干货文稿|详解深度半监督学习
分享嘉宾 | 范越
文稿整理 | William
嘉宾介绍

Introduction to Semi-Supervised Learning
传统机器学习中的主流学习方法分为监督学习,无监督学习和半监督学习。这里存在一个是问题是为什么需要做半监督学习?
首先是希望减少标注成本,因为目前可以在很多现实场景中去获得大量的图片,那么需要标注的量和成本会几何增加。
第二个是目前对所有大规模的数据进行标注进而训练模型是不现实的,因此可以使用一种方法使得用未标注的数据进行性能提升。
Standard Semi-Supervised Learning
Pseudo-Labeling
这是一种伪标签方法,其核心思想是希望是自动对未标注的数据进行标注,这样可以当成标注数据去训练模型。
第一篇文章是2013年的Pseudo-Labeling:The Simple and Efficient Semi-Supervised Learning Method for DNNs。其核心公式如下:

公式里的X是一个data,它所产生的label是模型预测的所有类中的最有可能的类,这里下标直接取最大值作为它对应的类。这里一个比较重要的参数是阿尔法T,可认为是一个平衡参数,且随时间发生变化。在这篇文章中,阿尔法设置是从一个比较小的值,然后再逐渐增大,最后达到饱和。这是因为模型开始刚被初始化的时候,模型预测不是很准确,需要更多的从标签中学习。
第二篇文章叫做self-training with noisy Student improves imageNet classification。这里面有一个比较常用方法的核心思路是希望模型在学完之后去标注所有的label data,之后将这些标注过所有的label data和之前的label data混在一起,再去训练一个新的模型。训练得到的新模型认为是一个新teacher,去标注那些标注过的数据,这样重新标注之后再循环这个过程,以此来提高对应的模型性能。示意图如图1所示。

图1 self-training 示意图
这里关键的一点是一定要在训练student时候加noise,这是因为Self-training的过程很容易产生累计的问题,即一张图片的标签标错,就会在训练过程中进行不断地加强错误地标签,无法纠正。所以这里使用加噪声的方式,从某种意义上可以认为student model并没有在原始的数据集上学习,而是在经过一系列变换后地数据集上学习,虽然这两个数据之前存在很强地相关性,但是实际使用地数据并不完全一样,因此可以规避这个问题。
该模型的top-1和top-5准确率上的性能表现如图2所示。比如JFT这种300M规模的没有标注数据集例子,与big transfer相比,student training的性能更佳,而且此模型参数也会小一些。另外一方面,这篇方法是完全当作是未标注数据进行处理的,而big transfer还需要一些弱标注才可以进行处理。

图2 模型性能表现
Consistency Regularization
这种方法的思路是如果存在噪声使得两次输出并不完全一致,那希望对于不同噪声版本的目标能够产生同一个目标输出,即产生不变性。
第一篇工作是2017年的temporal ensembling for semi-supervised learning.模型如图3所示。该模型比较简单,有两个分支,首先把输入X分别做augmentation再进行dropout得到特征zi和zi杠。这实际来自同一个X,所以给它加上square difference,同时希望这两者feature之间的距离要尽量小label data这里是虚线,最后总loss是cross square difference之间的权重相加。

图3 t-model模型
第二篇工作也是在2017年的weight-averaged consistency targets improve semi-supervised deep learning results。它的改变在于是把X通过同一个网络,然后得到两个不同的输出,其中一个模型叫做student model,是进行不断的训练,得到一个预测结果。另外一个是teacher model,该模型每次在算consistency loss时,会产生第二个预测。最后进行计算classification loss 得到最终的预测结果。
第三篇文章是2020年的FixMatch:simplifying semi-supervised learning with consistency and confidence,如图4所示。首先对于未标注的图片分别进行weakly-augmented和strongly-augmented,分别生成预测结果,weakly-augmented的结果是直接softmax生成的,然后和strongly-augmented当成新的图像对去训练模型,计算损失并更新最后结果。

图4 FixMatch模型
该模型是整合并简化的之前模型,因为之前图3做squaredifferent的地方其实还是在feature层面去尽可能缩小差距。但在这里是直接从weakly-augmented的位置上去得到这张图片的标签,直接当作是真实标签去计算参数。所以loss就只有两部分,首先是在X上进行最简单的求导,第二部分是计算Y上进行求导计算,最后相加得到总损失。
性能表现如图5所示,使用CIFAR-10,CIFAR-100和SVHN数据集进行实验。对于每一个类,人工的对数据进行测试,比如这里先随机拿40,再250,再4000,再400进行测试,即每次实验均需要跑五次,最后得到平均的结果。总体来讲,该模型方法并不是在所有情况下都是最好的,但是一个competitive的方法,而且该方法的simlicity比较简单。

图5 模型性能对比
第四篇文章是去年的revisiting consistency regularization for semi-supervised learning,也是从consistency regulation角度进行了一些创新。这些图片里依旧是原始图片,weak augmentation 和strong augmentation处理的图片,如果遮住原始图片和weak augmentation处理后的图片,则可能并不能判断出strong augmentation的图片到底是哪一类,所以存在一个非常大的感官差异,如图6所示。
因此,实际操作中会让模型完全的对organization产生一个不变性并不是一个好事情,希望是在特征空间里依旧映射出两个不同的点,但是这两个点需要给出同样的class label。所以最后模型是把所有的预测都缩小到同一个点或一小片区域里面,这样它的整个space coverage比较小。

图6 图像增强
具体方法如图7所示,依旧是两个分支,上分支去做特征层面的不变性。下分支去保证这两个feature得到的class level是一样的,且必须必须是同时存在。然后顺着将特征空间里的特征进行分类并计算交叉熵损失。

图7 模型结构
实验部分依旧是CIFAR-10,CIFAR-100数据集,随机抽取标签数为4,25和400进行实验,在不同的设置下,比之前的方法均有所提升,如图8所示。

图8 模型性能表现
Realistic Semi-Supervised Learning
Imbalanced Semi-Supervised Learning
首先讲的这篇文章叫做CoSSL:co-learning of representation and classifier for imbalanced semi-supervised learning。由于现实中标记的和未标记的数据都是类不平衡的,因此会造成模型性能的不稳定。同时,目前的长尾分布数据识别和SSL方法都是对真实环境下的测试性能存在影响。
所以,这篇文章里提出了新的解决框架,具体如图9所示。由于之前已证明了长尾数据集对模型造成性能的影响主要出现在classified层,所以沿着此思路去看该模型结构。模型分成了三大模块,最上面是做representation learning,最下面是做classified。所以在训练的时候,要把最上层的encoder和最下层的classified拼接在一起去做test,因为上面输入的是好的input,下面输入的是好的test。对。中间部分是pseudo-label generation,是对data去产生一些label。
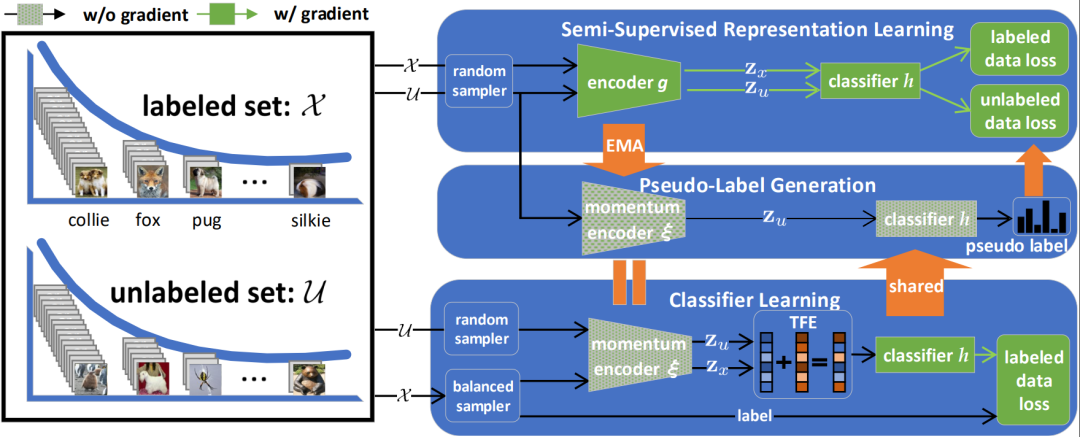
图9 模型结构
模型性能如图10所示,主要是在数据集CIFAR-100上的结果,这里的γ的值表示长尾分布的数量,γ越达则表明长尾分布问题越严重。可以看到随着γ指数增加,对比模型的性能均存在不同程度的下降,但本文模型的结果依旧能够有一个比较好的提升。

图10 模型性能对比
Open-Set Semi-Supervised Learning
在standard learning里面,如果只是关注的是bear和bird类,会确保label data以及unlabel data里面永远都只有这两个类。但往往在实际收集数据过程中,可能会不小心包含一些别的类,所以最终有了open-set learning。这样的情况下希望模型能够很好的区分这两类的情况下同时有能力去检测出哪些图片不是属于已知的两类。
这里只介绍一下2021年的OpenMatch:open-set consistency regularization for semi-supervised learning with outliers,该方法把这个问题理解为既要做检测也要做分类,所以直接将模型分为两个分支。一分支直接做分类,另外一分支做检测,如果是K分类,则判定是不是属于此类中一个。
具体在测试的时候,当输入一张新的图片,首先要给这一部分去预测一下它是哪一个类,如果是第三类,则找到对应的online,查看是否属于第三类,否则添加为新的类别。
具体在训练过程中的loss比较好理解,如果定义为二分类,从数据体上构建出one-vs-all (OVA)概率。如果是属于这一类,则提升输出权重,如果不是此类,则降低输出权重,得到一个损失。第二个损失是minilization,即对于label data的输出要尽量的是一个低状态。
性能比较如图11所示,由于此类任务是考虑检测和分类两个部分,还能够得到比之前方法更优越的结果。在这些方法上,如果class match逐渐增大,性能值会逐渐下降,是因为低于level的data。

图11 OpenMatch性能对比