AAAI2023 | VBLC:恶劣条件下针对领域自适应语义分割的可见度增强和逻辑值约束...
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!


李明嘉:
北京理工大学硕士研究生,目前研究方向为迁移学习、语义分割。
内容简介:
在实际系统中,要求将在正常视觉条件下训练的模型推广到不利条件下的目标域。一种普遍的解决方案是弥补清晰和不利条件图像之间的域差距,以便对目标做出令人满意的预测。然而,以前的方法通常依赖于从正常条件下拍摄的相同场景的参考图像,这在现实中很难收集到。此外,它们大多主要关注夜间或大雾等个别不利条件,削弱了模型在遇到其他不利天气时的通用性。为了克服上述限制,我们提出了一个新的框架,即可见度增强和逻辑值约束(VBLC),为恶劣天气下的场景量身定制。VBLC探索了摆脱参考图像并同时解决不利条件混合的潜力。具体来说,我们首先提出了可见度增强模块,通过图像级别的某些先验来动态改进目标图像。然后,我们找出了自训练方法的传统交叉熵损失中过度自信的缺点,并设计了逻辑值约束学习,它在训练期间对逻辑值输出施加约束来缓解这个问题。据我们所知,这是解决这一具有挑战性任务的新视角。通过在两个正常条件到不利条件域自适应基准任务上的广泛实验,即Cityscapes→ACDC和Cityscapes→FoggyCityscapes+RainCityscapes,验证了VBLC的有效性。
Introduction
01
Background
当前已经有不少工作针对语义分割这类基础视觉任务进行了深入探索,但它们中大多数工作都是围绕着由干净图片或者说是晴天时获取到的图片所构成数据集来进行的。这使得这些方法所训练出的模型在投入到像自动驾驶这类天气变化多样的场景中时,会变得相对脆弱。同时我们也知道针对目标场景重新进行标注和训练是非常昂贵的。甚至在某些场景下,比如说在夜晚,由于技术能力和人眼能力的限制,提供准确标注可能是相当困难的。因此为了构建一种可靠的感知系统,一种可行方案是把在干净图片上训练得到的模型迁移到恶劣天界场景中去。

02
Normal-to-Adverse Domain
Adaptation
领域自适应作为一种迁移学习方法,它能够将带标签的源域上所训练得到的知识迁移到一个无标签的目标域中去。领域自适应方法的核心在于减小源域和目标域之间的领域差异。为了迁移知识到一个恶劣天气的场景中,一种常见做法是使用图片的地理位置信息,来构建晴天和恶劣天气下图片对。这种方式可以提供弱监督信号,但是成对的图片收集和标注也是需要大量人力物力来进行支持的。

03
Poor Visibility Image Enhancement
如果我们要在领域自适应任务中避免成对图像的使用,就需要借助恶劣天气下的图像自身来提供更多信息,以此来减小领域差异。先前研究已经对于各种天气场景下成像原理提出了相应的物理模型。这些物理模型可以对不同天气场景下的图像进行可见度的增强,从而在图像层面上就减小了领域的差异。

04
Multi-Target Domain
Adaptation/Generalization
但是由于恶劣天气具有一定的复杂性,泛化到多个目标域上也是一个相关的问题。在多目标域的领域自适应任务中,我们需要从一个单一的源域场景中获取知识,并且保证在多目标域上同时取得良好的泛化性能。先前对于恶劣天气下领域自适应的研究,大多都只聚焦于同一种恶劣天气场景,比如说只聚焦夜晚或只聚焦于雾天。但是在实际场景中,恶劣天气可能是多种天气现象叠加的结果,因此我们认为更加合理的做法是将多种恶劣天气看作是一个具有更大多样性的目标域,也就是一种混合了多种恶劣天气场景的目标域。

Motivation
接下来我们对这篇工作的研究动机进行一下梳理。
01
Reduce Constraints
在这篇工作中我们针对从干净图像到恶劣天气下图像的领域自适应任务进行研究,这一任务通常被叫做Normal-to-Adverse Domain Adaptation。但是和之前的工作相比,我们尝试减少两条约束:首先,我们去除了源域和目标域图像之间基于地理位置信息匹配的关系,这能够在很大程度上缓解训练数据收集的压力,也能够提高数据的利用率;其次我们仅使用一个模型就能够处理多种恶劣天气的场景,这和之前使用单独的专家模型来处理各种天气就有很大不同,使得模型部署能够更加贴近于实际场景。

02
Visibility Boost Module
但是在我们实验中,由于全对图片所提供的弱监督信号不复存在,我们将面临更大的领域差异的问题。为了减小领域差异,我们使用物理模型来对目标域图像进行可见度的增强。原始的物理模型是针对各种天气现象所定制的,但是为了同时应对多种天气场景,我们将物理模型进行了一定程度的修改,使它能够根据图像本身状态来进行动态增强,最终结合这两点我们提出了可见度增强模块,即Visibility Boost Module。这个模块可以动态减小领域差异,提供统一的解决方案。尽管可见度增强模块已经能够在一定程度上减小领域差异,但是增强后的目标域图像和源域图像之间仍具有相当大的差距。
03
Logit-Constraint Learning
为了进一步应对在领域差异较大时,采用自训练方式常常出现overconfidence这一问题,我们进一步提出了Logit-Constant Learning,也就是逻辑值约束的学习策略。
以上就是我们整体的研究动机。
Visibility Boosting and Logit-Constraint Learning - VBLC
在接下来一部分中我们将介绍本工作中的具体方法,也就是VBLC。
01
Normal-to-Adverse Domain Adaption
我们首先需要形式化定义将要解决的问题。在Normal-to-Adverse Domain Adaptation中,我们具有一个带标签的源域,这源域中全都是由晴天或者干净图像所构成的。还有一个无标签的目标域,在这个目标域中全都是一些恶劣天气下收集到的图像。源域和目标域有着不同的数据分布,并且我们额外假定这两个域之间没有任何图像级别的对应关系。我们的总体目标是训练出一个神经网络Φ,使得这个神经网络Φ能够在目标域上取得良好的泛化性能。
02
Atmosphere Scatter Model (ASM)
可见度增强模块是基于大气散射模型,也就是此处的Atmosphere Scatter Model (ASM)。这个模型它最早是为了刻画雾的形成而提出的,但它实际上可以更加广泛地用于描述veiling effect这一由于大气散射而造成的现象。veiling effect它在雨天、雾天甚至在雪天都是很常见的现象,所以我们总结并认为它是造成可见度下降的一个重要的因素。在大气散射模型中,一个非常重要的点是关于,也就是transmission map的一个合理估计。

先前的工作中,研究者多数采用了固定的估计方式,但是这种方式会使得增强后的图像变得不再自然。为此我们在估计公式中加入一个动态的,也就是自适应的参数ωs来调整增强的程度。在我们方法中,ωs是通过单张图像的饱和度均值来进行计算,所以这一估计方式能够很自然地应用到各种不同的天气场景中。

03
Visibility Boost Module (VBM)
对于夜间图像,我们的处理方式有些许不同。先前研究发现将夜间图像进行数值上的反转,能够在上面观察到类似于雾天图像的现象,为此我们为夜间图像专门设计了一次反转,来实现对夜间图像额外的一种增强。至此我们的可见度增强模块已经能够以一种统一的方式来应对多种恶劣天气条件下的图像,并对他们进行适当的增强。

04
Logit-Constraint Learning (LCL)
我们进一步来看逻辑值约束学习。逻辑值约束学习的提出是为了进一步处理领域差异产生的问题,正如前面所说可见度增强模块,虽然能够在输入空间中减小领域差异,但是增强后的图像由于本身有一些恶劣天气细节上的问题,导致它和源域的干净图像之间仍有不小的领域差异。这种差异在我们应用自训练策略时会引入错误的伪标签,从而导致模型过拟合到错误的预测上去,而逻辑值约束学习就是为这一现象所提出的。

首先我们来观察在自训练方法中常使用的交叉熵损失函数。假定有K个类别,у是独热编码标签,Ρ是模型预测,它是由模型输出的逻辑值经过softmax操作之后得到的:

如果у标签给定了j第个类别,那么我们可以计算出损失函数对于Zj的梯度:

这一梯度相当简单,它告诉我们:如果标签给定的类别j对于样本来说是错误的,那么使用交叉熵损失函数所训练出的模型,将不可避免地过拟合到错误的标签上去。
为了缓解这一问题,我们提出了逻辑值约束学习。在这个损失函数中,我们对逻辑值进行了规划操作。此时如果我们再次求解损失函数对于Zj的梯度,我们可以发现这个梯度变成下面的形式:

需要注意的是,这里的j仍然是у标签所给定的。在这个式子中梯度由两项构成:第一项与交叉熵损失函数中的相当类似,而第二项中的求和项则是我们解决overconfidence问题的关键。第一种情况,如果模型对于第j类的预测有较高的置信度,那么整个求和项中除了第j类,其他项的系数都会相对较小,于是我们就可以将它近似写成下面的形式,在这种形式下模型将继续巩固对于第j类的预测。

而在第二种情况下,如果模型对于样本的预测较为不置信,那么整个形式将会保持下面的形式,在这个求和项中会出现一些系数较大的项,这些项也就是模型犹豫的一些类别,整个梯度会减去这些项对应的梯度,使得模型将不会很容易地过拟合到第j类上,而会根据模型对于样本的整体的预测置信程度,来对优化过程进行一定程度上的减缓。

通过上述分析可以发现我们提出的逻辑值约束学习方法可以在理论上缓解overconfidence这一问题。
05
Framework
下图展示了我们方法的一个整体框架。首先我们有目标域图像和源域图像,目标域图像通过可见度增强模块可以得到增强目标域图像,在这里形成两组图像对,也就是源域和目标域图像以及源域和增强目标域图像,这两组图像对都会经过class-mix的数据增强,以及使用我们所提出的逻辑值约束学习的策略来进行训练。我们同时还采用了student-teacher这一架构,使得整个训练过程更加稳定。值得一提的是,由于目标域的图像也参与了训练,所以在测试环节就不再需要可见度增强模块。

06
Overall Objective
这是整个方法中的3个损失函数:源域、源域和目标域进行class-mix还有源域和增强后目标域进行class-mix的三种损失函数。

这里为了更好平衡这3个损失函数,我们对所有涉及到目标域图像的损失函数,都使用模型对它们预测的置信程度进行加权。在整个实验过程中,3种图像都使用了我们所提出的逻辑值约束方法进行训练。我们提出方法中训练的一个总体目标,就是下面提出的3种损失函数的加总。

07
Algorithm
我们所提方法中算法的一个整体阐述,如下图所示:

Experiments
下面我们进一步展示实验结果和相应的实验分析。
01
Cityscapes→ACDC
在第一个实验中,我们将VBLC方法和之前一些方法在Cityscapes到ACDC这样一个领域自适应语义分割的数据集任务上进行比较。这两个数据集都是在现实中进行收集的,所以他们就有较大的难度。在这一任务上我们的方法展现出了优越性能。

02
Cityscapes→FoggyCityscapes
+RainCityscapes
我们也在合成数据集上进行了进一步的实验,这个实验它是从Cityscapes数据集迁移到FoggyCityscapes+RainCityscapes这两个合成数据集所混合而成的一个新的数据集。在这个数据集的任务上,我们的VBLC方法也展现出了较好的技能。

03
Object Detection & Multi-Target
Domain Adaptive Segmentation
为了进一步展现VBLC方法的灵活性,我们也在目标检测以及多个目标域的领域自适应语义分割任务上进行实验。虽然我们的VBLC方法并不是为这些任务所量身打造的,但是它仍旧在这些任务上取得了良好的性能增益。

04
Ablation Study on Cityscapes→ACDC
紧接着我们也在Cityscapes到ACDC这个任务上进行了消融实验。观察如图所示的结果可以发现,我们提出的可见度增强模块以及加入的逻辑值约束的学习方法,都能够取得可观的性能增益,这表明它们对我们方法以及最终模型性能都有着不可忽视的贡献,这证明了它们在这个方法中的必要性。

05
Confidence Distribution of
Trained Models
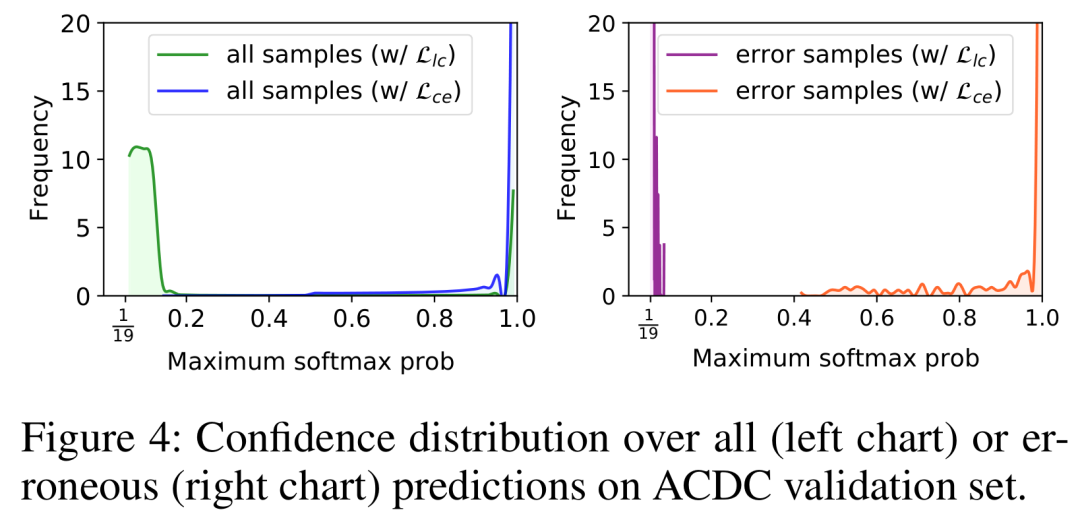
为了进一步探究逻辑值约束学习的效果,我们分别可视化了使用交叉熵损失函数以及我们提出的损失函数所训练出的模型,在ACDC的验证集上的就是最大softmax概率代表的置信度。在左图中交叉熵损失函数所训练出的模型,倾向于给出较高的预测概率,但是我们的模型则相对保守,不会做出过分高的置信度预测。结合右下图来看,交叉熵损失函数所训练的模型,如果给出了错误的预测,那么这些预测很有可能是处于高置信度的区域。但是我们的模型则不同,它给出的错误预测基本上都是在低置信度区域,这表明它没有那么容易犯错。这张图片对比下来,从实验上证明了逻辑值约束学习损失是应对overconfidence这一问题的一种有利的解决方案。
06
Loss Landscape
在下图中进一步展示了交叉熵损失函数以及我们的方法分别训练出来的模型,在ACDC的训练集上使用了真实标签以及交叉熵损失,所绘制的一张Loss Landscape,图中蓝色区域表示模型在这个区域上具有较小预测错误,整个Loss Landscape是通过对模型参数进行扰动所得到的。对比这张图片可以发现,我们的逻辑值约束方法,在提升预测质量方面具有较好的潜力。

07
Results Visualization
下图是我们的方法在ACDC验证集上可视化结果。对比这些方法可以发现,我们的VBLC方法在预测结果上更加清晰,也具有更高的准确度。

Conclusion
最后我们对这一工作的贡献进行总结:首先我们在不使用图像配对信息作为弱监督的前提下,尝试对一个更加实际和困难的恶劣天气下的领域自适应语义分割任务提出了解决方案;其次我们在训练框架的输入和输出两端进行增强,来取得更好的迁移性能,其中可见度增强模块在输入空间减小领域差异,而逻辑值约束学习则是在输出空间缓解了overconfidence的问题;最后我们通过实验验证了VBLC的有效性,并通过理论分析和实验验证探索这背后的原因。
提
醒
点击“阅读原文”可以查看回放哦!
活动推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
下一篇:【Linux】sudo指令