGP报文以建立BGP会话(session),利用BGP会话交换路由信息。
BGP工作原理
- 每个自治系统的管理员要选择至少一个路由器(可以有多个)作为该自治系统的“BGP发言人”。
- 一个BGP发言人与其他自治系统中的BGP发言人要交换路由信息,就要先建立TCP连接(BGP报文是TCP报文的数据部分),然后在此连接上交换BGP报文以建立 BGP会话,再利用BGP会话交换路由信息。
- 当所有 BGP发言人都相互交换网络可达性的信息后,各 BGP发言人就可找出到达各个自治系统的较好路由。
BGP特点
- BGP交换路由信息的结点数量级是自治系统(AS)的数量级,要比这些自治系统中的网络数少很多。
- 每个自治系统中 BGP发言人(或边界路由器)的数目是很少的。这样就使得自治系统之间的路由选择不致过分复杂。
- BGP支持 CIDR,因此BGP的路由表也就应当包括目的网络前缀、下一跳路由器,以及到达该目的网络所要经过的各个自治系统序列。
- 在BGP 刚运行时,BGP的邻站交换整个BGP 路由表,但以后只需在发生变化时更新有变化的部分。这样做对节省网络带宽和减少路由器的处理开销都有好处。
BGP-4共使用4种报文
- 打开(Open)报文:用来与相邻的另一个BGP发言人建立关系(连接),并认证发送方。
- 更新(Update)报文:只要路径有变化就通告。
- 保活(Keepalive)报文:用来确认打开报文并周期性地证实邻站连通性,也作为OPEN的确认
- 通知(Notification)报文:用来发送检测到的差错,也被用于关闭连接
三种协议比较
- RIP是一种分布式的基于距离向量的内部网关路由选择协议,通过广播UDP报文来交换路由信息。
- OSPF是一个内部网关协议,要交换的信息量较大,应使报文的长度尽量短,所以不使用传输层协议〈如UDP或TCP),而是直接采用IP。
- BGP是一个外部网关协议,在不同的自治系统之间交换路由信息(AS),由于网络环境复杂,需要保证可靠传输,所以采用TCP。

IP组播
IP数据报三种传输方式
- 单播:单播用于发送数据包到单个目的地,且每发送一份单播报文都使用一个单播IP地址作为目的地址。是一种 点对点传输方式。(一个数据要发送给n个接收方,就需要复制n份,并且在发送者和每一接收者之间需要单独的数据信道)
- 广播:广播是指发送数据包到同一广播域或子网内的所有备份的一种数据传输方式,是一种点对多点传输方式。(不管接收方需求,对一个广播域或子网内的全部主机都发送)
- 组播(多播):当网络中的某些用户需要特定数据时,组播数据发送者仅发送一次数据,借助组播路由协议为组播数据包建立组播分发树,被传递的数据到达距离用户端尽可能近的节点后才开始复制和分发(不会在源点复制,需要分路的时候才会开始复制。在复制之前,线路上传送的只有一个数据包),是一种点对多点传输方式。(管接收方的需求,只对有相同需求的组内主机进行发送)
- 组播提高了数据传送效率,减少了主干网出现拥塞的可能性。组播组中的主机可以是在同一个物理网络,也可以来自不同的物理网络(如果有组播路由器【进行组播协议的路由器】的支持)
IP组播地址
IP组播地址让源设备能够将分组发送给一组设备。属于多播组的设备将被分配一个组播组IP地址(一群共同需求主机的共同标识)。
IP组播使用D类地址格式。D类的前四位是1110,因此D类地址范围是 224.0.0.0 ~ 239.255.255.255。一个D类地址表示一个组播组。只能用作分组的目标地址。源地址总是为单播地址。
- 组播数据报也是“尽最大努力交付”,不提供可靠交付,组播一定仅应用于UDP。
- 组播地址只能用于目的地址,而不能用于源地址。
- 对组播数据报不产生ICMP差错报文。
- 并非所有的D类地址都可作为组播地址。
IP组播分为:
- 在局域网上进行硬件组播
- 在因特网范围内组播。
硬件组播
同单播地址一样,组播IP地址也需要相应的组播MAC地址在本地网络中实际传送帧。组播MAC地址以十六进制值 01-00-5E 打头,接着最高位0也是固定的。余下的6个十六进制位是根据IP组播地址的最后23位转换得到的。
TCP/IP 协议使用的以太网多播地址的范围是:从 01-00-5E-00-00-00 到 01-00-5E-7F-FF-FF。

由于组播IP地址与以太网硬件地址的映射关系不是唯一的(组播IP地址不同,但是映射只是存在于两类地址的后23位,因此D类地址不固定的中间五位就会有多种对应的组播组,也就是多个组播组可能会对应映射到同一个MAC地址!),因此收到组播数据报的主机,还要在IP层利用软件进行过滤,把不是本主机要接收的数据包丢弃。
网际组管理协议IGMP
IGMP和ICMP都使用IP数据报传递报文。
网际 (因特网) 组管理协议(Internet Group Management Protocol,IGMP):IGMP协议让路由器知道本局域网上是否有主机(的进程)参加或退出了某个组播组。
IGMP工作的两个阶段:
- ROUND 1:
- 某主机要加入组播组时,该**主机向组播组的组播地址(路由器和同属于这个组播组的成员都收得到)**发送一个IGMP报文,声明自己要称为该组的成员。
- 本地组播路由器收到lGMP报文后,要利用组播路由选择协议把这组成员关系发给因特网上的其他组播路由器。
- ROUND 2:
- 本地组播路由器周期性探询本地局域网上的主机,以便知道这些主机是否还是组播组的成员。
- 只要有一个主机对某个组响应,那么组播路由器就认为这个组是活跃的;如果经过几次探询后没有一个主机响应,组播路由器就认为本网络上的没有此组播组的主机,因此就不再把这组的成员关系发给其他的组播路由器。(组播路由器知道的成员关系只是所连接的局域网内有无组播组成员,至于成员数量是无法知道的)
组播路由选择协议
组播路由选择目的就是要找出以源主机为根节点的组播转发树。(选转发路径)
其中每个分组在每条链路上只传送一次。不同的多播组对应于不同的多播转发树:同一个多播组,对不同的源点也会有不同的多播转发树。
常用的三种算法:
- 基于链路状态的路由选择
- 基于距离-向量的路由选择
- 协议无关的组播(稀疏/密集)【可以建立在任何路由器协议之上】
移动IP
相关术语
移动IP技术是移动结点(计算机/服务器等)以固定的网络IP地址,实现跨越不同网段的漫游功能,并保证了基于网络IP的网络权限在漫游过程中不发生任何改变。
- 移动结点:具有永久IP地址的移动设备。
- 归属代理(本地代理):一个移动结点拥有的就“居所”称为归属网络,在归属网络中代表移动节点执行移动管理功能的实体叫做归属代理。(可以是路由器可以是主机)
- 外部代理(外地代理):在外部网络中帮助移动节点完成移动管理功能的实体称为外部代理。(移动节点移动到非归属网络时帮它完成移动管理的实体叫做外部代理)
- 永久地址(归属地址/主地址):移动站点在归属网络中的原始地址(固定的IP地址)。
- 转交地址(辅地址):移动站点在外部网络使用的临时地址。
移动IP通信过程
- 关于数据发送: B向主机A发送数据,如果A在归属网络内直接接受数据就行,如果不在,数据被由本地代理截获,本地代理再封装数据包,新的目的地址是转交地址。(初始数据报的目的地址是归属网络内的主地址)

网络层设备
路由器
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是连接异构网络并完成路由转发。
内部结构组成:
- 路由选择:根据所选定的路由选择协议构造出路由表,同时经常或定期和相邻路由器交换路由信息而不断地更新和维护路由表。
- 分组转发:根据转发表(路由表得来)对分组进行转发。由三部分组成,交换结构、一组输入端口、一组输出端口。
- 区分一下:路由选择就是找路由走的路径,转发是路由器内部走哪个端口。
- 不是所有有输入端口进入的分组都进行转发处理。若收到EIP/OSPF(路由信息)分组等,则把分组交由路由选择处理机,若收到的是数据分组,则查找转发表进行转发输出。

- 不是所有有输入端口进入的分组都进行转发处理。若收到EIP/OSPF(路由信息)分组等,则把分组交由路由选择处理机,若收到的是数据分组,则查找转发表进行转发输出。
处理过程:

-
物理层只是进行比特的接收。
-
到达链路层,链路层按照传输分组的协议接收传输分组的帧。
-
帧的头和尾去掉,交给网络层,网络层先判断是路由信息还是数据分组,前者的话交给路由选择处理机进行处理计算,后者进行分组处理,执行转发输出。
- 很多分组的话需要排队,容易产生时延。(输入端口中的查找和转发功能再路由器的交换功能中最重要)

- 很多分组的话需要排队,容易产生时延。(输入端口中的查找和转发功能再路由器的交换功能中最重要)
-
输出端口先有交换结构接收到一个输出分组,后面就和输入的倒过来。
-
如果路由器处理分组的速率赶不上分组进入队列的速率,则队列的存储空间最终必定减少到0,这就使得后面再进入队列的分组由于没有存储空间而只能被丢弃。(路由器中的输入或输出队列产生溢出是造成分组丢失的重要原因)
三层设备的区别
- 路由器可以互联两个不同网络层协议的网段。
- 网桥可以互联两个物理层和链路层不同的网段。
- 集线器不能互联两个物理层不同的网段。
对于任何层次的设备都可以互联它所在的层次和以下层次的网段(×,比如集线器)

路由表与路由转发
- 路由表根据路由选择算法得出的,主要用途是路由选择。总是用软件来实现!
- 路由表有4个项目:目的网络IP地址、子网掩码、下一跳IP地址、接口。
- 一般会包含一个默认路由<0.0.0.0,0.0.0.0,,>
- 转发表从路由表得出的。可以用软件来实现,甚至也可以用特殊的硬件来实现!
- 转发表有2个项目:分组将要发往的目的地址、分组的下一跳(即下一步接收者的目的地址,实际为MAC地址。
转发和路由选择的区别:
- 转发是路由器根据转发表把收到的IP数据报从合适的端口转发出去,它仅涉及一个路由器。
- 路由选择 则涉及很多路由器,路由表是许多路由器协同工作的结果。这些路由器按照复杂的路由算法,根据从各相邻路由器得到的关于网络拓扑的变化情况,动态地改变所选择的路由,并由此构造出整个路由表。
第五章 传输层
阐述层概述
(主机才有的层次)
传输层的功能
-
传输层提供进程和进程之间的逻辑通信。(网络层提供主机之间的通信)
逻辑通信:传输层之间的通信好像是沿着水平方向传送数据,但事实上这两个传输层之间并没有一条水平方向的物理连接。(先通过网络层实现主机通信,主机在将信息交给对应的进程/线程) -
复用和分用。
复用是指发送方不同的应用进程都可以使用同一个传输层协议传送数据;分用是指接收方的传输层在剥去报文的首部后能够把这些数据正确交付到目的应用进程。
复用:应用层所有的应用进程都可以通过传输层再传输到网络层。
分用:传输层从网络层收到数据后交付指明的应用进程。 -
传输层对收到的报文进行差错检测(首部和数据部分)。【网络层只检查IP数据报的首部,不检验数据部分是否出错】。
-
提供两种不同的传输协议,即面向连接的TCP和无连接的UDP。【网络层无法同时实现两种协议】。
TCP & UDP
-
面向连接的传输控制协议TCP
传送数据之前必须建立连接,数据传送结束后要释放连接。不提供广播或多播服务。由于TCP要提供可靠的面向连接的传输服务,因此不可避免增加了许多开销:回复确认、流量控制、计时器及连接管理等。
可靠,面向连接,时延大,适用于大文件。比如QQ传输大文件。 -
无连接的用户数据报协议UDP
传送数据之前不需要建立连接,收到UDP报文后也不需要给出任何确认。
不可靠,无连接,时延小,适用于小文件。比如QQ发送一条消息。
传输层的寻址与端口
- 复用:应用层所有的应用进程都可以通过传输层再传输给网络层。类比一家人使用一个信箱。
- 分用:传输层从网络层收到数据后交付指明的应用进程。类比每个人收到属于自己的信。
怎么实现上面的功能 ?
- 端口(逻辑端口/软件端口):传输层的服务访问点(SAP),标识主机中的应用进程。端口号只有本地意义,在因特网中不同计算机的相同端口是没有联系的。
- 端口号长度为16bit,能标识65536个不同的端口号。
- 端口号分类(按范围分类)
- 服务端使用的端口号
- 熟知端口号:给TCP/IP最重要的一些应用程序,让所有用户都知道的。(固定确认的)0~1023。
- 登记端口号:为没有熟知端口号的应用程序使用的。1024~49151.
- 客户端使用的端口号(主机使用的):仅在客户进程运行时才动态选择的。(只有使用才分配,随机分片)49151~65535。
- 服务端使用的端口号
常见的应用程序与对应的端口号

在网络中采用发送方和接收方的套接字组合来识别端点,套接字【套接字Socket = (主机IP地址,端口号)】唯一标识了网络中的一个主机和它上面的一个进程(通信的端点)。
UDP协议
UDP只在IP数据报服务之上增加了很少功能,即复用分用和差错检测功能。
UDP的主要特点
- UDP是无连接的,减少开销和发送数据之前的时延。
- UDP使用最大努力交付,即不保证可靠交付。
- UDP是面向报文的,适合一次性传输少量数据的网络应用。
- 对应用层传下来的报文不做拆分或者合并,不改变报文的长度。应用层给UDP多长的报文,UDP就照样发生,即一次发一个完整报文。
- UDP无拥塞控制,适合很多实时应用。
- UDP首部开销小,8B,TCP是20B。
UDP首部格式

- 伪首部(类比首部)
- 源IP地址和目的IP地址类比IP数据报的。
- 0表示全0,固定好的。
- 17是IP数据包的协议字段,数据部分用的是什么字段,UDP对应的字段值就是17。
- UDP长度:UDP首部8B+数据部分长度(不包括伪首部)
- 伪首部只有在计算校验和时出现,不想下传送也不向上递交。
- 源端口号可有可无,如果不需要收到确认回复可以填写全0.
- 目的端口号必须有
- UDP长度是数据报整个长度
- UDP检验和:检验整个UDP数据报是否有错,错就丢弃。
- 分用时,如果找不到对应的目的端口号,就丢弃报文,并给发送方发送ICMP“端口不可达”的差错报告报文。
用伪首部进行UDP校验
在计算校验和时,要在UDP数据报之前增加12B的伪首部,伪首部并不是UDP的真正首部。只是在计算校验和时,临时添加在UDP数据报的前面,得到一个临时的UDP数据报。

在发送端:
- 添上伪首部。
- 全0填充校验和字段。
- 全0填充数据部分。(UDP数据部分必须得是2B的整数倍,不满足的地方用全0填充,比如上图数据是7B,要填充1B满足8B,因为求检验和的时候是2B,2B(16位)分开求和计算的)
- 伪首部 + 首部 + 数据部分 采用二进制反码求和。
- 把和求反码填入校验和字段。
- 去掉伪首部,发送。
在接收端:
- 添上伪首部。
- 伪首部 + 首部 + 数据部分 采用二进制反码求和。
- 结果全为1则无差错,否则丢弃数据报/交给应用层附上出错的警告。
TCP协议
TCP协议的特点
- TCP是面向连接(虚连接)的传输层协议。得先建立连接才可以传输。
- 每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的。(不可以用于广播和多播)
- TCP提供可靠交付的服务,无差错、不丢失、不重复、按序到达。(可靠有序,不丢不重)
- TCP提供全双工通信。允许通信双方的应用进程在任何时候都能发送数据,为此两个链段都设有发送缓存和接收缓存。
- 发送缓存:准备发送的数据 & 已发送但尚未收到确认的数据(TCP发送数据要返回确认信息)。
- 接收缓存:按序到达但尚未被接受应用程序读取的数据 & 不按序到达的数据。
- TCP面向字节流:TCP把应用程序交下来的数据看成仅仅是一连串的无结构的字节流。
TCP报文段首部格式

-
20字节(20B)的固定首部。
-
填充字段是保证TCP首部是4字节的整数倍。
-
源端口目的端口都是16位。
-
序号seq:在一个TCP连接中传送的字节流中的每一个字节都按顺序编号,本字段表示本报文段所发送数据的第一个字节的序号。
-
确认号ack:期望收到对方下一个报文段的第一个数据字节的序号。若确认号为 N,则证明到序号 N - 1 为止的所有数据都已正确收到。
-
数据偏移(首部长度):TCP报文段的数据起始处距离TCP报文段的起始处有多远,以4B为单位。
- 如果数据偏移是1111(15),那么就表示首部长度为15 × 4 = 60B。
-
控制位(六个,每个控制位占1bit(位)):
- 紧急位 URG:URG = 1时,标明此报文段中有紧急数据,是高优先级的数据,应尽快传送,不用在缓存里排队,配合紧急指针字段使用。(发送端紧急发送)
- 确认位 ACK:ACK = 1时确认号才有效,为0无意义。在连接建立后所有传送的报文段都必须把ACK置为1。
- 推送位 PSH:PSH = 1时,接收方尽快交付接收应用进程,不再等到缓存填满再向上交付。(接收端尽快处理)
- 复位 RST:RST = 1时,表明TCP连接中出现严重差错,必须释放连接,然后再重新建立传输连接。
- 同步位 SYN:SYN = 1时,表明是一个连接请求/连接接受报文。
- 终止位 FIN:FIN = 1时,表明此报文段发送方数据已发完,要求释放连接。
-
窗口:指的是发送本报文段的一方的接收窗口(自己可以容纳的字节流),即现在允许对方发送的数据量。0~216 - 1(根据对方发来的接受窗口大小,发送方设置发送缓冲/发送窗口)。
-
检验和:检验首部 + 数据,检验时要加上12B伪首部,UDP第四个字段是17,TCP是6。
-
紧急指针:URG = 1时才有意义,指出本报文段中紧急数据的字节数。
-
选项:最大报文段长度MSS、窗口扩大、时间戳、选择确认 ……
-
填充:如果选项不是四字节的整数倍就填充满足四字节整数倍的要求。
TCP连接管理
TCP连接传输三个阶段:连接建立 — 数据传送 — 连接释放
TCP的连接建立
TCP连接建立采用客户服务器方式,主动发起连接建立的应用进程叫做客户,而被动等待连接建立的应用进程叫服务器。

-
客户端发送连接请求报文段,无应用层数据。
SYN = 1,seq = x- SYN:同步位,只在连接请求和连接请求的确认为1
- seq:标识本次报文段的序号(x是发送方发送的首条报文段的序号,一般随机)
-
服务器端为该TCP连接分配缓存和变量,并向客户端返回确认报文段,允许连接,无应用层数据。
SYN = 1,ACK = 1,seq = y(随机),ack = x + 1(客户端发送的seq是x,因此我期望收到的下一个序号就是x+1)- ACK:确认位,用于回复,确认对方的报文已经收到(由于第一步连接请求无需确认,因此ACK=0)
- ack:其实就是确认号,表示下一次期望收到的序号(因为请求连接的报文无数据部分,序号为x,所以ack = x + 1)。ACK和ack是组合使用,共同生效。
- y是接收方发送的首条报文段的序号,一般随机
-
客户端为该TCP连接分配缓存和变量,并向服务器返回确认的确认,表示发送方可以发送携带数据的报文了。
SYN = 0,ACK = 1,seq = x + 1(客户端第一次发送即第一步时定义的序号是seq=x,因此下一次发送按序就是seq=x+1),ack = y + 1- SYN = 0,只有在前两步才是1,其他都是0.
- 上一条报文段序号是y,那么期待下一条报文段的序号就是y + 1,所以ack = y + 1
- 因为发送方之前已经发送了seq = x的报文段,所以下一条报文段的序号为x + 1,即seq = x + 1。TCP 是面向字节流的,通过 TCP 传送的字节流中的每个字节都按顺序编号,而报头中的序号字段值则指的是本报文段数据的第一个字节的序号。发送方发送的请求链接报文是没有数据的,
SYN洪泛攻击
SYN洪泛攻击发生在OSl第四层,这种方式利用TCP协议的特性,就是三次握手。攻击者发送TCP SYN,SYN是TCP三次握手中的第一个数据包(请求连接),而当服务器返回ACK后,该攻击者就不对其进行再确认,那这个TCP连接就处于挂起状态,也就是所谓的半连接状态,服务器收不到再确认的话,还会重复发送ACK给攻击者。这样更加会浪费服务器的资源。攻击者就对服务器发送非常大量的这种TCP连接,由于每一个都没法完成三次握手,所以在服务器上,这些TCP连接会因为挂起状态而消耗CPU和内存,最后服务器可能死机,就无法为正常用户提供服务了。
TCP连接释放
参与一条TCP连接的两个进程中的任何一个都能终止该连接,连接结束后,主机中的缓存和变量将被释放。

-
客户端发送连接释放报文段,停止发送数据,主动关闭TCP连接。(无需确认位ACK此时=0)
FIN = 1,seq = u(u其实等于客户端发送的最后一个报文段序号+1)- FIN:终止位,表示数据发送完毕,只有在服务器或客户端发送完数据后才会将该终止位置为1,请求释放连接的报文FIN设为1。
- FIN:终止位,表示数据发送完毕,只有在服务器或客户端发送完数据后才会将该终止位置为1,请求释放连接的报文FIN设为1。
-
服务器端回送一个确认报文段,客户到服务器这个方向的连接就释放了 —— 半关闭状态。(客户端停止发送了,服务器端仍可以发送)
ACK = 1,seq = v(v其实等于服务器发送的最后一个报文段序号+1),ack = u + 1(上一步的报文seq=u,因此期待的下一个报文段序号就是u+1) -
服务器发完数据,就发出连接释放报文段,主动关闭TCP连接。
FIN = 1,ACK = 1,seq = w(w其实等于服务器发送的最后一个报文段序号+1),ack = u + 1(上一步的报文seq=u,中间客户没有发送报文,因此期待的下一个报文段序号就是u+1) -
客户端回送一个确认报文段,再等到时间等待计时器设置的 2MSL(最长报文段寿命,防止客户端发送的确认报文段丢失,服务器就会重传连接释放报文段,然后客户端再次发送确认,同时重新启动2MSL计时器 | 如果没有这个机制,A发送完确认报文段直接关闭不等待,A发送给B的确认报文段又丢失,A没法收到B重传的连接释放报文段,B也收不到确认报文段,没法正常关闭)后,连接彻底关闭。
ACK = 1,seq = u + 1(u+1就是客户端第一次发送的序号seq=u的下一个序号),ack = w + 1(服务器上一步发送的seq=w,期待服务器的下一个报文序号是w+1)
TCP可靠传输
网络层提供尽最大努力交付,是不可靠传输。所以网络层的上层传输层就担负起了可靠传输的职能。
- 如果网络层用的TCP就可以实现可靠传输。
- 如果使用的UDP就还得交给上层应用层实现可靠传输。
可靠:保证接收方进程从缓存区读出的字节流与发送方发出的字节流是完全一样的。(按序不丢失)
TCP 实现可靠传输的机制:
- 校验:与UDP校验一样,增加伪首部,使用二进制反码求和
- 序号:一个字节占一个序号,序号字段指一个报文段的第一个字节序号
- 确认:默认使用累积确认,发送方有TCP缓存,只有接收方收到数据并返回确认才会把数据从缓存中去除。接收方发送的ack为连续的最大序号(实现超时重传)。
- 重传:确认重传不分家,TCP的发送方在规定的时间内没有收到确认就要重传已发送的报文段。超时重传。
超时重传的时间
- TCP采用自适应算法,动态改变重传时间RTTs(加权平均往返时间)。对于每个报文段发送和收到确认的时间(RTT:往返时间)进行加权计算,动态更新。
超时等待时间有点久,如果在超时之前知道数据报是否丢失(超时时间内)
冗余ACK(冗余确认)
- 每当比期望序号大的失序报文段到达时,发送一个冗余ACK,指明下一个期待字节的序号。
ex:
- 发送方
- 发送1,2,3,4,5报文段
- 接收方
- 接收方收到1,返回给1的确认(确认号为2的第一个字节)
- 接收方收到3,仍返回给1的确认(所以确认号仍然为2的第一个字节)
- 接收方收到4,仍返回给1的确认(确认号为2的第一个字节)
- 接收方收到5,仍返回给1的确认(确认号为2的第一个字节)
- 发送方收到3个对于报文段1的冗余ACK→认为2报文段丢失,重传2号报文段(快速重传)
TCP流量控制
流量控制:让发送方慢点,要让接收方来得及接收。
TCP利用滑动窗口机制实现流量控制。
在通信过程中,接收方根据自己接收缓存的大小,动态地调整发送方的发送窗口大小,即接收窗口 rwnd(接收方设置确认报文段的 窗口字段 来将 rwnd 通知给发送方),发送方的发送窗口取接收窗口 rwnd 和拥塞窗口 cwnd 的最小值。
发送窗口大小可以动态变化。
举例

防止报文丢失
当接收窗口rwnd为0,发送方就会陷入等待,直到接收方通知rwnd不为0,但是如果接收方返回通知rwnd不为0的报文段丢失,接收方仍然无法发送数据,持续等待,进入死锁状态。所以:TCP为每一个连接设有一个持续计时器,只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口探测报文段(只有1B数据)。接收方收到探测报文段时给出的现在的窗口值,若窗口仍然是0,那么发送方就重新设置持续计时器。
TCP拥塞控制
出现拥塞的条件:对资源的需求总和大于可用资源。
拥塞控制目的:防止过多的数据注入到网络中(全局性)。
区别流量控制和拥塞控制:
- 流量控制是点对点的。
- 拥塞控制是全局性问题
拥塞控制四种算法
- 慢开始
- 拥塞避免
- 快重传
- 快恢复
先假设
- 数据单方向传送,而另一个方向只传送确认。
- 接收方总是有足够大的缓存空间,因而发送窗口取决于拥塞程度(这是假设)。
实际上:发送窗口 = Min{接收窗口 rwnd,拥塞窗口 cwnd}- 接收窗口:接收方根据接受缓存设置的值,并告知给发送方,反映接收方容量。
- 拥塞窗口: 发送方根据自己估算的网络拥塞程度而设置的窗口值,反映网络当前容量。
慢开始和拥塞避免

- 为了讨论方便:初始值cwnd默认设置为1(一个报文段,长队是最大报文段的长度MSS)。
- 一个传输轮次:发送一批报文段并收到他们的确认的时间(一个往返时延RTT)。
- 慢开始是指数增长:1,2,4,8,16…
- 到达ssthresh:16【慢开始门限】,报文段的增加由指数增长变成线性增长,每次+1。
- 等到达24的时候,发送方检测到出现拥塞现象,所以由24降到1,继续指向慢开始算法。
- 新一轮的慢开始门限值变为上一轮出现网络拥塞的窗口值【24】的一半【12】。
快重传和快恢复

- 快重传:只要收到三个重复的确认(ACK:期待收到下一个序号为x的报文段)冗余就立即重传。
- 快重传后直接就执行快恢复。
- 和拥塞避免的区别,前者是立即降到1后执行慢开始算法,而快恢复是降到新的门限值【上一轮出现网络拥塞的窗口值的一半,比如24->12】,然后执行快恢复:+1。
第六章
emmm为什么没有第六章呢,因为提前放假了然后就没有然后了(没补
上一篇:Nginx支持quic协议
下一篇:为「IT女神勋章」而战